python爬虫——模拟登录教务系统爬取成绩
主要思路
1.模拟登录到教务处,获取登录的cookie值,用获取到的cookie值,访问成绩的网址,分析成绩页面,获取成绩信息。
2.打包成exe文件,方便使用 ,我们可以用自己写的程序快速查询我们的成绩,速度要比正常登录教务处网址查询快很多,也比超级课程表查询快很多。
3.举一反三,我们可以采取同样的方法获取教务系统里面的其他信息(如学籍卡片,理论课表等),其操作流程基本相同。
首先,我们看一下教务系统的登录界面(本文使用火狐浏览器)
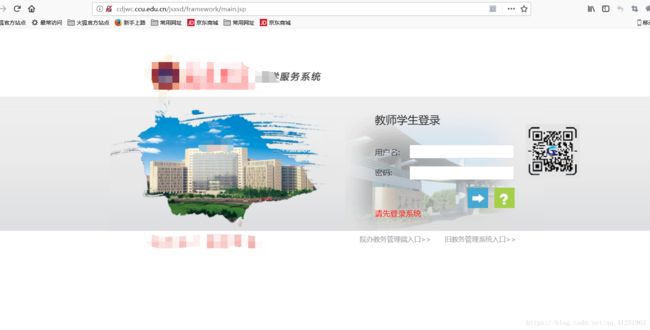
按F12进入开发者选项,选择网络,并输入用户名和密码进行登录

我们发现第一条即是我们提交(post)的表单数据,我们点开后,会在右面消息头里找到我们的请求网址http://cdjwc.ccu.edu.cn/jsxsd/xk/LoginToXk

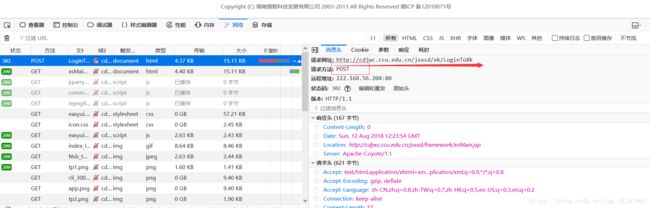
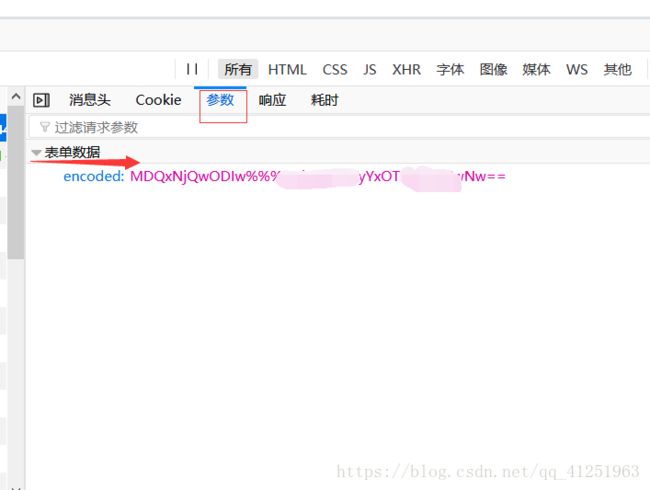
接下来找要提交的数据,找到参数,我们发现表单数据。但数据与我们平时看到的表单数据不一样。这是经过base64加密的数据。我们可以通过https://base64.supfree.net/,查看BASE64的加密解密。不难发现,这条表单数据正式用这种方法进行加密的。那么数据加密了,我们该怎么办呢?。由于我们使用的语言是python,这给我们带来了很大的方便,python中base64库专门用来base64的加密。
既然我们解决了这个问题,那么我们就可以模拟登录了。
##模拟登陆的代码
import requests
import base64
username = input("请输入账号:")
password = input("请输入密码:")
jiema = username + password#解码
encodestr = str(base64.b64encode(jiema.encode('utf-8')), 'utf-8')
print(encodestr)
encoded = encodestr[0:12] + '%%%' + encodestr[12:]#写成表单数据的格式,将账号与密码用%%%分开
print(encoded)
login_url = 'http://cdjwc.ccu.edu.cn/jsxsd/xk/LoginToXk'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Connection':
'keep-alive'
}
data = {'encoded': encoded}
html=requests.post(url=login_url,headers=headers,data=data)
print(html.text)
登陆后,我们可以看到首页的信息。这说明我们对表单数据的处理是正确的。接下来,我们要获取到cookie值。requests.session()requests模块中的session()方法能够获取到cookie值。
session=requests.session()
html=session.post(url=login_url,headers=headers,data=data)
cookies=requests.utils.dict_from_cookiejar(session.cookies)
print(cookies)
这样我们就可以获取到cookie值了,获取到的是一个字典。既然cookie值已经获取到了,我们暂时放在这。接下来分析成绩查询的页面。
我们在开发者选项下,找到成绩页面,同样,我们发现第一条就是我们要抓的数据。
我们找到了请求的网址,接下来找到要提交的数据,同样在参数中寻找。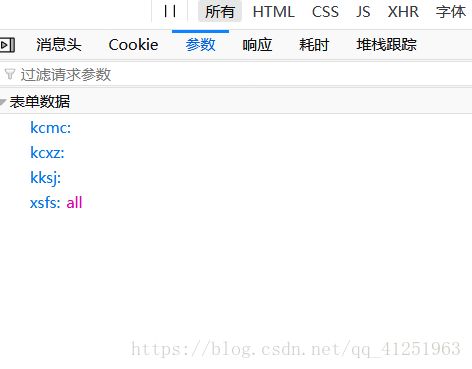
既然数据找到了,那么我们就可以请求这个页面了,但是怎么将cookie值传入呢?我们发现cookie在请求头headers中,为了方便有效,我们干脆把下面请求头的内容全部复制到代码中,将cookie换成我们上文中模拟登陆拿到的即可。

Host: cdjwc.ccu.edu.cn
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:61.0) Gecko/20100101 Firefox/61.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Referer: http://cdjwc.ccu.edu.cn/jsxsd/kscj/cjcx_query?Ves632DSdyV=NEW_XSD_XJCJ
Content-Type: application/x-www-form-urlencoded
