springboot小而美博客学习笔记
#框架搭建
用springboot初始化工具,选模块(web,thymeleaf,jpa,mysql,Devtools,Aspects(日志处理)),等待,第一次时间较长,能干一下午也是正常的。
先逛逛pom文件,这里可以导依赖,管理版本。
配置文件,有两种(property,yml),这里用yml。
以下目录结构,第一个是总配置,里面可以定义thymeleaf,以及在什么环境下选下面(application-dev,application-pro)哪种的配置,是生产环境还是开发环境,这对于日志的打印级别是不同的。对于application-dev,application-pro这两个文件,自然就是开发时,生产时的配置。最后一个文件时,自定义一些打印日志的规范,可打破默认的10m大小的限制。
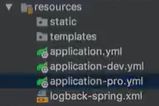
application:
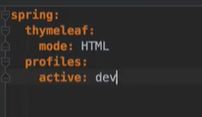
application—pro:
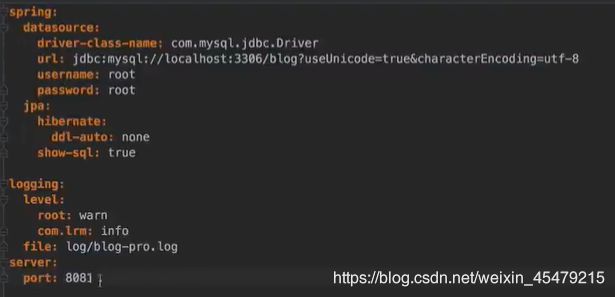
application—dev:
#异常处理
定义404,500,error这些错误页面,springboot会根据错误状态码去跳转到对应的文件。
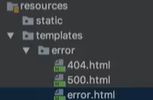
新建控制器,来调试这些错误页面,如果跳转不到500页面,把property文件thymeleaf那两行去掉即可。
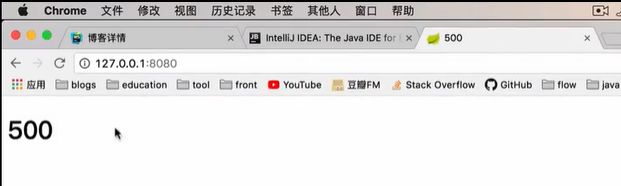
显然,控制器内的代码有问题,分母不能为零,这会报一个500错误,因为这是服务端的错误;
如果,在浏览器里瞎打一个网址,显然会找不到,所以自然就会报一个404.
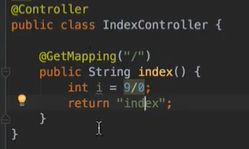
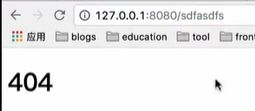
自定义错误页面,自然要自建拦截器。
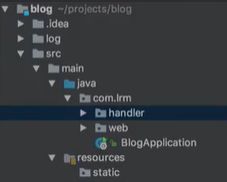
这样一个处理器,通过ModelAndView,把路由和异常信息,以及自定义的错误页面路由都设置好。
![]()
这是日志信息的格式。
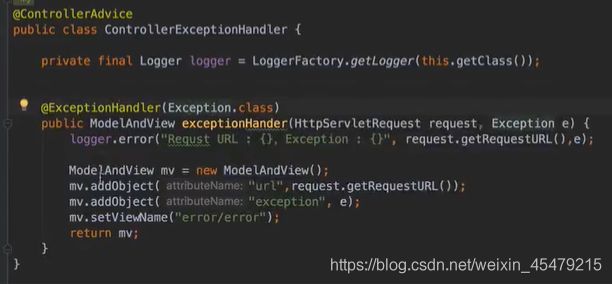
那在错误页面里怎么打印错误信息呢?当然,用thymeleaf模板来处理前端最合适不过了。
下面,就能使错误信息以纯文本的格式来打印。
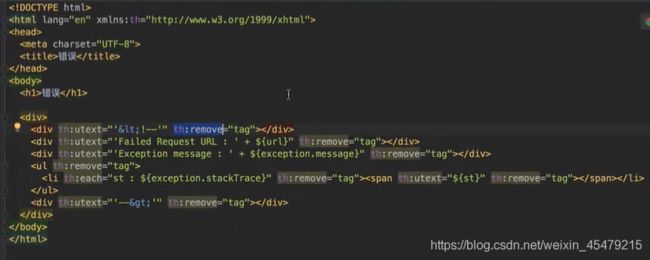
为了更好的实现,我们自己要定义异常,以及抛出异常。
自定义异常,并设置状态为找不到资源(HTTPStatus.NOT_FOUND),即会报404错误。
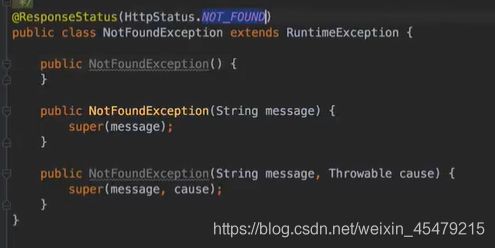
再看一下控制器,抛出异常:
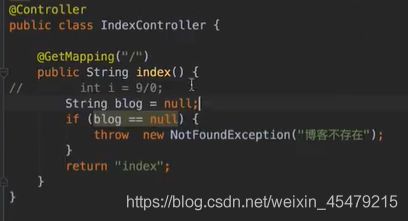
当然,之前我们做了异常拦截器,这个东西会把所有的异常都跳到我们自定义的error页面,so,我们还要做点逻辑的判断,判断下状态码,不为空的话,就抛出异常。
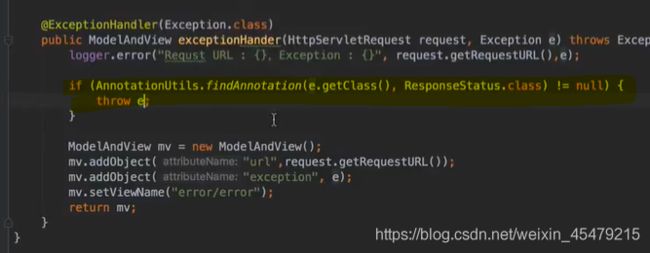
#使用AOP作日志处理

