




1¡¢½«Äã·Å½øÎÒÐÄÀï×îÖØÒªµÄλÖã¬ÓÃÐÄÀ´¿ÌÄãµÄÃû×Ö¡£
2¡¢°®ÊÇ̤Æƺ쳾Íû´©ÇïË®£»°®ÊÇÒ»ÉúÒ»ÊÀÚ¤Ú¤Âֻأ»°®Ä㣬ÎÒ²»ÎÊÀíÓÉ¡£
3¡¢×§ÄãÈ뻳£¬ÓèÄãÒ»ÊÀÏà°é£¬ÓµÄãÈ뻳£¬»¤ÄãÒ»ÊÀƽ°²¡£
4¡¢ºÎÖ¹ÊÇÒ°ÐÄ£¬ÎÒԤıÁËÒ»±²×ÓµÄÄîÏ룬´ÓÓö¼ûÄ㿪ʼ£¬²»¼û»ÆÍÁ²»ËÀÐÄ¡£
5¡¢ÎÒºóÀ´ÏëÁËÏ룬ÎÒ²»µ¢ÎóÄ㣬»¹»áÓбðÈ˵¢ÎóÄ㣬ÄÇÎÒ²»¸ÊÐÄ£¬»¹ÊÇÎÒÀ´µ¢ÎóÄã°É¡£
6¡¢¼ûµ½ÄãµÄÄÇÒ»¿ÌÎҾͲ»ÖªËù´ë£¬ÓеÄÖ»ÊǵÄÐÄÌø£¬ÊÇÄã¸Ä±äÁËÎÒ£¬ÒÔÇ°ÎÒ´Ó²»»áÕâÑùµÄ¡£¼ÙÈçÓÐÒ»¸öÈËÄÜÈÃÎÒÐĸÊÇéÔ¸µØ¸Ä±äÄǾÍÊÇÄã¡£
7¡¢ÅãÎÒµ½¿É¿ÉÎ÷ÀïÈ¥¿´º£²»ÒªÎ´À´Ö»ÒªÄãÀ´¡£
8¡¢Ã¿Ò»Ì춼ΪÄãÐÄÌø£¬Ã¿Ò»¿Ì¶¼±»Äã¸Ð¶¯£¬Ã¿Ò»Ã붼ΪÄãµ£ÐÄ¡£ÓÐÄãµÄ¸Ð¾õÕæºÃ¡£
9¡¢²»¸ÒÔÙÌýÇé¸è£¬µ±ÎÒ¸öÈË£¬ÒòΪÑÛÀáÖ¹²»×¡¡£
......小问号,你是否有很多朋友?
我们爬下来的都是乱码,那还玩个卵子,发给女神一堆乱码,女神可能还会以为是我们给她发的暗语,说不定还要花时间去寻找解密方法,想想都累,不能这个样子!
其实出现乱码的原因主要网页的编码方式和我们爬取程序的编码方式不一样造成的,只要找到网页的编码方式就好。
2.3.3. 设置解码类型
有3种方式:
1.从网页Content-Type中获取编码方式
2.第三方库智能识别编码,常用chardet等
3.猜测编码
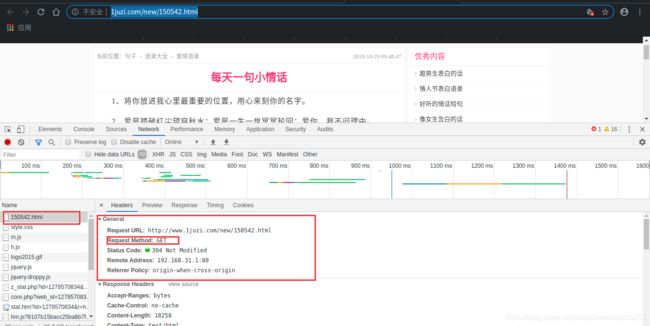
我们这里其实在请求头的Content-Type里有编码类型,但是为了保险起见,也是为了能应用到更多的资源网站,这里演示以下chardet的用法,猜测编码的使用请自行百度。
chardet获取编码类型
代码:
import urllib.request
import chardet
url = "http://www.1juzi.com/new/150542.html"
html = urllib.request.urlopen(url).read()
print("html头中的charset:", chardet.detect(html))
结果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/spider/Spider.py
html头中的charset: {'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}
Process finished with exit code 0
Get!!! 编码方式为GB2312!
