Accurate Structured-Text Spotting for Arithmetical Exercise Correction 论文翻译
Accurate Structured-Text Spotting for Arithmetical Exercise Correction
精确的结构化文本识别的算术练习题纠正算法
原文为腾讯优图实验室于AAAI2020会议上所发论文,如有侵权,请联系邮箱
本译文于2020年3月3日发布于CSDN博客,转载请注明出处
摘要
纠正算术练习题一直只在实验室中进行实验,且对于小学老师来说一直是一个非常耗费时间的任务。为了减少小学老师的负担,我们提出了算术练习题检查器(AEC),它是第一个可以自动评估练习题照片上所有算术表达式的系统。主要的挑战难点是算术表达式是由机打和手写的文本组成的特定模式。手写文本经常有曲折的边界,而且文本行之间难以区分,尽管这些文本是算术表达式的一部分。更糟糕的是,算术表达式可能是错误的,而这会导致文本内容信息对于识别几乎没有帮助。为了解决这个问题,我们基于算术练习题的内在特征引入一个集成了检测,识别,评估三部分。这些特征叫做:1)边界不明确,2)局部相关模式,3)符号全局不相关。实验结果表明AEC可以在40种主流的小学算术练习题上达到93.27%的纠正准确率。截至目前,AEC线上服务平均每天处理75,000任意练习题,且已经减少了超过1,000,000位用户的负担。AEC展示了实施基于视觉的系统的好处,这是帮助教师减少重复任务的一种方式。
1 介绍
随着科技的快速发展,小学教育一直在快速进化。截止2018年底,中国有超过一亿的小学生,而且数量还在持续上升。现在共识是小学老师应该更加关注学生每天的表现和学习方法,从而对教师提出了更高的标准。然而老师的时间任然被如批改作业等高重复性的工作所占据。我们在四所小学的调查表明一个小学数学老师每学期平均要批改6,000份练习题。为了解决这个问题,一个可行的办法是让学生的父母纠正自己孩子的作业(这在中国是非常常见的现象),但是这需要专业知识,而且并不适合所有的父母。大多数父母对于孩子的课程并不熟悉,也难以给出有效的指导。
在这篇文章中,我们致力于设计一个可以自动纠正小学算术题的系统。为了实现这个目标,我们开发了一种新颖的端到端方法:算术练习检查器(AEC)。它首先通过检测提取出所有的算术表达式,然后通过识别将他们转化为文本。最终通过算术逻辑评估它的正确性。如图1所示。有了AEC,我们可以在几秒内完成纠正练习题,然而手工批改经常需要几分钟。