以切面的方式,更爽,分为前后,创建aspect包。既然是Aop,肯定要加注解(aspect,component),来和普通类分别开。
做一个切面类,拦截下所有controller下的请求。也分三个阶段,前,后,最后,这有点像钩子函数,也就是前端的生命周期函数,都是定义好的且有规定的执行顺序的功能函数。
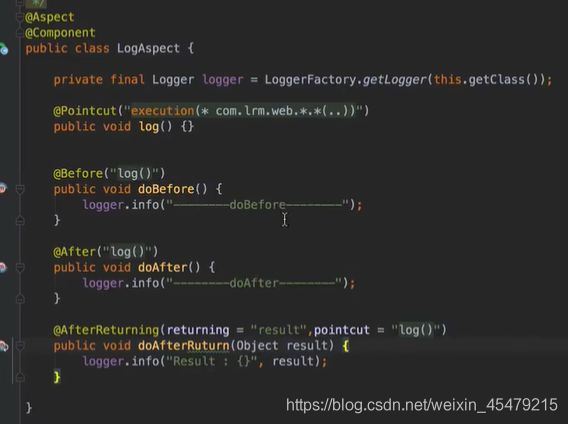
先完善before,request获得ip和url,joinPoint对象获取类名,方法名,参数。在通过自定义的类,把这些值都传进去:
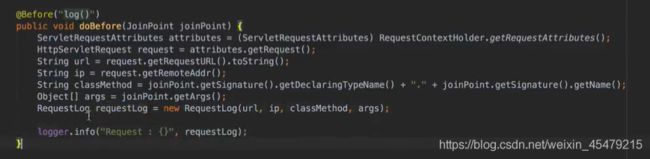
自定义的类:请求封装为一个类
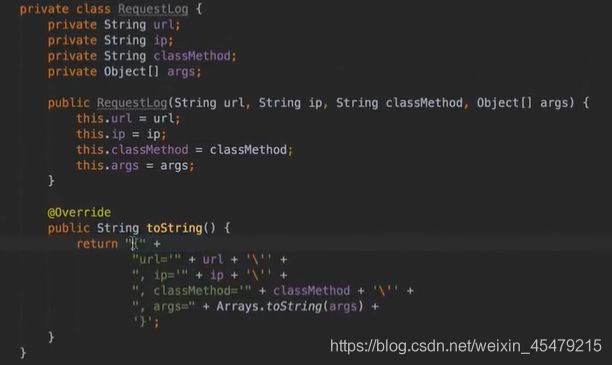
完善剩下的两个:
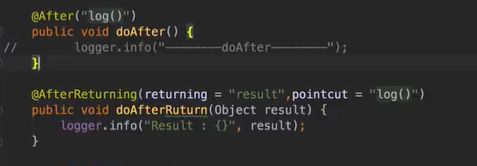
看一下控制器:
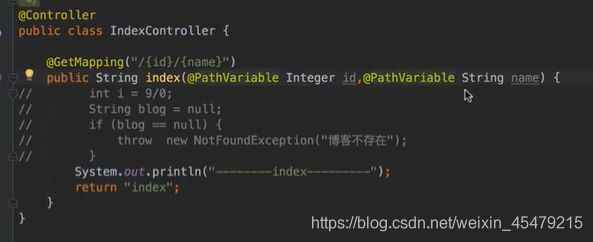
最终的日志效果,可以看到我们想要的信息了:

#页面处理

1.首先,前端文件导入idea,将前端页面整合成符合thymeleaf规范的形式,(即最外层包名为templates,将其他文件都拉入其中)。最后把static也copy进去。
2.布局,修改一些资源引入的格式(link标签里的自定义css,以及一些js的引入,cdn的话不用管,因为是一些网络地址,网络上的都ok,也就是相对路径都需要处理),因为,要符合thymeleaf引擎的语法。利用fragment定义一些公共的页面,类似flask里的layout。写一个文件_fragment.html,里面都是一些片段。
也可以接受参数,例:th:replace表示替换整个html元素,这样就可以使得每个页面的标题都会变。
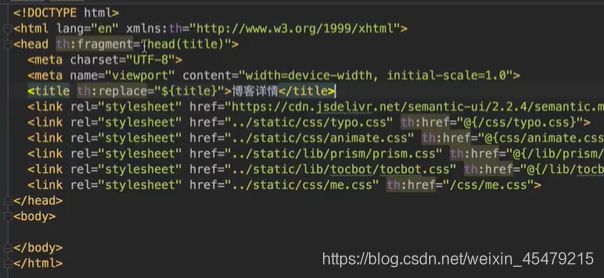
再看看具体页面的使用,这里以首页为例(~{::title})表示传入title这整个元素:

对于,th:classappend,这个的作用是在class后面能添加信息,这里是添加active,这样在点到哪个页面的时候,哪个页面就会显示激活的状态,当然,要做下判断,根据n的值,才知道是具体的哪个页面。
传入n:
![]()

通过以下方式可实现,在模板引擎里有效,在html里是注释:
3.美化,向错误页里添加footer,以及头部导航,不能只显示一个div,不然太low。
看下中间的:
美化后:

#实体类的设计
以对象来驱动。

关系:即一对多,多对多。一个用户可以写多个博客…,建立关系后,知道一个,就可以取到另一个的值。
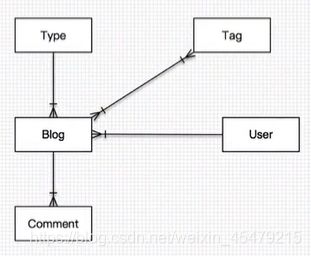
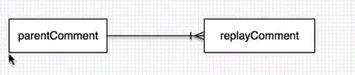
比较特殊的:自关联(评论实体类)。
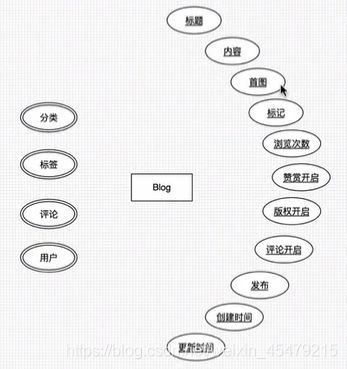