设置解码
代码:
import urllib.request
import chardet
url = "http://www.1juzi.com/new/150542.html"
html = urllib.request.urlopen(url).read()
charset = chardet.detect(html).get("encoding")
htmlText = html.decode(charset,errors = 'ignore')
print(htmlText)
结果:
......
每天一句小情话
1、将你放进我心里最重要的位置,用心来刻你的名字。
2、爱是踏破红尘望穿秋水;爱是一生一世冥冥轮回;爱你,我不问理由。
3、拽你入怀,予你一世相伴,拥你入怀,护你一世平安。
4、何止是野心,我预谋了一辈子的念想,从遇见你开始,不见黄土不死心。
5、我后来想了想,我不耽误你,还会有别人耽误你,那我不甘心,还是我来耽误你吧。
6、见到你的那一刻我就不知所措,有的只是的心跳,是你改变了我,以前我从不会这样的。假如有一个人能让我心甘情愿地改变那就是你。
7、陪我到可可西里去看海不要未来只要你来。
8、每一天都为你心跳,每一刻都被你感动,每一秒都为你担心。有你的感觉真好。
......
哦吼!搞定!
2.3.4. 封装代码
刚才我们已经实现了资源的获取,但是这样的代码用起来太不方便了,我们把它封装在方法里
import urllib.request
import chardet
def getHtml(url):
"""
获取网页html文本资源
:param url: 网页链接
:return: 网页文本资源
"""
html = urllib.request.urlopen(url).read()
charset = chardet.detect(html).get("encoding")
htmlText = html.decode(charset, errors='ignore')
return htmlText
2.4. 解析网页资源
解析网页的话,需要第三方插件Beautiful Soup来提取 xml 和 HTML 中的数据。
2.4.1. 安装
自行百度
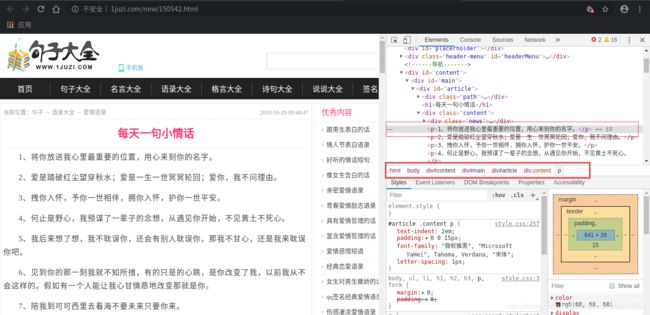
2.4.2. 获取content节点内容
我们想要的资源都在一个class为”content“的div节点下,我们现在先获取这个节点的所有内容。
部分代码:
soup = BeautifulSoup(htmlText,"html.parser")
"获取content节点的内容"
div_node = soup.find('div', class_='content')
print(div_node.get_text)
结果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/spider/Spider.py
1、将你放进我心里最重要的位置,用心来刻你的名字。
2、爱是踏破红尘望穿秋水;爱是一生一世冥冥轮回;爱你,我不问理由。
3、拽你入怀,予你一世相伴,拥你入怀,护你一世平安。
4、何止是野心,我预谋了一辈子的念想,从遇见你开始,不见黄土不死心。
5、我后来想了想,我不耽误你,还会有别人耽误你,那我不甘心,还是我来耽误你吧。
......
本文地址:每天一句小情话http://www.1juzi.com/new/150542.html
上一页12下一页
>
Process finished with exit code 0
2.4.3. 获取p节点内容
上一步我们已经获取到了我们的主要内容,然后总结可以看出我们想要的文本内容在P节点中,那么现在就来获取它
部分代码:
soup = BeautifulSoup(htmlText,"html.parser")
"获取div节点的内容"
div_node = soup.find('div', class_='content')
"获取P节点内容"
p_node = div_node.find_all('p')
for content in p_node:
print(content.get_text())
结果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/spider/Spider.py
1、将你放进我心里最重要的位置,用心来刻你的名字。
2、爱是踏破红尘望穿秋水;爱是一生一世冥冥轮回;爱你,我不问理由。
3、拽你入怀,予你一世相伴,拥你入怀,护你一世平安。
4、何止是野心,我预谋了一辈子的念想,从遇见你开始,不见黄土不死心。
5、我后来想了想,我不耽误你,还会有别人耽误你,那我不甘心,还是我来耽误你吧。
......
