multi-teacher学习
多老师学习:
1.Learning from Multiple Teacher Networks
1)不同example 输入到网络会有不同的输出,(x1,x2,x3)得到(p1,p2,p3),(q1,q2,q3),怎么保证||q1-q2||和||q1-q3||的相对距离(q2和q3谁取胜)和||p1-p2||和||p1-p3||的相对距离相近(p2和p3谁取胜)。
2)如果是多个老师的话,因为不同老师可能结果不同还是有噪音,所以取老师们中数量较多的结果。作为multi-teachers的结果。
3)具体还有选择哪些层作为immediate layer。
问题:训练实例输出的距离差感觉不适合NLP。
2.MOG,
1)是chair通过隐向量来动态决定权重的。
2)共用一个encoder的(teach的模型,针对不同的数据源,应该encoder参数也不同?应该retrieval一个不用考虑这个问题)
3)experts是分领域训练的,chair是整个数据集训练的(感觉可以删掉,毕竟是要一个简单的stud模型)。
问题:expert需要预训练。没看懂chair怎么整合的。
4)
experts怎么融合。
p j = ∑ l = 1 k + 1 β j l ⋅ p j l \mathbf{p}_{j}=\sum_{l=1}^{k+1} \beta_{j}^{l} \cdot \mathbf{p}_{j}^{l} pj=∑l=1k+1βjl⋅pjl
β j l = exp ( u l T u e , l ) ∑ b = 1 k exp ( u b T u e , l ) u l = MLP ( h ) h = s j 1 ⊕ p j 1 ⊕ ⋯ ⊕ s j k ⊕ p j k ⊕ s j k + 1 ⊕ p j k + 1 \begin{aligned} \beta_{j}^{l} &=\frac{\exp \left(u_{l}^{T} u_{e, l}\right)}{\sum_{b=1}^{k} \exp \left(u_{b}^{T} u_{e, l}\right)} \\ u_{l} &=\operatorname{MLP}(\mathbf{h}) \\ \mathbf{h} &=\mathbf{s}_{j}^{1} \oplus \mathbf{p}_{j}^{1} \oplus \cdots \oplus \mathbf{s}_{j}^{k} \oplus \mathbf{p}_{j}^{k} \oplus \mathbf{s}_{j}^{k+1} \oplus \mathbf{p}_{j}^{k+1} \end{aligned} βjlulh=∑b=1kexp(ubTue,l)exp(ulTue,l)=MLP(h)=sj1⊕pj1⊕⋯⊕sjk⊕pjk⊕sjk+1⊕pjk+1
u e , l u_{e,l} ue,l is an expert-specific, learnable vector that reflects which dimension of the projected hidden representation is highlighted for the expert. 在第j步时 u l T u_{l}^{T} ulT是所有状态加起来。
loss怎么计算
1)experts的loss
L experts = ∑ l = 1 k + 1 ∑ ( X l , Y l ) ∈ S l ∑ j = 1 n μ k y j l log p j l \mathcal{L}_{\text {experts}}=\sum_{l=1}^{k+1} \sum_{\left(X^{l}, Y^{l}\right) \in S_{l}} \sum_{j=1}^{n} \mu_{k} y_{j}^{l} \log \mathbf{p}_{j}^{l} Lexperts=∑l=1k+1∑(Xl,Yl)∈Sl∑j=1nμkyjllogpjl
2)chair的loss
L chair = ∑ r = 1 ⌊ D ⌋ ∑ j = 1 n y j log p j {\mathcal{L}}_{\text {chair}}=\sum_{r=1}^{\lfloor D\rfloor} \sum_{j=1}^{n} y_{j} \log \mathbf{p}_{j} Lchair=∑r=1⌊D⌋∑j=1nyjlogpj
3)模型在训练时候的loss
L = λ ⋅ L experts + ( 1 − λ ) ⋅ L chair \mathcal{L}=\lambda \cdot \mathcal{L}_{\text {experts}}+(1-\lambda) \cdot \mathcal{L}_{\text {chair}} L=λ⋅Lexperts+(1−λ)⋅Lchair
→关于 U e , l U_{e,l} Ue,l的公式怎么来的,
2.2 Granger-causal Attentive Mixtures of Experts: Learning Important Features with Neural Networks
h a l l = c o n c a t e n a t e ( h 1 , c 1 , h 2 , c 2 , … , h p , c p ) h_{\mathrm{all}}=\mathrm{concatenate}\left(h_{1}, c_{1}, h_{2}, c_{2}, \ldots, h_{p}, c_{p}\right) hall=concatenate(h1,c1,h2,c2,…,hp,cp)