练习题上的所有算术表达式,并返回纠正结果和建议。
AEC的设计是不平凡的。算术表达式由具有算术模式的机打和手写文本组成。它在不同的出版商和不同年级的学生之间没有固定的格式,甚至可以完全是手写的。手写文本较机打的文本来说通常是潦草的,这导致它具有:1)曲折的边界,2)复杂的文本行,如图2所示。曲折的边界生成的边缘区域被背景填充并且缺乏明显的视觉特征,这阻碍了主流的基于锚框的检测方法,如SSD(Liu et al. 2016),和Faster-RCNN(Ren et al. 2015)。更糟糕的是,这些方法趋向于设置一个宽松的IoU阈值来平衡真的和假的候选。这会导致许多只包含算术表达式一部分的候选区域为真。另一方面,复杂的行通常会干扰邻近的行,这导致提取单行文本非常具有挑战性。因此,现有的文本检测方法如(Tian et al. 2016)针对单行文本在这种情况下会受到影响。除此之外,因为算术表达式可能是错误的,它的上下文信息很薄弱。这不仅会使预定义的词典无效(Liao et al. 2017),也会导致难以训练识别网络。
为了解决这些问题,我们通过研究算术表达式的内在特征设计出了AEC系统,特征有:1)边界不清晰,2)模式局部相关,3)符号全局无关。我们基于CenterNet(Duan et al. 2019)设计出了算术表达式检测部分。它采用卷积特征作为输入,输出(左上角,中心,右下角)三个信息来表示算术表达式,而不是矩形框。我们引入了一个水平焦点损失来使网络更加注意学习困难的水平边界。在识别部分,我们提出了一个算术神经翻译器(ANMT),ANMT是一个基于序列到序列的编解码模型,它是我们在自动字幕生成(Xu et al. 2015)的最近进展中激发出来的。与早先的假设固定的单行,从左到右顺序文本的文本检测算法不同的是,ANMT集中注意于水平和垂直两个维度。因此,即使相邻行之间存在干扰,它也可以应对结构化的算术表达式如多行文本。特别的是,我们根据AEs模式局部相关性设计了编码器,根据符号的全局无关性设计了解码器。本文主要贡献如下所示:
- AEC是第一个自动纠正练习题的端到端的系统。我们观察并总结出了三个AE的不同特征,并使用它们来提升系统设计。实验结果表明AEC是有效的。截至目前,AEC线上服务平均每天处理75,000任意练习题,且已经减少了超过1,000,000位用户的负担。
- 我们率先建立了算术练习题的数据集:AEC-5K。它包含53000张精挑细选的照片,这些照片是从覆盖中国小学所有年级的四十种主流练习题中收集的。我们很快会发布这些数据集。
2 相关工作
AEC本质上是文本识别挑战。在这个部分,我们简短地介绍一些文本识别方法和他们的关键部分,叫做文本发现。
文本检测
现有的文本检测方法可以粗略地分为基于字符的,基于行的和基于单词的方法(Li, Wang, and Shen 2017)。随着DNN技术的蓬勃发展,基于单词的方法非常流行,因为单词对于主流对象检测框架来说是的合适目标(Ren et al. 2015; Liu et al. 2016; Redmon et al. 2016)。受SSD启发(Liu et al.2016),TextBoxes(Liao et al.2017)利用不同比例的特征图的组合进行文本检测。由于文本特征(如形状,颜色等)与一般目标有很大不同,许多方法都使用自定义的区域推荐方法。CTPN(Tian et al.2016)设计了一个垂直锚机制来共同预测固定宽度的提案的位置和评分
除了检测普通文本外,最近的方法专注于更具挑战性的文字和扭曲文字。对于定向文本检测,ITN(Wang et al.2018)使用网络内转换嵌入对场景文本实例的几何配置进行编码。在(Lyu et al.2018)中,它将文本边界框和分段文本区域的角点定位在相对位置。在(He et al.2017b)中,它使用直接回归来预测文本边界框与给定点的偏移量。对于扭曲文本检测,Textsnake(Long et al.2018)为场景文本设计了一种灵活的表示形式,以水平,定向和弯曲形式表示文本实例。此外,几种方法通过使用马尔可夫聚类网络(Liu等人2018b)或新颖的注意力机制(He等人2017a)为文本检测提供了新的视角。
文本识别
现有的文本识别方法可以粗略分类为基于单词级别的分类,基于序列到标签的方法和基于序列到序列的方法(Li,Wang and Shen 2017)。现在,基于序列到序列的方法在利用上下文方面的出色表现正在蓬勃发展。随着RNN技术的发展,几种方法(Shi,Bai and Yao 2017; He et al.2016b)提出了深度递归模型来编码CNN的输出特征并采用CTC作为文本解码器。在(Lee and Osindero 2016; Yang et al.2017)中,他们在解码单个字符时利用基于注意力的序列到序列框架专注于指定的CNN特征。对于更具挑战性的不规则形状的文本,最近的工作(Shi et al.2016)利用空间变换器网络来校正输入的图像。 这些工作着重于单行文本的识别。与这些工作不同的是,AEC受到自动字幕生成(Xu et al.2015)和图像标记系统(Deng,Kanervisto and Rush 2016; Deng et al.2017; Deng et al.2017)的最新进展的启发,并且可以识别结构化多行文本。
文本发现
现有的文本识别方法包括两种类型:1)使用单独的检测和识别模型(在测试阶段即端对端),或2)使用统一的框架(在训练/测试阶段均端对端)。对于第一种类型,单独的分支可以从更多的自定义特征表示中受益,因此,检测器可以使用紧密的边界框获得精确的建议,而识别器可以生成精确的解析结果。在(Jaderberg et al.2016)中遵循此规则,它利用整体模型进行检测,并利用单词分类器进行识别。同样,文本检测方法TextBoxes(Liao et al.2017)利用CRNN(Shi,Bai and Yao,2017)进行识别,这有助于减少在检测阶段生成的假阳性结果。对于第二种类型,最近的工作(Liu et al.2018a; Li,Wang and Shen 2017)提出了统一的神经网络,用于同时检测和识别,两个分支之间共享计算和视觉信息。统一系统有望产生更好的系统效率。我们的系统属于第一类。