69、有时,爱也是种伤害,残忍的人句子大全http://Www.1juzI.coM/,选择伤害别人,善良的人,选择伤害自己。
......
Process finished with exit code 0
2.4.4 处理数据
注意一下第69剧,这里面有网站的链接,把这个一起发给女神不就露馅了么,现在得想办法给她删掉。同时情话前面的编号也得删掉。
删除特定标签
我们会查看一下数据就会发现,所有的链接都是在U标签里的,那我们可以直接在获取到div标签内容后就把u标签删掉
"删除特定标签u"
[s.extract() for s in div_node('u')]
删除序号
我们发现,序号与情话之间是用顿号分割的,那么我们可以将每个P标签下的内容用split分割并且取出第二个元素就好了。
部分代码:
"获取P节点内容"
p_node = div_node.find_all('p')
for content in p_node:
"以’、‘分割,并且取出第2个元素"
text = content.get_text().split("、",1)[1]
print(text)
结果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/spider/Spider.py
将你放进我心里最重要的位置,用心来刻你的名字。
爱是踏破红尘望穿秋水;爱是一生一世冥冥轮回;爱你,我不问理由。
拽你入怀,予你一世相伴,拥你入怀,护你一世平安。
何止是野心,我预谋了一辈子的念想,从遇见你开始,不见黄土不死心。
我后来想了想,我不耽误你,还会有别人耽误你,那我不甘心,还是我来耽误你吧。
......
Process finished with exit code 0
nice啊,到这一步你已经把我们需要的情话都提取出来了!!!
封装数据备用
这样一句一句的也不好处理啊!不如把它放到list里,等下定时任务的时候可以用的时候取出来就好。
部分代码:
sentenceList = list()
......
"获取P节点内容"
p_node = div_node.find_all('p')
for content in p_node:
"以’、‘分割,并且取出第2个元素"
text = content.get_text().split("、", 1)[1]
"追加到list尾部"
sentenceList.append(text)
print(sentenceList):
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/spider/Spider.py
['将你放进我心里最重要的位置,用心来刻你的名字。', '爱是踏破红尘望穿秋水;爱是一生一世冥冥轮回;爱你,我不问理由。', '拽你入怀,予你一世相伴,拥你入怀,护你一世平安。', '何止是野心,我预谋了一辈子的念想,从遇见你开始,不见黄土不死心。', ......]
Process finished with exit code 0
2.4.5. 封装(爬虫代码最终)
爬虫是做好了,但是总觉得乖乖的,我等下还得在其他地方用,不如这里以面向对象的思想把爬虫封装一下。
import urllib.request
from bs4 import BeautifulSoup
import chardet
def __getHtml(url):
"""
私有方法:获取网页html文本资源
:param url: 网页链接
:return: 网页文本资源
"""
html = urllib.request.urlopen(url).read()
charset = chardet.detect(html).get("encoding")
htmlText = html.decode(charset, errors='ignore')
return htmlText
def __sloveHtml(htmlText):
"""
私有方法:解析HtmlText
:param htmlText: 传入的资源
"""
sentenceList = list()
soup = BeautifulSoup(htmlText, "html.parser")
"获取content节点的内容"
div_node = soup.find('div', class_='content')
"删除特定标签u"
[s.extract() for s in div_node('u')]
"获取P节点内容"