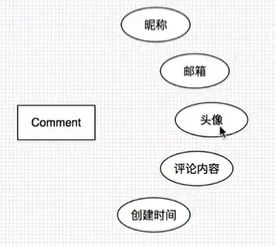
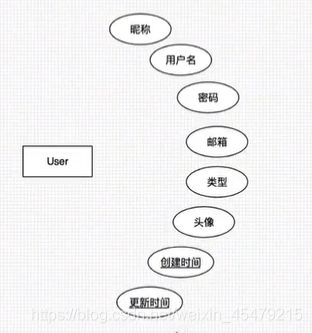
分层思想:web相当于controller层,然后,一层往下调下一层。
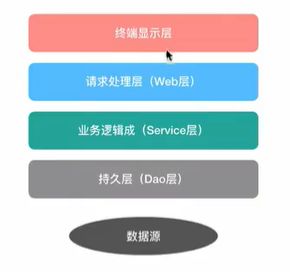
当然,做一个稍微规模大一点的项目,我们肯定要和别人合作完成,就算是一个人,也是需要一点约束的,即方法的命名约定:

具体实现:新建po包,在下面编写实体类。
blog实体类:需要两个注解,@Entity使该类具备和数据库映射的能力,@Table定义表名
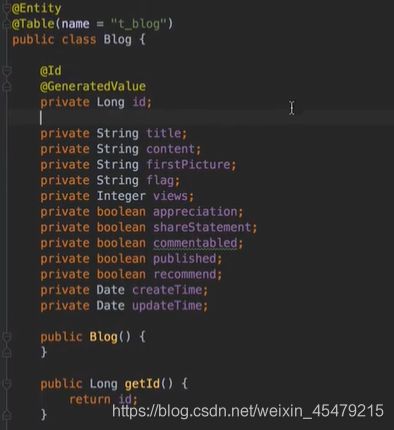
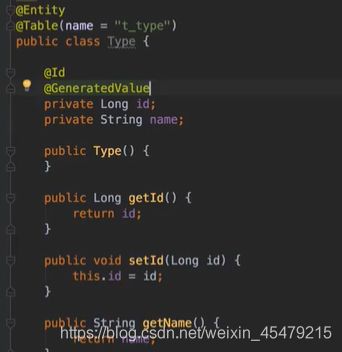
type:
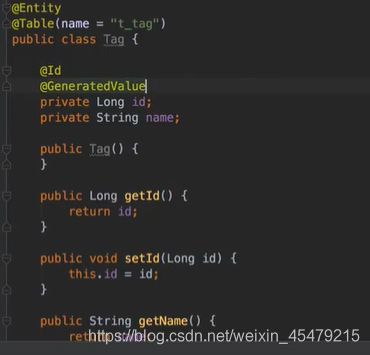
Tag:
Commit:

User:
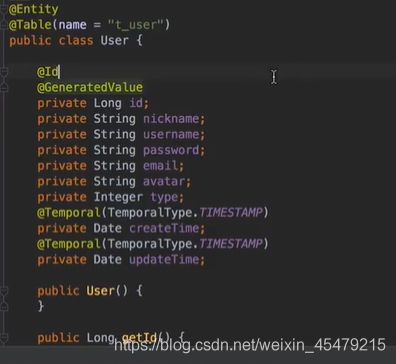
写完类,再这些实体类之间的处理关系:
many的一端作关系维护端,比如博客与类型之间的关系:多对一。
blog端:维护端。
![]()
type端:被维护端。

对于多对多关系:要添加级联功能,即新增一个博客是否新增一个标签。
![]()
![]()
对于自关联的评论,这两个语句都写在一个实体类里:
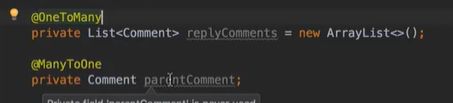
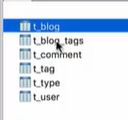
虽说五个类,但是却六张表,有一张是多对多的中间表:
#后台登录

