python3强智教务系统个人课表爬虫
前言
之前写过一篇用webdriver爬取教务系统课表的爬虫,用的是selenium自动化的无头浏览器模拟登录,今天带来的是用requests请求实现的爬虫。
工具
requests库实现对网页的请求,execjs库实现是js脚本的执行,bs4对爬取的数据进行清洗,csv库实现对数据的储存。
步骤
①首先是登录获取会话(session)
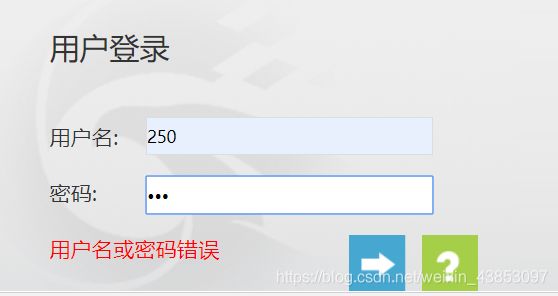
先在输入框乱输入,按F12,登录获取登录页面的表单信息格式
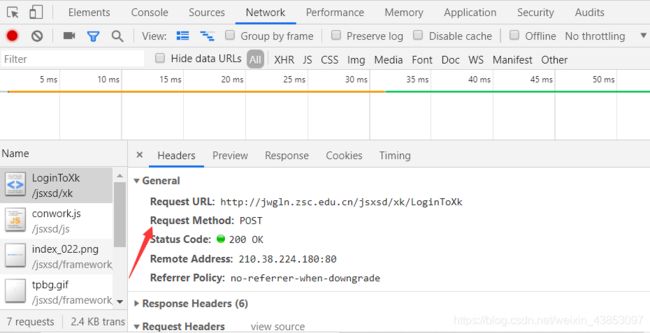

发现是POST请求,表单为加密过的,此时查看页面源代码,检查是如何加密的

再往下看到js,发现是根据encodeInp()进行加密的

再次检查页面源代码并没有发现此函数,那就只能是存在JS文件里面的
![]()
虽然后来发现是Base64加密方式,但是没关系了,用python的execjs来执行加密,记得将conwork.js下载下来放在跟python文件的同个目录
request请求后获取会话,准备到目的网页进行数据爬取
def get_js(self, msg): # python 调用JS加密 返回 加密后的结果
with open('conwork.js', encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('encodeInp', msg)
def login_requests(self):
user = '账号'
pwd = '密码'
csv_file_path = r'E://py//个人学期课程表.csv'
encode = str(self.get_js(user)) + "%%%" + str(self.get_js(pwd)) + "=" # 获得加密后的东西
form_data = {
'encoded': encode
}
r_session = requests.session()
r_session.post(self.login_url, headers=self.header, data=form_data)
return r_session
②爬取数据
直接来到网页显示的课表页面,将此时的URL复制下来
又发现课表有多选框,所以为了数据准确性,需要进行post数据