p_node = div_node.find_all('p')
for content in p_node:
"以’、‘分割,并且取出第2个元素"
text = content.get_text().split("、", 1)[1]
"追加到list尾部"
sentenceList.append(text)
return sentenceList
def getSentenceList(url):
"""
Spider提供的公用方法,提供情话list
:param url: 获取情话的地址
:return: 情话list
"""
return __sloveHtml(__getHtml(url))
2.5. 爬虫总结
这一部分主要用到的类库有:BeautifulSoup,urllib,chardet
主要思想:封装
3. 手机短信发送发送
本来想用微信或者QQ发送来着,但是时隔两年,qqbot,itchat,wxpy等第三方库都失效了,没办法就来用手机短信发送好了

这里是一段防爬虫文本,读者请忽略。
本文最先由Baldwin_Keepmind发表于CSDN,转载请注明出处。
作者博客地址:https://blog.csdn.net/shouchenchuan5253
3.1. twilio
Twilio是一个做成开放插件的电话跟踪服务(call-tracking service)
Twilio公司致力于帮助开发者在其应用里融入电话、短信等功能,该公司周二又推出了一项称为Twilio Client的新服务,可帮助开发者整合灵活而低成本的网络电话(VoIP)功能。
VoIP即Skype和谷歌电话等服务使用的技术,要提供VoIP服务通常需要准备相应的基础设备,而Twilio Client免除了开发者的这一麻烦,可让他们便捷地在应用里加入网络电话元素。
官网地址
3.1.1 安装
安装过程比较简单,直接pip就好
sudo pip3 install twilio
等待安装完成
Successfully built twilio
Installing collected packages: PyJWT, twilio
Successfully installed PyJWT-1.7.1 twilio-6.38.1
3.1.2. 注册并获取三个重要参数
参考文章:https://zhuanlan.zhihu.com/p/67716042
3.1.3. 简单代码实现发送短信实验
代码:
from twilio.rest import Client # 导包
account_sid = '你的account_sid'
auth_token = '你的auth_token'
client = Client(account_sid, auth_token)
message = client.messages.create(
from_='+×××××××××',
body='亲爱的H,以后我每天都会给你发送一条信息哦!!!',
to='你要发送到的手机号(以+86开头)'
)
print(message.sid)
控制台输出:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/qqsend/Send.py
SMfe64f40f2ac24b8ca82121d57147312c
Process finished with exit code 0
手机接收短信:
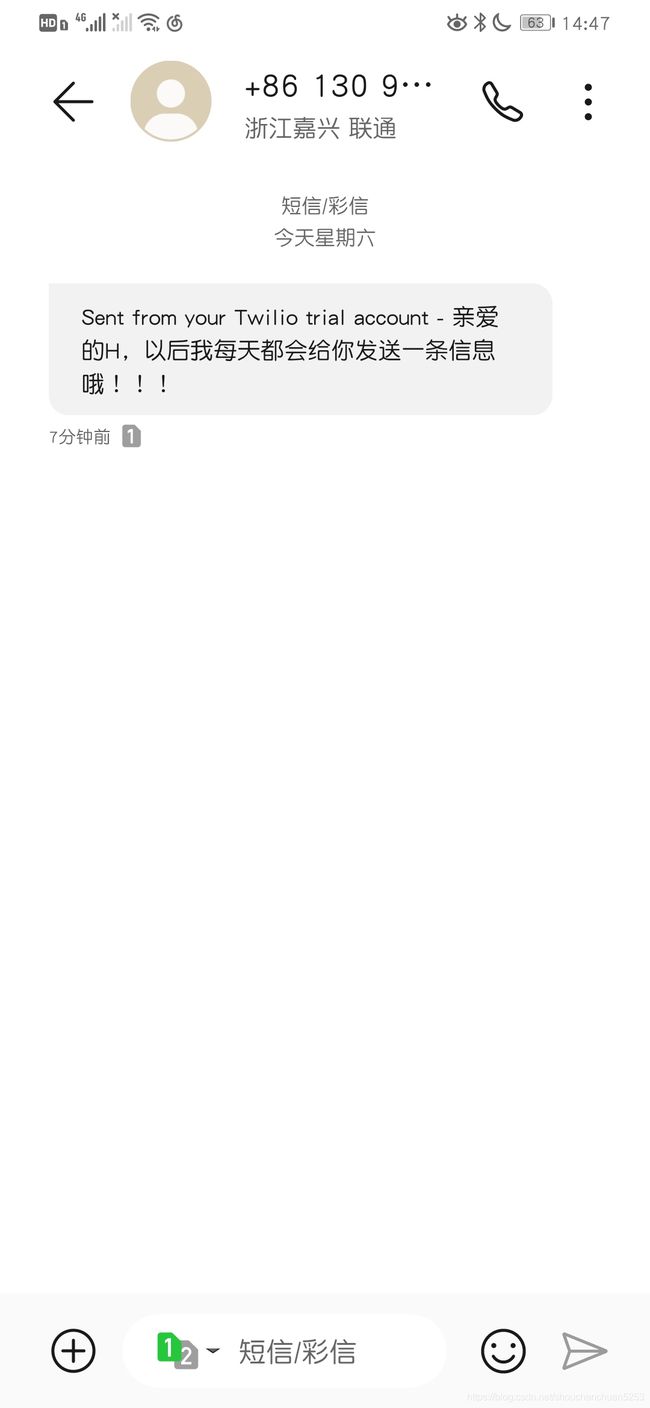
OK!到这里我们已经简单实现了发送短信的功能,现在要去把这个功能封装一下。
3.2. 实现发送短信的功能
封装代码:
from twilio.rest import Client # 导包
def sendSMSMsg(content, tel):
"""
向某个手机号发送短信内容
:param content: 短信内容
:param tel: 手机号
"""
account_sid = '你的account_sid'
auth_token = '你的auth_token'
client = Client(account_sid, auth_token)
client.messages.create(
from_='+18634171608',
body=content,
to=tel
)
print('Send :', content, 'to tel:', tel, 'syccessfully!!!')