3 结构总览
我们的目标是:1)设计一个可以定位所有算术表达式的检测网络,2)建立识别网络来解析其表达式,以及3)建立算术逻辑以评估其正确性。 该架构如图3所示。检测分支的主干CNN是Hourglass52(Newell,Yang,and Deng 2016),识别分支的主干CNN是ResNet-50(He et al.2016a)。 我们用ResNet-50中的串联ReLU(Shang et al.2016)代替了整流线性单位(ReLU)以减少模型参数。
AE检测部分
AE检测网络可以是主流的一阶段检测器,例如SSD(Liu et al.2016),也可以是二阶段检测器,例如Faster-RCNN(Ren et al.2015)。 尽管它们有所不同,但大多数都设置了许多具有预定义大小的矩形(称为锚定框),并将其回归到目标的真实位置。 为了确保覆盖范围,他们通常会以合理的比例和宽高比部署大量锚。 但是,不同的AE类型以及答题者的写作风格多样性进一步增加了难度。 面对这个问题,我们设计了基于CenterNet的检测分支(Duan et al.2019)。 它避免了使用锚框,并且完全适合AE的边界模糊特征。
边界模糊性:
我们观察到AE的特征是边界不明显。 与一般对象相比,字母/数字的边界是隐式的,因为它们通常是凹陷的边缘。 如果使用矩形边界框表示AE,则其边缘区域可能会被背景填充并且缺乏明显的视觉特征。 此外,由基于锚框的方法生成的边界框不够精确。 了解到这些方法倾向于为阳性样本设置宽松的交并比阈值(IoU),以平衡阳性样本和阴性样本之间的数量,从而促进训练过程。 取交并比阈值IoU = 0.7,许多带有不精确边界框的样本也表示为正样本。
面对这些问题,我们设计了AE检测网络。 它采用卷积特征作为输入和输出三元组,而不是代表AE的矩形框。 三元组由1)左上角关键点,2)中心关键点和3)右下角关键点组成。 角点对用于生成候选区域,而中心点用于确认其有效性。 三元组的视觉模式分别通过CenterNet中定义的级联corner pooling和center pooling来提取。 我们建议参考(Duan et al.2019)的详细信息。 与基于锚框的方法相比,我们的检测网络可以更好地提取AE角的特征并有助于生成完整的候选区域。

网络很少生成具有无效垂直边界(红色矩形)的候选区域,但是经常生成具有
无效水平边界(虚线蓝色矩形)的候选区域。 “GT”代表此AE的真实矩形框。
为了更好地精确定位AE的角点,我们建议使用水平焦点损失函数进行角点回归。 与CenterNet中的同类工作相比,它对水平轴上的转角处以更严厉的惩罚。 与垂直边界相比,学习水平边界更加困难。 如果一个AE在水平方向上丢失了部分表达式,则它仍然有很高概率是一个有效的点(蓝色虚线矩形),在垂直情况下(红色矩形)则不适用,如图4所示。因此, AE的水平边界特征更加模糊,难以学习。在CenterNet中,将预测角的损失定义为:

,其中∆x和∆y是根据真实值性预测的角的坐标偏移。基于此观察,我们提出水平焦点损失如下:

我们使用α来控制惩罚,实验时默认设置为2。有了此损失函数,我们的检测分支可以更好地查明AE的水平边界。
AE识别分支
大多数现有的文本发现方法都专注于识别单行文本(Shi,Bai and Yao,2017; He et al.2016b; Lee and Osindero,2016)。 但是它们并不适合识别AE,因为它们通常是结构化,潦草的手写文本和多行文本。 面对这个问题,我们设计了一种算术神经机器翻译模块(ANMT)进行识别。 ANMT是一种基于编码器-解码器的序列到序列模型,其灵感来自于自动字幕生成的最新进展(Xu et al.2015;Sutskever,Vinyals and Le 2014)。与假定文本采用单行和从左到右严格排序的方法不同(1D),ANMT允许将注意力集中在AE的水平和垂直方向(2D)。此外,我们发现AE具有另外两个不同的特征,即模式局部相关和符号全局无关。 我们利用这些特征来增强识别分支。
ANMT基于原始的NMT框架(Bahdanau,Cho and Bengio 2014)。 它可以模拟从CNN的特征嵌入x到表达式 y y y = { y 1 y_1 y1, y 2 y_2 y2,···, y n y_n yn}的转换概率。 请注意,原始NMT将CNN的特征嵌入为x∈ R C × H × W R^{C×H×W} RC×H×W并将其置换为一维时间主形式{ x 1 x_1 x1,···, x i x_i xi,···, x W x_W xW},其中 x i x_i xi∈ R C × H R^{C×H} RC×H是来自要素地图的垂直剪辑,具有通道C,宽度W和高度H。此嵌入无法用多行文本表示AE。受(Deng,Kanervisto and Rush 2016; Deng et al.2017)的启发,我们保持特征图x = { x 11 x_{11} x11,···, x i j x_{ij} xij,···, x H W x_HW xHW}不变,其中 x i j x_{ij} xij∈ R C R^C RC。 因此,我们有:
其中f(·)是一个根据前一个输出 y t − 1 y_{t-1} yt−1,当前状态 s t s_t st和语境向量 c t c_t ct输出 y t y_t yt概率的非线性方程。对于解码器,我们选择由 s t s_t st构成的单向LSTM g g g(·)作为函数。

其中 c t c_t ct显示了对编码器中不同隐藏状态 h i j h_{ij} hij的注意:

注意力的权重向量 a t i j a_{tij} atij可以按照下式计算:
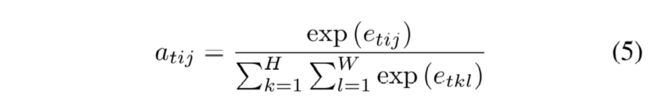
其中 e t i j e_{tij} etij对解码器中的隐藏状态 s t − 1 s_{t-1} st−1参与编码器中的隐藏状态 h i j h_{ij} hij计分。 这里的 e t i j e_{tij} etij有几个定义(Luong,Pham and Manning,2015),我们在这里改编 e t i j e_{tij} etij = V a T V^T_a VaT tanh W a s t − 1 W_{as_{t-1}} Wast−1 + U a h i j U_{ahij} Uahij。 最后,ANMT的训练目标是使训练实例( x s x^s xs, y s y^s ys)的对数似然性最大化:

局部相关:与算术模式耦合:
AE的特征在于特定符号之间的局部相关性。 例如,公式中的“\n”之后通常会出现一个“=”。 这些特定的局部模式可以在隐藏状态下进行编码,以放大上下文信息。 为了实现此目标,我们使用MD-LSTM(Voigtlaender,Doetsch and Ney 2016)进行编码。 与常用的bi-LSTM相比,MD-LSTM对沿两个轴嵌入的特征进行编码,并生成相同大小的变换嵌入。 它允许编码器查看更多上下文,并得到更稳定的训练。 此外,可训练的初始隐藏状态作为垂直位置嵌入插入到每行的开始位置,用于捕获垂直方向上的顺序信息。

全局无关:算术符号去耦合:
AE的另一个明显特征是它在算术上可能不正确(例如1 + 1 = 3)在训练阶段,算术表达式充当(3)中的目标上下文y。除少数算术模式外,大多数符号(例如数字,字母)都是由受访者随机书写的。 因此,这些符号在全局上是不相关的,并且彼此之间具有弱的甚至没有语义关系。 这使得目标上下文对解码器的价值降低。 出于这种观察的动机,我们使用上下文门让解码器将更多的精力放在源上下文上,也就是视觉特征的嵌入。 该上下文门本质上是一种门功能,可动态控制源上下文和目标上下文有助于生成目标词的比率(Tu等人2017)。 公式化地表达,我们有:
![]()
其中 w t w_t wt表示上下文权重,σ(·)是logistic sigmoid函数。 使用 w t w_t wt时,等式(3)中的原始解码过程替换为:
![]()
AE的全局无关特征进一步指导了注意机制的设计。 如等式(4)所示。 注意力机制通过汇总所有隐藏状态来提取源上下文。 由于符号彼此之间的语义关系很弱,甚至根本没有语义关系,因此在整个解码过程中,隐藏状态仅应获得相当大的权重。当解码器推断出隐藏状态的已显示符号(如果存在)时,就可以实现如此大的权重。 例如,符号“ * ”的视觉特征嵌入在推断“ * ”时被关注,而在推断其他符号时不应被大量关注,如图5所示。为了实现这一目标,我们保留了一个掩码矩阵M 其大小与h相同,其中所有符号的默认值为1。对于特定元素 h i j h_{ij} hij∈h,如果其对应的权重 a t i j a_{tij} atij> γ γ γ,其中 γ γ γ是截止阈值,并且默认设置为0.5,则:
![]()
因此,等式(4)被替换为:

除了识别分支之外,我们还利用AE的候选对象来提高识别能力。 注意,AE通常由数十个符号组成,并且单个识别错误可能会很可能使校正结果产生偏差。 面对这个问题,我们通过轻微旋转,调整大小或填充来生成多个AE候选对象。 这些候选将与原始AE一起获得认可。 选择结果中的多数表达作为输出,或者如果不存在多数,则选择原始AE的表达。
AE评估分支
AE本质上可以分为两类:自包含和共存表达式。对于自包含表达式,可以自己评估其正确性。这种类型的表达式可以表示为f X g,其中f和g是基本算术运算的组合,例如C0×(C1- C2)÷C3,这里C0,C1,C2,C3是有理数,而N表示运算符号,例如为“ =”。AEC首先评估f和g,然后检查f Ng的正确性。对于共存的表达式(例如公式),AEC会评估所有子表达式并检查其一致性。例如,一个公式包含问题f(x)= C0(例如2x-1 2 = 32),中间函数g(x)= C1(例如2x = 2)和答案x = C2(例如x = 1)。 AEC评估问题和所有中间函数,并获得一致的结果x = C2,这证明了该公式的正确性。否则,AEC返回false。如果是这样,AEC还将根据错误类型向受访者提供建议,如图1所示。
4 实验
数据集:现在没有公开的算术练习数据集。因此,我们构建了AEC-5k数据集,该数据集由40种主流小学练习题组成。 AEC-5k包含5,000张用于训练的图像和300张用于测试的图像,平均分辨率为1152×768,每幅图像的平均AE数量为8.7。每个AE注释都有两个属性:1)一个边界框,即使它是多行的,它也覆盖了整个AE;以及2)字符级文本注释。注释中出现120种不同的字符,它们由数字(例如“ 1 ”,“ 2 ”),操作符号(例如“ +”,“×”),大写/小写英文字母(例如“ cm”)组成,“ kg”)及其中文映射。由于标记的数据不足以训练识别分支,因此我们通过参考(Deng et al.2017)合成了600k手写体数据。我们将尽快发布这些数据集。
准则:我们采用两种评估指标:1)ICDAR 2015的评估准则(Karatzas等,2015),用于评估文本检测与识别表现。由于AE是任意符号的排列,因此我们选择通用的“端到端”准则,因为它可以在没有上下文词典的情况下工作。2)AE校正精度可衡量AEC的性能。如果AE的表达式满足相应的算术逻辑,则认为它是“正确的”。
实现细节
基于Pytorch(Paszke et al.2017),我们在具有8个Nvidia P40 GPU和64GB内存的常规平台上实施所有基准测试。 我们在不使用任何外部数据集进行预训练的情况下初始化检测分支。 AEC-5k训练数据用于微调模型,直到收敛为止。通过以下方式增强训练数据:1)在不更改图像高度的情况下按比例范围[0.8,1.2]随机缩放图像的宽度,以及2)从比例范围[0.75,1]的原始图像中随机提取图像作物; 带有截短AE的图像作物将被丢弃。 我们采用学习速率为2.5× 1 0 − 4 10^{−4} 10−4的Adam优化器进行优化。 我们将NMS(Rosenfeld and Thurston 1971)应用于生成的文本区域。 对于识别分支,我们使用AEC-5k训练数据和600k综合数据进行训练,而无需使用预训练模型。 我们采用学习率0.1调整SGD优化器以进行优化。 学习率在300k次迭代后减半,然后在每100k次迭代后再次减半。
AEC:Ablation study
我们进行基准测试以研究拟议组件在AEC系统中的贡献。
边界不明确:受边界不明确特征的影响,AEC检测分支使用水平焦点损失函数进行角点回归。我们观察到,通过将CenterNet中的原始损失替换为水平焦点损耗(α= 2),精度,查全率和F度量分别提高了1.7%,0.64%和1.23%。如表1所示,α= 2也是平衡学习水平和垂直边界的折衷方案。此外,我们使用多尺度输入进行改进。在多比例设置中,图像分辨率是原始图像的{0.8,1,1.2}倍。多尺度输入产生更可靠的结果,我们选择“AEC检测(MS,α= 2)”作为默认检测方法。
本地相关的模式:在表2中的“ANMT w/o local”方法中,我们用MD-LSTM编码器替换了ANMT中原始的bi-LSTM编码器,以嵌入本地相关算术模式的上下文信息。我们发现,识别精度和校正精度分别提高了0.52%和0.68%。它验证了MD-LSTM编码器有助于编码算术模式。
全局无关的符号:它指导ANMT解码器中两个模块的设计:1)上下文门和2)算术注意机制。 在“ ANMT w / o cg。”方法中,我们删除了上下文门。 结果,识别精度和校正精度分别降低了0.75%和1.40%。 在“ ANMT w / o attn.”方法中,我们将算术注意模块替换为默认的全局注意。 此操作将识别精度和校正精度分别降低了0.88%和1.58%。此外,我们利用AE的候选对象进行改进。鉴于AE,我们通过轻微旋转,调整大小或填充来生成其候选对象。 每个动作产生两个候选。 对于调整大小的候选对象(“带有分辨率的ANMT”),分辨率范围为[0.8,1.2]; 对于填充的候选项(“带填充的ANMT”。),空白填充的比例为[0.05,0.25]。 对于旋转的候选对象(“带有旋转的ANMT”),角度限制在[-10°,10°]之内; 在方法“ ANMT(AC)”中,使用了由三个动作生成的所有候选。 我们使用批处理操作来加速。 与ANMT相比,“ ANMT(AC)”的识别率提高了2.09%,校正精度提高了2.61%,而推理速度却增加了27%。 我们选择“ ANMT(AC)”作为默认识别方法,因为用户对校正精度更加敏感,如用户反馈中所述。