y = ∑ i = 1 p G i ( h all ) ⏟ a i E i ( x i ) ⏟ c i y=\sum_{i=1}^{p} \underbrace{G_{i}\left(h_{\text {all }}\right)}_{a_{i}} \underbrace{E_{i}\left(x_{i}\right)}_{c_{i}} y=∑i=1pai Gi(hall )ci Ei(xi)
a i = exp ( u i T u s , i ) ∑ j = 1 p exp ( u j T u s , i ) a_{i}=\frac{\exp \left(u_{i}^{T} u_{s, i}\right)}{\sum_{j=1}^{p} \exp \left(u_{j}^{T} u_{s, i}\right)} ai=∑j=1pexp(ujTus,i)exp(uiTus,i)
u i = activation ( W i h a l l + b i ) u_{i}=\operatorname{activation}\left(W_{i} h_{\mathrm{all}}+b_{i}\right) ui=activation(Wihall+bi)

说的是 u s , i u_{s,i} us,i是需要学习的vector,值得是针对当前teach需要提取出什么特征。对于 u i T u_i^T uiT指的是对于全部teachs的输出,代表了所有信息,通过Wb提取出当前teach对应的信息。目前理解是这样,还需要对照代码。
代码地址:https://github.com/d909b/ame
3.all_rounder for 语音
背景介绍:
1)单teacher训练
stud训练的目标是降低和老师输出结果之间的KL散度。
L K L D ( θ ) = − ∑ l p t ( l ∣ x ) log p s ( l ∣ x ) L_{K L D}(\theta)=-\sum_{l} p_{t}(l | x) \log p_{s}(l | x) LKLD(θ)=−∑lpt(l∣x)logps(l∣x)
2)多teacher训练
只是将多老师的输出加权起来,仍然作为soft label。
p t ( l ∣ x ) = ∑ k = 1 N w k p t k ( l ∣ x ) p_{t}(l | x)=\sum_{k=1}^{N} w_{k} p_{t k}(l | x) pt(l∣x)=∑k=1Nwkptk(l∣x)
3)我们的模型:
p t ( l ∣ x ) = ( 1 − w h a r d ) p t d ( l ∣ x ) + w h a r d δ t ( l ) p_{t}(l | x)=\left(1-w_{h a r d}\right) p_{t}^{d}(l | x)+w_{h a r d} \delta_{t}(l) pt(l∣x)=(1−whard)ptd(l∣x)+whardδt(l)
teacher是在全数据集上经过了预训练,然后特定领域finetune。
stud训练(没有预训练)的时候,只考虑和他一样domain的老师的输出作为soft label,再加上本身的真值。
4.Distilled Person Re-identification: Towards a More Scalable System
这篇论文重点:adaptive knowledge aggregation
1)teacher知识:
X S = [ x S , 1 , x S , 2 , … , x S , N ] ∈ R d × N \mathbf{X}_{S}=\left[\mathbf{x}_{S, 1}, \mathbf{x}_{S, 2}, \ldots, \mathbf{x}_{S, N}\right] \in \mathbb{R}^{d \times N} XS=[xS,1,xS,2,…,xS,N]∈Rd×N是 { I i } i = 1 N \left\{\mathbf{I}_{i}\right\}_{i=1}^{N} {Ii}i=1N的feature map, 学生网络的相似度矩阵 A s \mathbf{As} As(samples之间的相似度矩阵,对于re-ID来说就是判断对象),
A S = X S ⊤ X S \mathbf{A}_{S}=\mathbf{X}_{S}^{\top} \mathbf{X}_{S} AS=XS⊤XS
where a S , i , j = x S , i ⊤ x S , j in A S is the cosine similarity be tween samples I i and I j \text { where } a_{S, i, j}=\mathbf{x}_{S, i}^{\top} \mathbf{x}_{S, j}\text { in } \mathbf{A}_{S} \text { is the cosine similarity be}\text { tween samples } \mathbf{I}_{i} \text { and } \mathbf{I}_{j} where aS,i,j=xS,i⊤xS,j in AS is the cosine similarity be tween samples Ii and Ij
2)teacher传给stud:
min dist ( A S , A T ) \min \operatorname{dist}\left(\mathbf{A}_{S}, \mathbf{A}_{T}\right) mindist(AS,AT)
dist计算 dist ( A S , A T ) = ∥ log ( A S ) − log ( A T ) ∥ F \operatorname{dist}\left(\mathbf{A}_{S}, \mathbf{A}_{T}\right)=\left\|\log \left(\mathbf{A}_{S}\right)-\log \left(\mathbf{A}_{T}\right)\right\|_{F} dist(AS,AT)=∥log(AS)−log(AT)∥F
log ( A ) = U diag ( log ( λ 1 ) , log ( λ 2 ) , … , log ( λ N ) ) U ⊤ \log (\mathbf{A})=\mathbf{U} \operatorname{diag}\left(\log \left(\lambda_{1}\right), \log \left(\lambda_{2}\right), \ldots, \log \left(\lambda_{N}\right)\right) \mathbf{U}^{\top} log(A)=Udiag(log(λ1),log(λ2),…,log(λN))U⊤
3)多个老师,也是权重不同老师输出,然后优化 min d i s t \min dist mindist。
min Θ S L T ( X S ) = ∥ log ( X S ⊤ X S ) − log ( A T ) ∥ F 2 \min _{\Theta_{S}} L_{T}\left(\mathbf{X}_{S}\right)=\left\|\log \left(\mathbf{X}_{S}^{\top} \mathbf{X}_{S}\right)-\log \left(\mathbf{A}_{T}\right)\right\|_{F}^{2} minΘSLT(XS)=∥∥log(XS⊤XS)−log(AT)∥∥F2
4)权重判断
Du和DL里面没有相同的identity,【DL里面identity相同的两张图(a,b)的距离】要比【(a,随便从Du抽一张图)的距离】要大。
L V E R ( X S U , X S L ) = ∑ ( i , j ) ∈ P L − log exp ( x S , i L T x S , j L ) exp ( x S , i L ⊤ x S , j L ) + ∑ k = 1 N exp ( x S , i L ⊤ x S , k U ) L_{V E R}\left(\mathbf{X}_{S}^{U}, \mathbf{X}_{S}^{L}\right)=\sum_{(i, j) \in \mathcal{P}_{L}}-\log \frac{\exp \left(\mathbf{x}_{S, i}^{L T} \mathbf{x}_{S, j}^{L}\right)}{\exp \left(\mathbf{x}_{S, i}^{L \top} \mathbf{x}_{S, j}^{L}\right)+\sum_{k=1}^{N} \exp \left(\mathbf{x}_{S, i}^{L \top} \mathbf{x}_{S, k}^{U}\right)} LVER(XSU,XSL)=∑(i,j)∈PL−logexp(xS,iL⊤xS,jL)+∑k=1Nexp(xS,iL⊤xS,kU)exp(xS,iLTxS,jL)
因为没有真值,找了一个分布一致性作为真值。通过样本类别不同,来近似的圈出不同teacher的贡献度。
Adaptive Knowledge Aggregator. 对于超参数的确定,本来stud直接跟着老师的步伐走,是通过验证集标签集合的粗分类情况来调整超参数。
过程:老师结果作为真值(因为没有真值)来更新学生参数,验证集上结果来更新超参数。论文里说的却是倒过来的。
5.Amalgamating Knowledge towards Comprehensive Classification
过程:
1)feature amalgamation:input到teachers网络,得到的feature map拼接起来作为stud的feature map。
2)parameter learning:layer1->layer2,知道输入输出,训练网络参数。但是输入输出都是double-size,通过自编码器实现降维。
总结:
1)teachers的所有输出都是直接concat,包括最后的softmax 分类结果。
2)loss包括teachers的自编码误差,和每层学生输出和老师输出之间误差,和最后结果之间的误差。
6.Ensemble Knowledge Distillation for Learning Improved and Efficient Networks
这篇文章感觉质量不是很高。没有投到任何顶会。写作还是比较流畅的(我能学到一些表达)

总体思路:
stud有Ns个分支,每个分支的模型都是3层dense layer(中间加的有pooling等操作)。
而teacher网络是选的主流网络,( we considered up to 7 sub-networks based on ResNet14, ResNet20, ResNet26, ResNet32, ResNet44, ResNet56, and ResNet110 architectures).