if __name__ == '__main__':
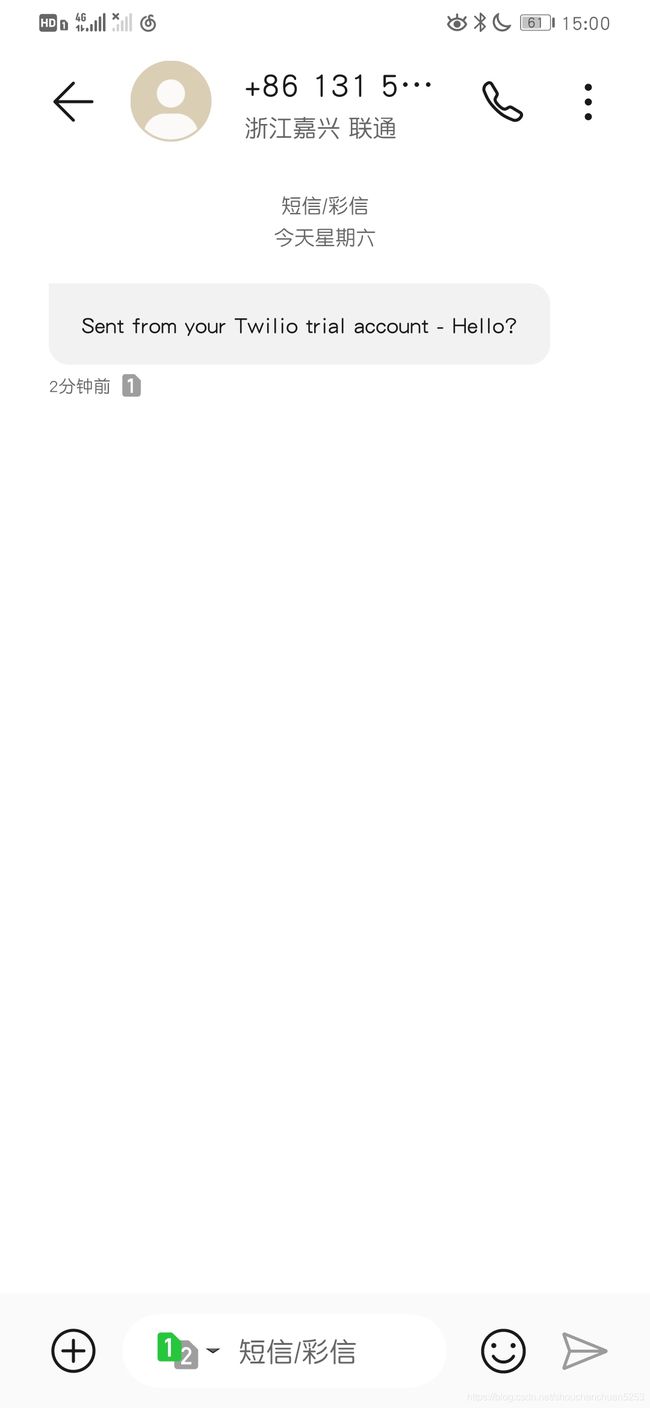
sendSMSMsg("Hello?" ,"+×××××××××")
测试结果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/qqsend/Send.py
Send : Hello? to tel: +8618436354553 syccessfully!!!