AEC: 与最新技术的比较
检测:我们使用AEC-5k训练数据及其扩充来训练检测分支。相同的数据用于实施主流的一阶段和两阶段文本检测方法的训练。对于基于锚框的方法,我们根据训练数据中AE对象的方面和比率的K均值聚类结果设置6×12个锚。 AEC-5k测试数据用于评估。实验结果表明,与基于锚盒的方法相比,我们的方法得到了更精确的建议,这对于随后的AE识别至关重要。识别和正确性评估:我们使用AEC-5k训练数据和600k综合数据训练识别分支。相同的数据用于实现最新的文本识别方法。为了评估端到端度量以及校正精度,我们使用“ AEC检测(MS)”生成的建议作为所有识别方法的输入。请注意,CRNN(Shi,Bai和Yao,2017年)针对单行文本,因此它无法直接识别多行AE。为了进行公平的比较,我们在AEC-5k训练数据上添加了额外的单行文本顶点注释,然后使用自定义锚点构建SSD(Liu et al.2016)模型以提取单行文本。分别识别这些文本,并将输出的表达式作为结果串联在一起。与这些方法相比,我们的方法获得了最佳的识别性能和校正精度。


AEC:用户反馈
通过在线反馈页面,我们在338天内收到了1643条有效评论。 大多数参与者通过以下评论将AEC视为有益的工具:“它可以同时计算多个公式,并且确实节省了时间”,并且,“校正速度很有希望,非常有帮助”。 同时,一些反馈也指出了当前系统的缺陷。 例如,一位参与者说:“它无法评估图形计算(例如,∆ + ∆ = 2∆)”。 我们将在将来消化他们的建议以改进系统设计。
5 结论
在本文中,我们提出了AEC,这是一个自动纠正主要算术练习的端到端系统。 AEC的设计源于算术表达式的三个不同特征,这是现有文本发现方法的障碍。 我们还介绍了AEC-5k数据集以辅助AEC的研究,该数据集由40个主流初级练习中的5张300张图像组成。 未来的方向将是支持更多表达类型的评估。