Content-Length: 26
Cookie: _gscu_752261578=217071781ip13z15; _gscbrs_752261578=1; JSESSIONID=52E0451173A7556EAB6ED1498AB75B69#这里面换掉
Connection: keep-alive
Upgrade-Insecure-Requests: 1
###进行测试,看能否获取到成绩页面的信息
import requests
import base64
import re
from bs4 import BeautifulSoup
from urllib import request
from http import cookiejar
username = input("请输入账号:")
password = input("请输入密码:")
jiema = username + password#解码
encodestr = str(base64.b64encode(jiema.encode('utf-8')), 'utf-8')
print(encodestr)
encoded = encodestr[0:12] + '%%%' + encodestr[12:]#写成表单数据的格式,将账号与密码用%%%分开
print(encoded)
login_url = 'http://cdjwc.ccu.edu.cn/jsxsd/xk/LoginToXk'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Connection':
'keep-alive'
}
data = {'encoded': encoded}
session = requests.session()
#html=requests.post(url=login_url,headers=headers,data=data)
html = session.post(url=login_url, headers=headers, data=data)
cookies = requests.utils.dict_from_cookiejar(session.cookies)
#print(cookies)
a = cookies['JSESSIONID']
#print(a)
#print(html.text)
info = re.findall(
'',
html.text)
if len(info) > 0:
name = info[0]
if name:
print('******************')
print(name)
print('******************')
print("正在查询,请稍后")
url_grade = 'http://cdjwc.ccu.edu.cn/jsxsd/kscj/cjcx_list'
data2 = {
'kcmc': '',
'kcxz': '',
'kksj': '',
'xsfs': 'all',
}
headers = {
'Accept':
'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding':
'gzip, deflate',
'Accept-Language':
'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control':
'max-age=0',
'Connection':
'keep-alive',
'Content-Length':
'26',
'Cookie':
'JSESSIONID=' + a,
'Content-Type':
'application/x-www-form-urlencoded',
'Host':
'cdjwc.ccu.edu.cn',
'Referer':
'http://cdjwc.ccu.edu.cn/jsxsd/kscj/cjcx_query?Ves632DSdyV=NEW_XSD_XJCJ',
'Upgrade-Insecure-Requests':
'1',
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:59.0) Gecko/20100101 Firefox/59.0}',
}
html2 = requests.post(url_grade, data=data2, headers=headers)
print(html2.text)
通过打印html2.text,我们可以知道,已经能够顺利的获取到成绩页面信息了。我们已经完成大多数了,接下来只需在html2中将想要的科目信息及成绩信息提取出来即可,这里可以使用正则表达式。我是使用BeautifulSoup,这样获取也许会方便一些吧。
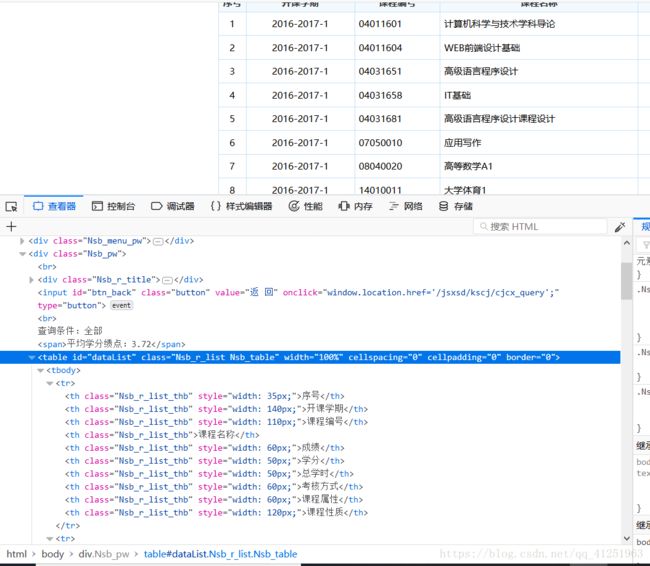