周次的数据选择全部,也就是0
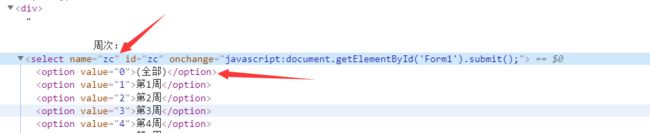
学期按时间,本次选择2019-2020-2

放大也选择是

请求的数据如下
post_data = {
'zc': '0', #周次选择全部
'xnxq01id': '2019-2020-2', #学期
'sfFd': '1' #放大
}
根据登录的会话进行再次请求
post_data = {
'zc': '0', # 周次选择全部
'xnxq01id': '2019-2020-2', # 学期
'sfFd': '1' # 放大
}
response = r_session.get(self.score_url, headers=self.header,data=post_data)
③数据清洗
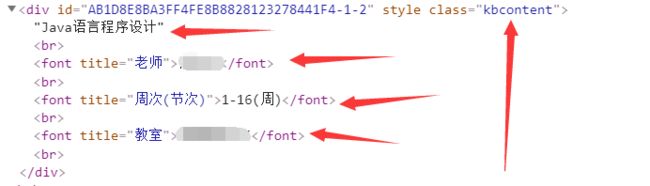
使用beautifulsoup进行数据筛选,弄出符合csv的二维列表格式
soup = BeautifulSoup(response.text, 'lxml')
page = soup.find_all('div', attrs={'class': "kbcontent"})
teachers1, teachers2 = [], []
weeks1, weeks2 = [], []
classrooms1, classrooms2 = [], []
for i in page:
teachers1.append(i.find('font', attrs={'title': '老师'}))
weeks1.append(i.find('font', attrs={'title': '周次(节次)'}))
classrooms1.append(i.find('font', attrs={'title': '教室'}))
my_detail = list(page)
for i in teachers1:
if i == None:
teachers2.append('\n')
else:
teachers2.append(i.string)
for i in weeks1:
if i == None:
weeks2.append('\n')
else:
weeks2.append('\n' + i.string)
for i in classrooms1:
if i == None:
classrooms2.append('\n')
else:
classrooms2.append('\n' + i.string)
all_data = []
pitch_number = ['(上午)\n第1,2节\n(08:00-08:45)\n(08:55-09:40)', '(上午)\n第3,4节\n(10:00-10:45)\n(10:55-11:40)',
'(下午)\n第5,6节\n(14:30-15:15)\n(15:25-16:10)', '(下午)\n第7,8节\n(16:20-16:05)\n(17:15-18:00)',
'(晚上)\n第9,10节\n(19:30-20:15)\n(20:25-21:10)', '第11,12节', '第13,14节']
temp = []
temp.append(pitch_number[0])
num = 0
pnum = 0
for i in range(len(my_detail)):
if my_detail[i].text == '\xa0':
temp.append('\n\n\n')
else:
temp.append(my_detail[i].text.split(teachers2[i])[0] + '\n' + teachers2[i] + weeks2[i] + classrooms2[i])
num = num + 1
if num == 7:
all_data.append(temp)
temp = []
pnum = pnum + 1
temp.append(pitch_number[pnum])
num = 0
page2 = soup.find('td', attrs={'colspan': "7"})
BZ = ['备注:' + page2.text, '\n', '\n', '\n', '\n', '\n', '\n', '\n']
all_data.append(BZ)
④生成csv文件(可用excel打开)
f = open(self.csv_file_path, 'w', newline='')
csv_write = csv.writer(f)
csv_write.writerow(['课程时间', '星期一', '星期二', '星期三', '星期四', '星期五', '星期六', '星期日'])
for i in range(len(all_data)):
csv_write.writerow(all_data[i])
f.close()
最后附上所有代码
工程代码如下
import csv
import requests
import execjs
from bs4 import BeautifulSoup
class SpiderOfTimetable:
login_url = 'http://jwgln.zsc.edu.cn/jsxsd/xk/LoginToXk'
score_url = 'http://jwgln.zsc.edu.cn/jsxsd/xskb/xskb_list.do'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/75.0.3770.100 Safari/537.36',
'Host': 'jwgln.zsc.edu.cn',
'Referer': 'http://jwgln.zsc.edu.cn/jsxsd/'
}
user = '账号'
pwd = '密码'
csv_file_path = r'C://个人学期课程表.csv' #生成文件的位置
def get_js(self, msg): # python 调用JS加密 返回 加密后的结果
with open('conwork.js', encoding='utf-8') as f:
js = execjs.compile(f.read())
return js.call('encodeInp', msg)
def login_requests(self):
encode = str(self.get_js(self.user)) + "%%%" + str(self.get_js(self.pwd)) + "=" # 获得加密后的东西
form_data = {
