数据处理(1.2)-python 正则表达式-量词与贪婪
学习极客时间的学习笔记
一、正则模式种类
正则有不同的匹配模式,有三种模式,第一:贪婪匹配,第二:非贪婪匹配,第三:独占模式
主要区别在于匹配是一次还是多次,长度尽量长还是尽量短
看到这个次数次数的,我们回顾一下量词的定义:

其中的 * 和 + 你可能觉得可以用 {m,n} 替代,但其实没那么简单
比如用 a+ 处理 aaabb
import re
# 检索 a
re.findall(r"a+","aaabb")
# ["aaa"]假如用 a* ,则可以看到 4 个匹配结果,
import re
re.findall(r'a*','aaabb')
# ['aaa','','','']1. 贪婪模式
在正则中,表示次数的量词默认是贪婪的。在贪婪模式下,尽可能的最大长度去匹配
2. 非贪婪模式(lazy)
匹配单个字符,在量词后加上 ?
import re
re.findall(r"a*","aaabb")
# ['aaa','','','']
re.findall(r'a*?','aaabb')
# ['','a','','a','','a','','','']
3. 独占模式
什么是独占模式呢?我们需要搞明白什么是回溯
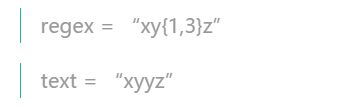
比如上面两个例子,第一个在匹配y时,匹配成功两个 y 以后,会尝试再吃一个 y ,看能不能凑够 3 个y,结果吃下去的是 z,那就会把 z 从匹配字符里吐出来,再用正则表达式的 z 去寻找匹配,就这时才成功匹配 xyyz。这个就是回溯的过程
而独占模式就是尽可能多的去匹配,如果匹配失败就结束。不会进行回溯,方法是:

在量词后加上一个 + 号
在 python re模块中没有独占模式,我们需要这样:
import regex
regex.findall(r'xy{1,3}z','xyyz') # 贪婪模式
# ['xyyz']
regex.findall(r'xy{1,3}+z','xyyz') # 独占模式
# ['xyyz'}
regex.findall(r'xy{1,3}+yz','xyyz') # 独占模式
^([A-Za-z0-9._()&'\- ]|[XXXX越南语]+$脱字符 ^ 表示正则开头,美元符号 $ 表示以正则结尾。
这里用独占模式就节省了大量的计算资源
课后练习题
对于一篇英文文章,单词与单词之间用空格隔开,在引号里的一到多个单词表示特殊含义,即引号里面的多个单词要作为一个单词,现在需要取出文章中所有单词,假设没有引号以外的其他所有标点符号。
首先,先匹配正常的单词,也就是不在 "" 中的.
\w+
再匹配 " " 中的单词
"[^" ]+"
再用 | 组合,即可