我们想要的内容,都在id=“dataList” 的table标签下。确切的说是除了第一个外的所有tr标签下,这样我们稍作处理就能获取所有的成绩信息了。
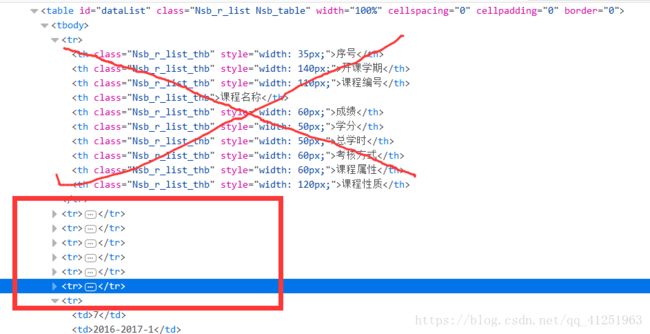
#完整代码
import requests
import base64
import re
from bs4 import BeautifulSoup
from urllib import request
from http import cookiejar
print('\n')
print("不用教务系统也能直接查成绩了!!!")
print('\n')
print('****************************')
username=input("请输入账号:")
password=input("请输入密码:")
jiema=username+password
encodestr =str( base64.b64encode(jiema.encode('utf-8')),'utf-8')
#print(encodestr)
encoded=encodestr[0:12]+'%%%'+encodestr[12:]
#print(encoded)
login_url='http://cdjwc.ccu.edu.cn/jsxsd/xk/LoginToXk'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Connection': 'keep-alive'
}
data={
'encoded':encoded
}
session=requests.session()
#html=requests.post(url=login_url,headers=headers,data=data)
html=session.post(url=login_url,headers=headers,data=data)
cookies=requests.utils.dict_from_cookiejar(session.cookies)
#print(cookies)
a=cookies['JSESSIONID']
#print(a)
#print(html.text)
info=re.findall('',html.text)#找到登录着的姓名及学号
if len(info)>0:#如果存在,继续操作,如果不存在,则说明登陆失败,需重新登陆。
name=info[0]
if name:
print('******************')
print(name)
print('******************')
print("正在查询,请稍后")
print('******************')
url_grade = 'http://cdjwc.ccu.edu.cn/jsxsd/kscj/cjcx_list'
data2 = {'kcmc': '',
'kcxz': '',
'kksj': '',
'xsfs': 'all',
}
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Content-Length': '26',
'Cookie':'JSESSIONID='+a,
'Content-Type':'application/x-www-form-urlencoded',
'Host': 'cdjwc.ccu.edu.cn',
'Referer': 'http://cdjwc.ccu.edu.cn/jsxsd/kscj/cjcx_query?Ves632DSdyV=NEW_XSD_XJCJ',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:59.0) Gecko/20100101 Firefox/59.0}',}
html2=requests.post(url_grade,data=data2,headers=headers)
#print(html2.text)
soup = BeautifulSoup(html2.text, 'lxml')#创建soup对象
table = soup.select("#dataList")[0]
tr = table.find_all('tr')[1:]
for i in tr:
subject = i.find_all('td', align="left")[1::2][0].text
score = i.find('a').text
print(subject + '--------------' + score)
print('******************')
input("输入回车键退出查询")
else:
print('账号或密码错误,请重新输入!!')