Process finished with exit code 0
手机接收短信:
3.3. 发送短信总结
注册twilio
获取三个参数:account_sid,auth_token,TRIAL NUMBER
引入twilio
设置你要发送到的手机号和内容
操作还算是比较简单的。
这部分主要用到twilio库
这里是一段防爬虫文本,读者请忽略。
本文最先由Baldwin_Keepmind发表于CSDN,转载请注明出处。
作者博客地址:https://blog.csdn.net/shouchenchuan5253
4. 定时发送短信
这一步算是我们的主程序了,在这一部分里,我们要使用之前的代码先获取情话list,再设置定时任务,每天固定的时间点把短信发到女神手机上。
4.1. Python定时任务
Python 中的定时任务框架还挺多的,我们现在的需求是每天早上8点钟执行一个任务,在不到这个时间的时候不发送信息,为了简便理解,我打算直接循环扫描系统当前时间,如果到了我们需要的那个时间点,就发送,不到的时候就一直扫描
4.1.1. 代码实现
代码:
import time
while True:
# 刷新
time_now = time.strftime("%H:%M:%S", time.localtime())
# 此处设置每天定时的时间
if time_now == "15:29:00":
# 需要执行的动作
print('定时任务执行一次')
time.sleep(2) # 因为以秒定时,所以暂停2秒,使之不会在1秒内执行多次
结果:
/usr/bin/python3.7 /home/baldwin/PycharmProjects/IAmADog/DoWork.py
定时任务执行一次
Traceback (most recent call last):
File "/home/baldwin/PycharmProjects/IAmADog/DoWork.py", line 7, in
time_now = time.strftime("%H:%M:%S", time.localtime())
KeyboardInterrupt
Process finished with exit code 1
我是15:28:00的时候运行程序的,在设置时刻确实是执行了程序。
下面的异常是因为我手动退出了程序,这里不用管他。
4.2. 具体实现发送情话
4.2.1. 具体需求整理
我们这里整理一下具体需求:
1.定时间点发送(上面已经实现了)
2.每次发送的时候从list中取出一个句子,下一次取出下一条,不能重复
3.list中的句子发送完毕之后要发短信通知我
4.2.2. 取句子
思路:设置一个全局变量index,代表着下一条要发送的句子的下标,每次发送短信后,下标要增加1
4.2.3. 发送完毕通知管理员
思路:每次进入任务但是发送短信之前都要比较index的值与list的长度(现在想起来,设计程序的时候用栈来储存数据会更好),如果index已经越界,直接给管理员发短信通知。
