word2vec原理学习笔记
目录
学习词向量的意义
使用神经网络学习词向量的基本思路
word2vec主要思路
skip-gram预测
CBOW预测
softmax函数
模型训练
Skip-gram
CBOW
梯度下降
计算参数向量的梯度
负采样(Negative Sample)
本文由学习参考资料等材料后,本着容易理解的原则进行整理后形成。
学习词向量的意义
中文中的词语含义博大精深,例如:
他说:“她这个人真有意思(funny)。”她说:“他这个人怪有意思的(funny)。”于是人们以为他们有了意思(wish),并让他向她意思意思(express)。他火了:“我根本没有那个意思(thought)!”她也生气了:“你们这么说是什么意思(intention)?”事后有人说:“真有意思(funny)。”也有人说:“真没意思(nonsense)”。(原文见《生活报》1994.11.13.第六版)[吴尉天,1999] ——《统计自然语言处理》
词是自然语言处理中最小单位。词向量出现之前,词语使用词表长度的one-hot向量来表示,词表越大,词向量越大,且这些向量并没有词语意思的表示。因为他们是正交的,所以无法通过任何运算得到相似度。
motel:[ 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 ]
hotel: [ 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 ]
![]()
提出:语言学家J.R.Firth提出,通过一个单词的上细纹可以得到他的意思。这是现代统计自然语言处理最成功的思想之一。
通过向量定义词语的含义,即通过调整一个单词及其上下文单词的向量,是的根据这两个向量可以推测这两个词语的相似度;或根据向量可以预测词语的上下文。这种手法也是递归的,根据向量来调整向量,与词典中意向的定义相似。
意义:通过词向量可以推辞或近似得到两个词语的相似性,即给词向量一个“意思”,而非一个简单的表示。
使用神经网络学习词向量的基本思路
定义一个可以预测某个单词的上下文模型:
![]()
损失函数定义如下:

这里的![]() 表示
表示 的上下文,如果完美预测,损失函数为零。
的上下文,如果完美预测,损失函数为零。
然后在一个大型语料库的不同位置得到训练实例,调整词向量,最小化损失函数。
word2vec主要思路
两种主要方法,通过上下文预测中心词或通过中心词预测上下文。
skip-gram预测
通过中心词预测上下文

CBOW预测
Continuous Bag of Words:通过上下文预测中心词
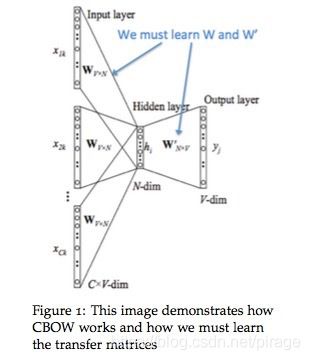
两种提高训练效率的方法:
- Hierarchical softmax:层次softmax
- Negative sampling:负采样
softmax函数
从实数空间到概率分布的标准映射方法。指数函数可以把实数映射成正数,然后归一化得到概率。
![]()
softmax之所以叫softmax,是因为指数函数会导致较大的书变得更大,小的数变得更小;这种选择作用类俗语max函数。
模型训练
Skip-gram
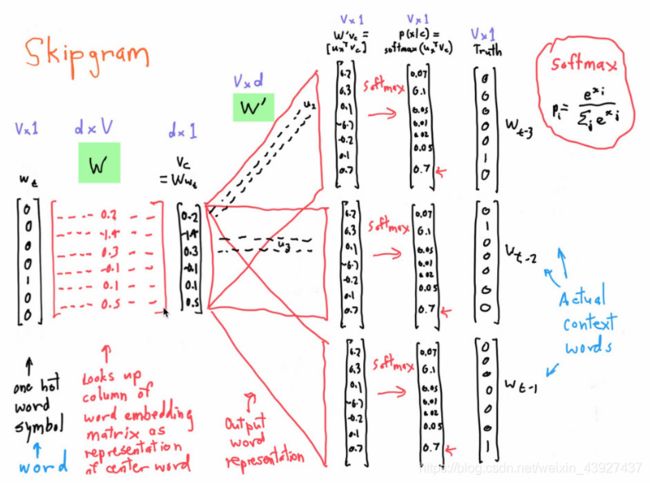
这张图很便于过程理解,所以直接贴过来了。从最左边的one-hot向量,乘以center word的 ,找到词向量,乘以另一个context word的矩阵
,找到词向量,乘以另一个context word的矩阵 得到每个词语的“相似度”,对相似度取softmax得到概率,与答案对比计算损失。抄原文,写的太清楚了。和是需要我们学习的参数。
得到每个词语的“相似度”,对相似度取softmax得到概率,与答案对比计算损失。抄原文,写的太清楚了。和是需要我们学习的参数。
skip-gram模型是根据中中心词预测上下文词出现的概率。记上图中的为 , 为
, 为 ,具体步骤如下:
,具体步骤如下:
- 生成中心词one-hot向量

- 得到上下文的词的输入向量

 设置为
设置为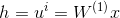
- 根据
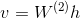 生成2C个分数向量,
生成2C个分数向量,
- 将每个词的得分转化为概率,
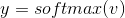
同样的,将生成的概率与真实上下文的词进行对比,希望得到匹配的结果。
与CBOW的目标函数不同,Skip-gram使用了贝叶斯假设来推到概率,假设条件独立。换句话说,他的上下文之间的关系是独立的。我们可以得到优化函数:
在每次迭代中,通过计算梯度更新未知参数。
CBOW
模型步骤分解如下:
1. 对敞口大小为C的上下文,生成one-hot矩阵![]()
2. one-hot向量左乘输入矩阵,即可得到上下文的词向量![]()
3. 对上下文的词向量求平均![]()
4. 根据输入矩阵生成得分向量![]()
5. 将得分转化为概率,![]()
怎样学习参数和呢?
首先创建爱你目标函数,从真实概率分布中学习未知概率分布,通常会根据信息论从中选择两个分布的距离度量函数,最常用的是交叉上函数:

由于y是one-hot向量,所以上面的式子可以简化为
![]()
因为 是1,所以优化目标为:
是1,所以优化目标为:
接下来就可以采用梯度下降优化目标函数。
这里解释一下为什么可以用交叉熵作为目标函数?如果预测准确,![]() ,我们可以计算损失,也就是交叉熵
,我们可以计算损失,也就是交叉熵![]() ;如果预测不准确,假设
;如果预测不准确,假设![]() ,交叉熵
,交叉熵![]() ,所以,对于概率分布的距离,交叉熵有很好的表现。
,所以,对于概率分布的距离,交叉熵有很好的表现。
梯度下降
把所有的参数写入向量 ,对d维的词向量和大小为V的词表来讲,有:
,对d维的词向量和大小为V的词表来讲,有:

由于有两个矩阵,所以的维度中有个2.。
在整个训练数据上计算损失函数 的最小化,需要对所有窗口计算一下梯度:
的最小化,需要对所有窗口计算一下梯度:
![]()
![]()
上面是梯度下降的优化方法。然而通常训练集会很大,也许有几亿的单词,更新一次就需要耗费很长的时间训练,所以使用随机梯度下降(Stochastic Gradient Descent)来计算参数,核心是每个窗口t后更新参数,公式就变为
![]()
神经网络喜欢嘈杂的算法,这可能是SGD成功的另一个原因。
在计算每个窗口时,最多有![]() 个词,所以梯度是很稀疏的,我么你只需要更新出现的词的向量。有两种方法:
个词,所以梯度是很稀疏的,我么你只需要更新出现的词的向量。有两种方法:
1. 对每个词向量做hash;
2. 只更新输入词向量矩阵和输出词向量矩阵的指定列(即词所在的那列)
最重要的一点,如果我么你有百万级别的词向量要计算,最好使用分布式方式。
计算参数向量的梯度
以skip-gram为例
对于大小为c的窗口,预测目标词的上下文可能出现的词,目标函数为
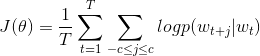
即,最大化给定中心词后的任意上下文概率。对于![]() 最简单的公式为:
最简单的公式为:
![]()
这就是softmax函数形式,其中 和
和 分别表示词的输入向量和输出向量(每个词有两个向量,这点和那重要!)
分别表示词的输入向量和输出向量(每个词有两个向量,这点和那重要!)
想要优化目标函数,我么你需要对公式求导求梯度,在推到过程中,两个知识点需要掌握:
- 矩阵求导

- 链式法则

对概率p求导
第二项是一个期望:所有上下文词向量乘以他们的概率之和,所以就等于观测值减去期望值
为了便于理解,附上常用的求导公式:
![]()
![]()
![]()
第三步中,用x代替了w,防止与前面求和的w混淆。
负采样(Negative Sample)
无论是Skip-gram还是CBOW模型,其实都是分类模型。对于机器学习中的分类任务,在训练的时候不但要给正例,还要给负例。对于Hierarchical Softmax,负例是二叉树的其他路径。对于Negative Sampling,负例是随机挑选出来的。据说Negative Sampling能提高速度、改进模型质量。
以上两种目标函数可以发现,在迭代过程中,需要计算真个词汇表的和,而词的个数通常在百万级,所以需要花费巨大的计算时间。一个简单的做法是可以对全部词汇做近似。
在每个训练步骤中,只采样几个负样本代替遍历整个词汇及。按照词频排序的分布![]() 中采样,把上述的公式和负采样结合在一起。我们只需要更新:
中采样,把上述的公式和负采样结合在一起。我们只需要更新:
- 目标函数
- 梯度
- 更新法则
NS方法是Mikolov et al.在论文Distribution Representations of Words and Phrases and Their Compositionality 中提出的。NS事实上优化的是不同于上面的目标函数。存在一个中心词和上下文词对![]() ,用
,用![]() 表示该词来自训练集,
表示该词来自训练集,![]() 表示词不在训练集。首先,使用sigmod函数对概率P建模:
表示词不在训练集。首先,使用sigmod函数对概率P建模:
![]()
然后,建立一个目标函数,来最大化出现在训练集中的词对的概率和没有出现在训练集的词对的概率。我们采用简单的最大似然来计算,这里就是模型中的未知参数,也就是上面模型中的和
其中,![]() 表示负样本的采样。那么,我们的目标函数就变成了:
表示负样本的采样。那么,我们的目标函数就变成了:

其中,![]() 表示从分布
表示从分布![]() 采样的
采样的 个负样本。
个负样本。
关于什么样的分布![]() 能够是的近似效果最好的讨论有很多,常用的方法是一元模型值去3/4次方,3/4次方能够是的低频词的采样效率被提高。
能够是的近似效果最好的讨论有很多,常用的方法是一元模型值去3/4次方,3/4次方能够是的低频词的采样效率被提高。
参考资料:
https://blog.csdn.net/pirage/article/details/84931180
http://www.hankcs.com/nlp/word-vector-representations-word2vec.html