输入密码不可见使用getpass模块!
import requests
import base64
import re
from bs4 import BeautifulSoup
import getpass
print('\n')
print("不用教务系统也能直接查成绩了!!!")
print('\n')
print('****************************')
username=input("请输入账号:")
password=getpass.getpass("请输入密码:")
jiema=username+password
encodestr =str( base64.b64encode(jiema.encode('utf-8')),'utf-8')
encoded=encodestr[0:12]+'%%%'+encodestr[12:]
login_url='http://cdjwc.ccu.edu.cn/jsxsd/xk/LoginToXk'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Connection': 'keep-alive'
}
data={
'encoded':encoded
}
session=requests.session()
html=session.post(url=login_url,headers=headers,data=data)
cookies=requests.utils.dict_from_cookiejar(session.cookies)
a=cookies['JSESSIONID']
#print(a)
info=re.findall('',html.text)
if len(info)>0:
name=info[0]
if name:
print('******************')
print(name)
print('******************')
print("正在查询,请稍后")
url_grade = 'http://cdjwc.ccu.edu.cn/jsxsd/kscj/cjcx_list'
data2 = {'kcmc': '',
'kcxz': '',
'kksj': '',
'xsfs': 'all',
}
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Content-Length': '26',
'Cookie':'JSESSIONID='+a,
'Content-Type':'application/x-www-form-urlencoded',
'Host': 'cdjwc.ccu.edu.cn',
'Referer': 'http://cdjwc.ccu.edu.cn/jsxsd/kscj/cjcx_query?Ves632DSdyV=NEW_XSD_XJCJ',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:59.0) Gecko/20100101 Firefox/59.0}',}
html2=requests.post(url_grade,data=data2,headers=headers)
soup = BeautifulSoup(html2.text, 'lxml')#创建soup对象
table = soup.select("#dataList")[0]
tr = table.find_all('tr')[1:]
for i in tr:
subject = i.find_all('td', align="left")[1::2][0].text
score = i.find('a').text
print(subject + '--------------' + score)
print('******************')
input("输入回车键退出查询")
else:
print('账号或密码错误,请重新输入!!')
打包成可执行程序:
在cmd中进入程序所在文件目录,执行
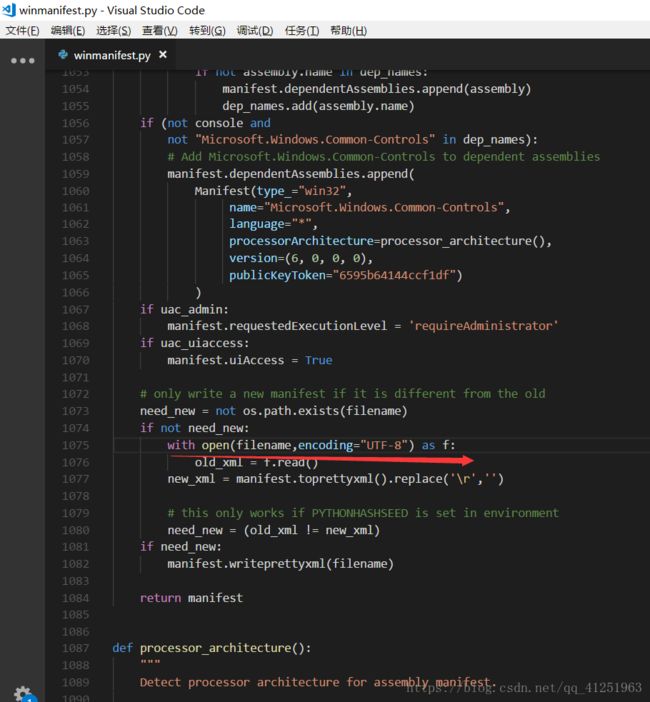
pyinstaller 文件名.py -F
即可打包。如果打包过程出现编码错误,找到最后一个报错所在的文件,将with open(filename)as f: 改成with open(filename,encoding=“UTF-8”)as f:(我的是在C:\ProgramData\Anaconda3\Lib\site-packages\PyInstaller\utils\win32下的winmanifest.py文件,1075行)即可。重新执行pyinstaller 文件名.py -F