loss是stud每个分支和每个teach对应的输出KL散度。还有teach在当前数据集的失败率(with真值)。还有stud自己在当前数据集的失败率(with真值)。
这个模型不够简洁。也很意外的出现了训练老师的情况。我不打算训练老师了。
7, 对于esim的深入理解
感觉论文并没有很深入的探讨。
基本公式我也记得差不多了,
参数,第一层lstm,第二层的mlp,第三层的lstm和mlp,
8.老师新给的文章:
progressive teacher-student learning
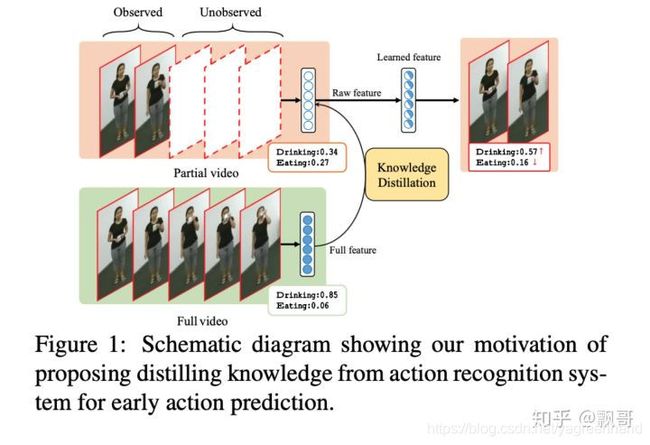
希望通过完整视频的学习提升部分视频的学习,在行为预测中需要对部分视频的行为进行分析和识别。
本文实验证明了完整视频的动作信息是可以用来蒸馏来提升行为预测的。
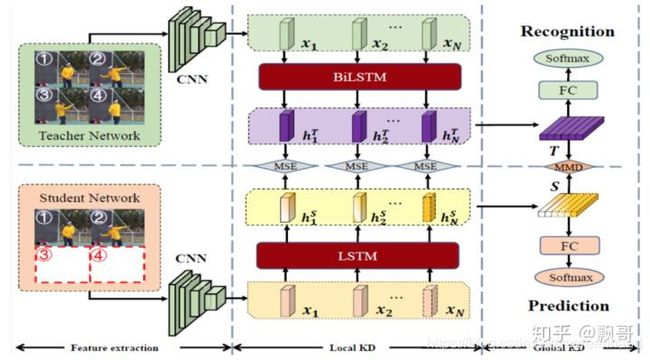
teacher网络用双向的lstm建模,student网络用单向的lstm建模,这么设计的原因是可以正向和反向推导完整的视频,但是不完整的视频未来的信息我们是不清楚的,所以只能单向的去预测。
本文设计的teacher-student learning是两个不同任务的一个信息蒸馏。Teacher是行为识别的任务,student是行为预测的任务,这是一个跨任务的信息蒸馏。


总的loss:
L = 1 I ∑ i = 1 I ( L C ( S i , y i ) + L T S ( S i , T i ) ) L=\frac{1}{I} \sum_{i=1}^{I}\left(L_{C}\left(\boldsymbol{S}_{i}, \boldsymbol{y}_{i}\right)+L_{T S}\left(\boldsymbol{S}_{i}, \boldsymbol{T}_{i}\right)\right) L=I1∑i=1I(LC(Si,yi)+LTS(Si,Ti))
stud和teach中间层的知识传递:
ere, S i Si Si and T i Ti Ti are two D × N D × N D×N-sized matrices. D D D是feature 维度, N N N is lstm的层数(the total number of progress levels used for early action prediction),
是直接每层的 h i h_i hi取一个加权平均,因为每个阶段的输出贡献可能不同。
最终层的loss想直接抄过来。