4.2.4. 实现
from spider import Spider
from send import Send
import time
TIME_TO_DO = '08:30:00' # 发送时间点
MSG_SUFFIX = '\n来自你的小可爱——Baldwin' # 短信后缀
SOURCE_URL = 'http://www.1juzi.com/new/150542.html' # 情话资源地址
SEND_TO_TEL = '+8618436354553' # 女神的手机号
SEND_TO_ME = '舔狗,给女神发的短信已经用光了,快来更新!!!'
MY_TEL = '+8618436354553' # 舔狗手机号
index = 0 # 下一条短信的下标
sentenceList = Spider.getSentenceList(SOURCE_URL) # 情话列表
while True:
# 刷新
time_now = time.strftime("%H:%M:%S", time.localtime())
# 此处设置每天定时的时间
if time_now == TIME_TO_DO:
# 需要执行的动作
# 判断当前list有没有用光
if index >= len(sentenceList):
# 用光了就短信通知我
Send.sendSMSMsg(SEND_TO_ME, MY_TEL)
# 跳出
break
# 给女神发短信
content = sentenceList[index] + MSG_SUFFIX
Send.sendSMSMsg(content, SEND_TO_TEL)
# 下标加一
index += 1
# 因为以秒定时,所以暂停2秒,使之不会在1秒内执行多次
time.sleep(2)
4.2.5. debug模式下的各项测试
短信发送测试
在idea debug模式下可以对time_now参数进行设置,把它设置成我们在前面要发送短信的那个时间点,成功进行了短信发送
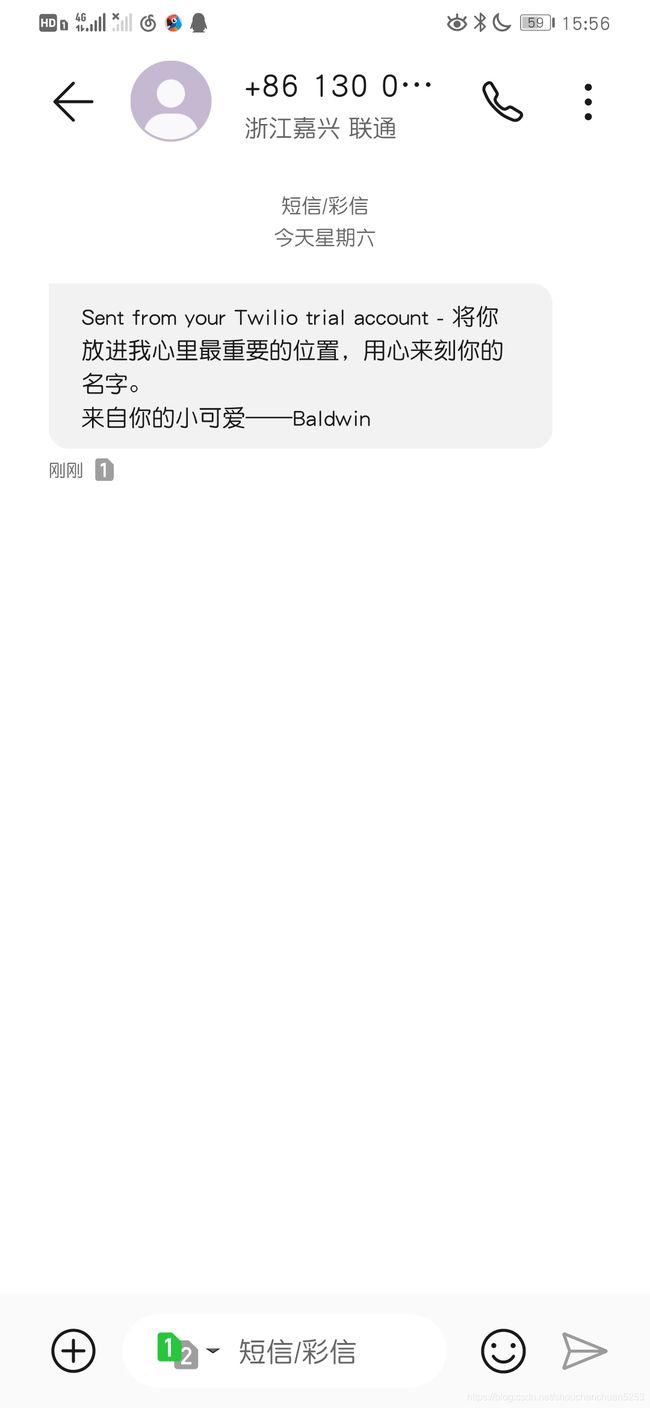
管理员通知测试
同样的在debug模式下,设置index的值为len(sentenceList),程序进入通知管理员模块中,这里不再演示。
4.3. 封装
from spider import Spider
from send import Send
import time
TIME_TO_DO = '08:30:00' # 发送时间点
MSG_SUFFIX = '\n来自你的小可爱——Baldwin' # 短信后缀
SOURCE_URL = 'http://www.1juzi.com/new/150542.html' # 情话资源地址
SEND_TO_TEL = '+8618436354553' # 女神的手机号
SEND_TO_ME = '舔狗,给女神发的短信已经用光了,快来更新!!!'
