蒸馏法第三节——蒸馏法&检测任务
【1】G. Chen, W. Choi, X. Yu, T. Han, and M. Chandraker. Learning efficient object detection models with knowledge distillation. In Advances in Neural Information Processing Systems, pages 742–751, 2017
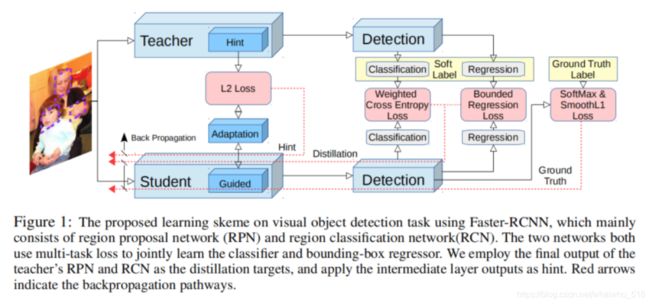
首先,使用fitnet方法去拟合教师网络的中间层输出,
然后,学习强分类模块RPN RCN;为了解决类别不平衡问题,蒸馏模型使用权重交叉熵损失函数,整体学习目标如下:

解决不均衡类别问题:
其中: 下面公式中前一项是学生网络去学习真实的标签,后一项是学习教师网络
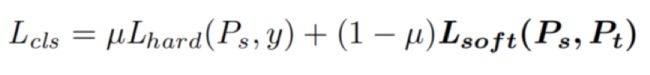
其中学习教师网络使用交叉熵函数;

解决教师网络上限问题:学生网络需要尽可能和真实标签接近,一旦学生网络的质量超越教师网络时,下面公式的Lb就为0,即教师网络不再指导学生网络。

隐层学习问题:参考fitnet学习方法,需要教师网络和学生网络的隐层损失函数尽可能接近,如下所示,其中需要保证教师网络和学生网络隐层的神经元数量(长、宽、通道数)保持一致。为了保证通道数一致,在学生网络的guided 层后面加个自适应层,实验发现即使学生和教师网络该层的通道数一致,自适应层也可以更有效的获得知识transfer。

【2】Q. Li, S. Jin, and J. Yan. Mimicking very efficient network for object detection. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7341–7349. IEEE, 2017. ——目标检测
目标检测任务要比识别任务的网络设置更复杂,输出层除了要有类别信息还需要有bounding-box,
创新点1:由于全连接卷积特征图的维度太高,希望学生网络能够更专注于学习“感兴趣的特征区域” 而不是所有特征。局部区域特征可以通过对bounding-box采样得到,bounding-box包含小网络和大网络使用金字塔池化后的不同大小 不同比例的特征图。
网路的目标函数如下:其中Lm是学生网络学习教师网络的中间特征层,蒸馏法学习的损失。

背景介绍「上面公式中的Lgt使用文献fast r-CNN的方法, 同下面公式,

这是个组合损失函数,其中前一项是Lcls(p, u) = − log pu 是关于真实类别的对数损失,即当前图像属于某个类别u(人脸,汽车)的概率;第二项是对于类别u(人脸,汽车),bounding-box回归的目标函数,后面一项方括号的意思是当u类别存在,该值才为1 ,通过约定将所有的背景像素都设为0,因为背景像素不存在boundingBox ,其中bounding Box回归使用下面的公式

上面使用的是较为鲁邦的L1范数作为损失函数,当回归目标无界时,训练L2损失函数需要更加仔细对学习率进行调整来避免梯度爆炸。」
公式中的mimic loss潜在的问题是在训练过程中会变大,所以需要平衡好参数,此外,空间金字塔池化也会引起信息损失。因此使用L2损失来进一步稳定训练过程,新的mimic loss损失如下:
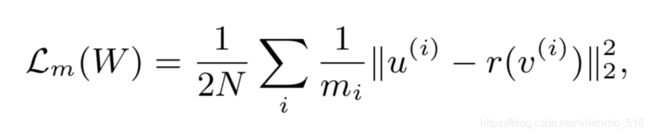
公式中,m是第i个候选区域的特征维度,v是学生网络的输出特征,r是一个回归函数用来保证v和u有相同的维度,u是教师网络的特征图第i个候选使用空间金字塔采样。
【3】
Y. Wei, X. Pan, H. Qin, and J. Yan. Quantization mimic: Towards very tiny cnn for object detection. arXiv preprint arXiv:1805.02152, 2018.
idea:首先,先训练一个教师网络,然后对feature map进行量化操作,使用量化函数得到量化网络,同时微调该网络,改网络作为教师网络,来指导量化的学生网络。
进行蒸馏学习的损失函数如下所示:

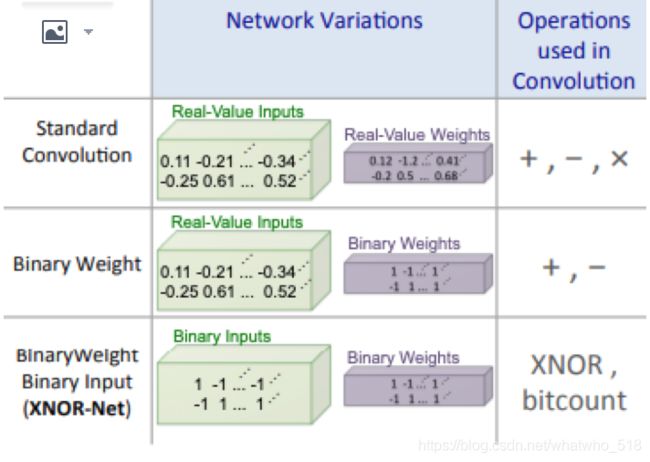
参考1) 关于量化网络的一些介绍:《XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks》
从下图可以看到,传统的卷积核操作算子+,-,*三个,并且输入和权重一般都是float类型,一种优化的方式是操作算子改成+和-,权重改成二元的+1和-1;当然还有更加优化的版本, 操作使用异或门,输入和权重全都是二元的,所以无论是模型大小(二元),还是速度上(异或门)都有非常大的提升。