python爬取学校教务管理系统
写这个爬虫的缘由
以前用java写过一个爬取学校的教务系统的爬虫 https://blog.csdn.net/ygdxt/article/details/81158321,最近痴迷Python爬虫,了解到许多强大的库,想再一次用学校的教务系统做下测试。
这一次我首先想到的是新的教务系统,这个难度更大,因为有了验证码识别反爬,由于我是用的tessocr库识别验证码,(具体配置过程可以参考我之前的博客 python填坑之路:tesserocr配置)
用Requests.get方法把验证码下载下来识别之后,同时因为我爬取网页是用的selenium做的模拟网页动作,这里就有一个同步性的问题,不能保证selenium请求网页上的验证码和requests请求的验证码是同一个,相当于selenium、requests分别请求了一次登陆网页,两个网页上的验证码显然是不同的。所以
怎么保证请求登录界面得到的网页上的验证码
和我们请求验证码服务器返回的验证码是同一个验证码是同一个是一个很迷人的问题,
我开始还以为可以从网页源代码上直接定位到这个验证码,结果显示这个验证码在登录界面的
的存在形式不是一个..png/jpg,而是通过src=“验证码服务器”来实现异步加载
同时,由于tessocr识别验证码的成功率可能只有50%,要提高验证率可能还要对接云打码,果断放弃了爬取新教务系统的想法,还是爬取原来的没有验证码的旧教务系统,
其实新旧教务系统最大的区别就是登陆界面不一样,登陆之后都一样,貌似用了重定向
ps:如果你对这个问题有什么好的解决办法,请不吝赐教
编码过程
详细的代码解释就看注释吧,有什么问题欢迎交流
执行爬虫的主程序csu.py,里面有许多测试用的注释代码,就不删了
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.select import Select
from config import *
import time
broswer = webdriver.Chrome()
wait = WebDriverWait(broswer, 10)
def search():
try:
broswer.get("http://csujwc.its.csu.edu.cn/jsxsd/kscj/yscjcx_list")
account = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#userAccount"))
)
password = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#userPassword"))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#btnSubmit"))
)
except TimeoutException:
return search()
#登录
account.send_keys(ACCOUNT)
password.send_keys(PASSWORD)
submit.click()
#进入我的成绩界面
my_score = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,"body > div.wap > a:nth-child(3) > div"))
)
my_score.click()
#成绩和平均分
# my_rank = wait.until(
# EC.presence_of_element_located((By.CSS_SELECTOR, "#LeftMenu1_divChildMenu > ul > li:nth-child(4) > a"))
# )
# my_rank.click()
#
# rank = wait.until(
# EC.presence_of_element_located((By.CSS_SELECTOR, "#dataList > tbody > tr:nth-child(2) > td:nth-child(3)"))
# )
# #http://www.w3school.com.cn/cssref/selector_nth-child.asp nth-child(n)的用法
# average_score = wait.until(
# EC.presence_of_element_located((By.CSS_SELECTOR, "#dataList > tbody > tr:nth-child(2) > td:nth-child(4)"))
# )
#
# print('您的平均成绩是:'+average_score.text+"\n排名:"+rank.text)
#逐次展示 我的成绩八个子项
# css_selector = "#LeftMenu1_divChildMenu > ul > li:nth-child({0}) > a"
# for i in range(8):
# # 将滚动条移动到页面的顶部
# js = "var q=document.documentElement.scrollTop=0"
# broswer.execute_script(js)
# time.sleep(2)
#
# aviable_score = wait.until(
# EC.presence_of_element_located((By.CSS_SELECTOR, css_selector.format(str(i+1))))
# )
# aviable_score.click()
#
#
# #将滚动条移动到页面的底部
# for j in range(8):
# js="var q=document.documentElement.scrollTop="+str(j*200)
# broswer.execute_script(js)
# time.sleep(1)
#处理select https://www.cnblogs.com/imyalost/p/7846653.html
yxcj = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#LeftMenu1_divChildMenu > ul > li:nth-child(1) > a"))
)
select_score_element = broswer.find_element_by_css_selector("#xnxq01id")
select_score = Select(select_score_element)
#得到下拉列表的所有子项
select_score_items = broswer.find_elements_by_css_selector("#xnxq01id option")
select_score_items_text = []
for item in select_score_items:
select_score_items_text.append(item.text)
#print(item.text)
scores_dic = {}
for i in range(len(select_score.options)):
#不加这两行会报错,原因: https://blog.csdn.net/ulebo/article/details/52128033
print("*****************************************************"+select_score_items_text[i]+
"*****************************************************")
select_score_element = broswer.find_element_by_css_selector("#xnxq01id")
select_score = Select(select_score_element)
select_score.select_by_index(i)
time.sleep(1)
score_table = broswer.find_element_by_css_selector("#dataList")
data = score_table.text.replace("+","")
data = data.split("\n")
datalist = []
for line in data:
datalist.append(line.split())
scores_dic[select_score_items_text[i]] = datalist
return scores_dic[select_score_items_text[0]]
def main():
search()
if __name__ =="__main__":
main()
ui.py程序的gui,直接运行这个就好,它会调用csu.py
#coding=utf-8
import wx
import wx.grid
import csu
class UI(wx.Frame):
def __init__(self):
wx.Frame.__init__(self,parent=None,title="成绩查询",size=(1050,560))
grid = wx.grid.Grid(self,pos=(10,0),size=(1050,500))
grid.CreateGrid(100,9)
for i in range(100):
for j in range(9):
grid.SetCellAlignment(i,j,wx.ALIGN_CENTER,wx.ALIGN_CENTER)
grid.SetColLabelValue(0, "序号") #第一列标签
grid.SetColLabelValue(1, "初修学期")
grid.SetColLabelValue(2, "获得学期")
grid.SetColLabelValue(3, "课程")
grid.SetColLabelValue(4, "成绩") # 第一列标签
grid.SetColLabelValue(5, "学分")
grid.SetColLabelValue(6, "课程属性")
grid.SetColLabelValue(7, "课程性质")
grid.SetColLabelValue(8, "获得方式") # 第一列标签
grid.SetColSize(0,50)
grid.SetColSize(1,100)
grid.SetColSize(2,100)
grid.SetColSize(3,350)
grid.SetColSize(4,50)
grid.SetColSize(5,50)
grid.SetColSize(6,50)
grid.SetColSize(7,100)
grid.SetColSize(8,100)
grid.SetCellTextColour("NAVY")
data = csu.search()
data.remove(data[0])
print(data)
for i,item1 in enumerate(data):
for j,item2 in enumerate(item1):
grid.SetCellValue(i,j,data[i][j])
pass
app = wx.App()
frame = UI()
frame.Show()
app.MainLoop()
想要运行代码,具体的配置过程请参考readme
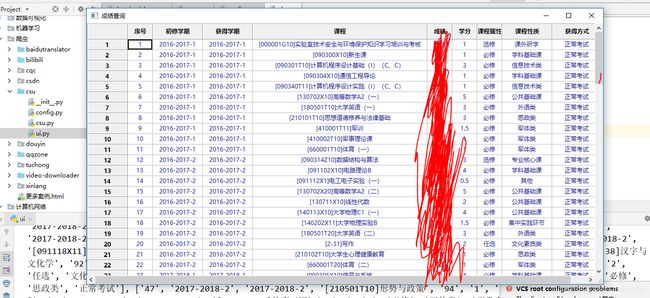
运行结果预览