MY_TEL = '+8618436354553' # 舔狗手机号
def doSend():
index = 0 # 下一条短信的下标
sentenceList = Spider.getSentenceList(SOURCE_URL) # 情话列表
while True:
# 刷新
time_now = time.strftime("%H:%M:%S", time.localtime())
# 此处设置每天定时的时间
if time_now == TIME_TO_DO:
# 需要执行的动作
# 判断当前list有没有用光
if index >= len(sentenceList):
# 用光了就短信通知我
Send.sendSMSMsg(SEND_TO_ME, MY_TEL)
# 跳出
break
# 给女神发短信
content = sentenceList[index] + MSG_SUFFIX
Send.sendSMSMsg(content, SEND_TO_TEL)
# 下标加一
index += 1
# 因为以秒定时,所以暂停2秒,使之不会在1秒内执行多次
time.sleep(2)
# 主程序入口
if __name__ == '__main__':
doSend()
4.4. 小总结
这部分主要用到的模块:time,然后记得要把前两个我们自己做的模块导入进来。
悠着点玩,容易被封
这里是一段防爬虫文本,读者请忽略。
本文最先由Baldwin_Keepmind发表于CSDN,转载请注明出处。
作者博客地址:https://blog.csdn.net/shouchenchuan5253
5. 总结
项目地址
这个程序相对来说还算是比较容易的,只要跟着文章一步步来基本上不互出问题。
最后只要运行我们最后一个模块中主程序入口就好了,你也可以按照自己需求修改配置达到不同的效果。
我现在就去告诉女神去。
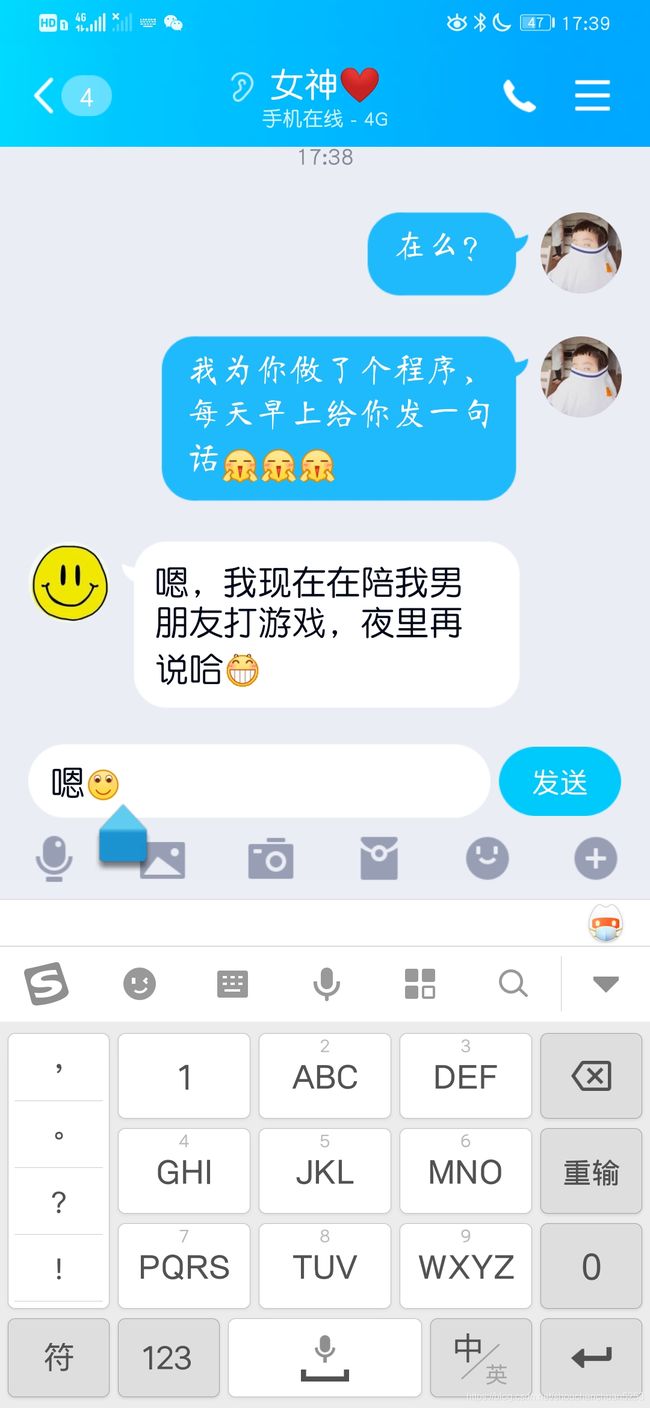
嘿嘿!女神秒回的,开心!
未经作者许可,严禁转载本文
我是Baldwin,一个25岁的程序员,致力于让学习变得更有趣,如果你也真正喜爱编程,真诚的希望与你交个朋友,一起在编程的海洋里徜徉!
往期好文:
MySQL优化之explain
Spring源码分析-MVC初始化
春风得意马蹄疾,一文看尽(JVM)虚拟机
造轮子的艺术
源码阅读技巧
Java注解详解
教你自建SpringBoot服务器
更多文章请点击