'encoded': encode
}
r_session = requests.session()
r_session.post(self.login_url, headers=self.header, data=form_data)
return r_session
def parse_page(self,r_session):
post_data = {
'zc': '0', # 周次选择全部
'xnxq01id': '2019-2020-2', # 学期
'sfFd': '1' # 放大
}
response = r_session.get(self.score_url, headers=self.header,data=post_data)
soup = BeautifulSoup(response.text, 'lxml')
page = soup.find_all('div', attrs={'class': "kbcontent"})
teachers1, teachers2 = [], []
weeks1, weeks2 = [], []
classrooms1, classrooms2 = [], []
for i in page:
teachers1.append(i.find('font', attrs={'title': '老师'}))
weeks1.append(i.find('font', attrs={'title': '周次(节次)'}))
classrooms1.append(i.find('font', attrs={'title': '教室'}))
my_detail = list(page)
for i in teachers1:
if i == None:
teachers2.append('\n')
else:
teachers2.append(i.string)
for i in weeks1:
if i == None:
weeks2.append('\n')
else:
weeks2.append('\n' + i.string)
for i in classrooms1:
if i == None:
classrooms2.append('\n')
else:
classrooms2.append('\n' + i.string)
all_data = []
pitch_number = ['(上午)\n第1,2节\n(08:00-08:45)\n(08:55-09:40)', '(上午)\n第3,4节\n(10:00-10:45)\n(10:55-11:40)',
'(下午)\n第5,6节\n(14:30-15:15)\n(15:25-16:10)', '(下午)\n第7,8节\n(16:20-16:05)\n(17:15-18:00)',
'(晚上)\n第9,10节\n(19:30-20:15)\n(20:25-21:10)', '第11,12节', '第13,14节']
temp = []
temp.append(pitch_number[0])
num = 0
pnum = 0
for i in range(len(my_detail)):
if my_detail[i].text == '\xa0':
temp.append('\n\n\n')
else:
temp.append(my_detail[i].text.split(teachers2[i])[0] + '\n' + teachers2[i] + weeks2[i] + classrooms2[i])
num = num + 1
if num == 7:
all_data.append(temp)
temp = []
pnum = pnum + 1
temp.append(pitch_number[pnum])
num = 0
page2 = soup.find('td', attrs={'colspan': "7"})
BZ = ['备注:' + page2.text, '\n', '\n', '\n', '\n', '\n', '\n', '\n']
all_data.append(BZ)
f = open(self.csv_file_path, 'w', newline='')
csv_write = csv.writer(f)
csv_write.writerow(['课程时间', '星期一', '星期二', '星期三', '星期四', '星期五', '星期六', '星期日'])
for i in range(len(all_data)):
csv_write.writerow(all_data[i])
f.close()
if __name__ == '__main__':
spider = SpiderOfTimetable()
session = spider.login_requests()
spider.parse_page(session)
conwork.js文件代码
eval(function(p,a,c,k,e,d){e=function(c){return(c<a?"":e(parseInt(c/a)))+((c=c%a)>35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(c--)d[e(c)]=k[c]||e(c);k=[function(e){return d[e]}];e=function(){return'\\w+'};c=1;};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return p;}('b 9="o+/=";p q(a){b e="";b 8,5,7="";b f,g,c,1="";b i=0;m{8=a.h(i++);5=a.h(i++);7=a.h(i++);f=8>>2;g=((8&3)<<4)|(5>>4);c=((5&s)<<2)|(7>>6);1=7&t;k(j(5)){c=1=l}v k(j(7)){1=l}e=e+9.d(f)+9.d(g)+9.d(c)+9.d(1);8=5=7="";f=g=c=1=""}u(i,32,32,'|enc4||||chr2||chr3|chr1|keyStr|input|var|enc3|charAt|output|enc1|enc2|charCodeAt||isNaN|if|64|do|length|ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789|function|encodeInp|return|15|63|while|else'.split('|'),0,{}))
工程目录格式