登录页面:copy semantic里自带的登录页面,若找不到的话,随便copy一个登录页面就可。
登录之后进入一个博客列表的页面:后台首页
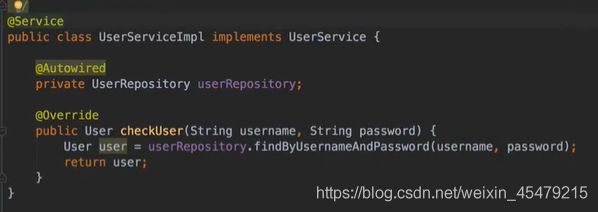
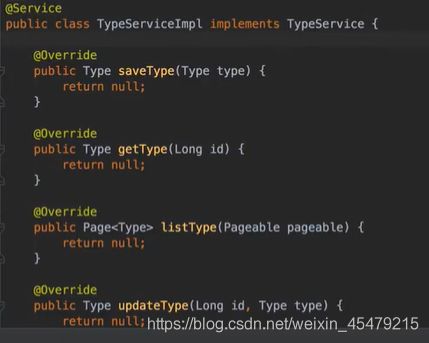
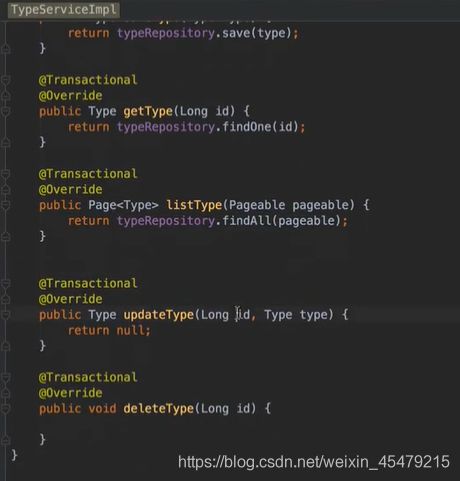
完善service包下的接口,先新建一个包service,包下建UserService这个接口,并配置实现类UserServiceimpl:
![]()

完善Dao(使用jpa),继承JpaRepository:jpa可根据名字产生对应功能的sql语句,尿性很强

编写controller:注意,这里在向前端发送message时,不能用model,因为下面重定向的话,要用addFlashAttribute(下面两图在同一个控制器内)
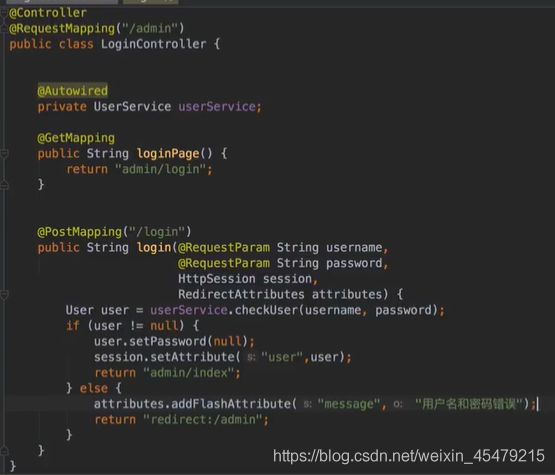
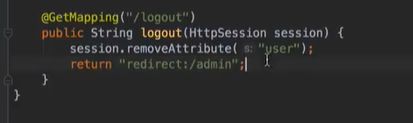
对于login页面的form表单的非空验证:
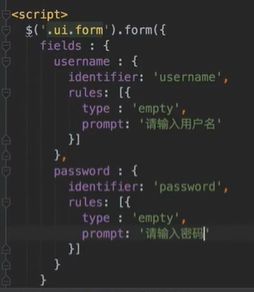
编写登录错误的提示:negative是红色的
![]()
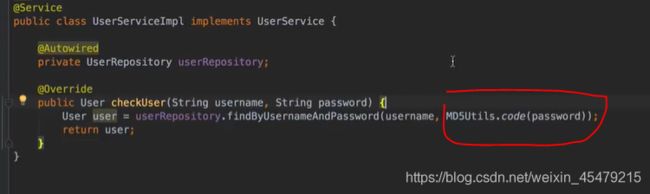
MD5加密
新建一个工具类的包util,编写MD5Utils类:

应用在serviceimpl:
拦截器(登录后才能访问首页)
判断session,没有的话重定向到admin
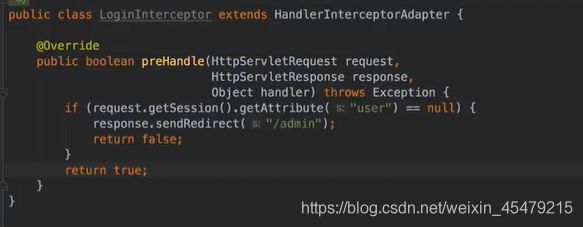
注册拦截器,并告诉拦截器哪些路径要拦截,哪些不能拦截,不然连登录和提交登录信息的页面都进不去的话,项目显然是玩不成的。
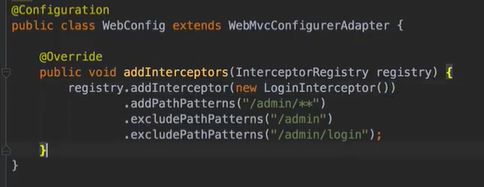
分类管理

前端页面
types:
type-input:添加种类

service:每个调用dao的都封装成一个事务@Transactional,那什么是事务呢,传统的理解是和数据库相关,通俗的理解,事务是一组原子操作单元,从数据库角度说,就是一组SQL指令,要么全部执行成功,若因为某个原因其中一条指令执行有错误,则撤销先前执行过的所有指令。更简答的说就是:要么全部执行成功,要么撤销不执行。
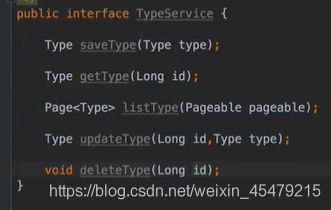
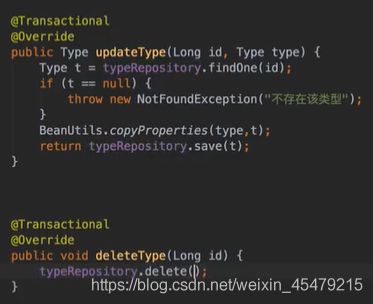
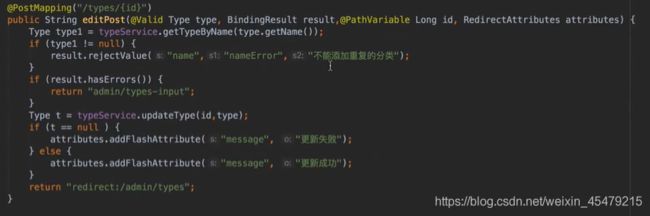
更新的话,要用BeanUtils里的方法copy下,再保存即可。
对于javabean,最直观的理解:属性只能用方法设置或使用
1 、 所 有 属 性 为 p r i v a t e 2 、 提 供 默 认 构 造 方 法 3 、 提 供 g e t t e r 和 s e t t e r 4 、 实 现 s e r i a l i z a b l e 接 口 1、所有属性为private 2、提供默认构造方法 3、提供getter和setter 4、实现serializable接口 1、所有属性为private2、提供默认构造方法3、提供getter和setter4、实现serializable接口
pojo就是一个普通的javabean。
Dao:

Controller:
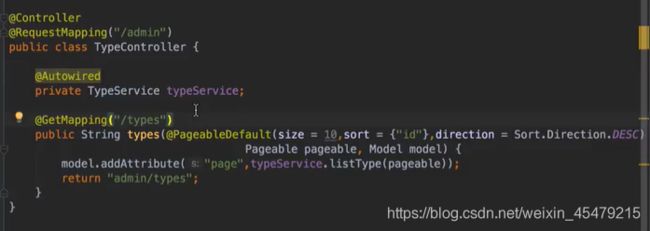
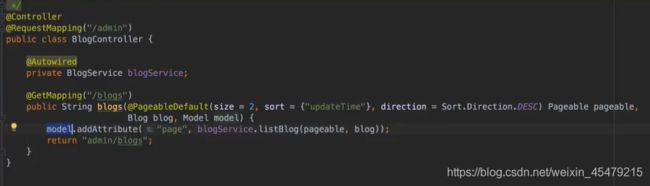
穿进去的pageable这个对象可以设置每一页显示多少条数据等一系列的配置

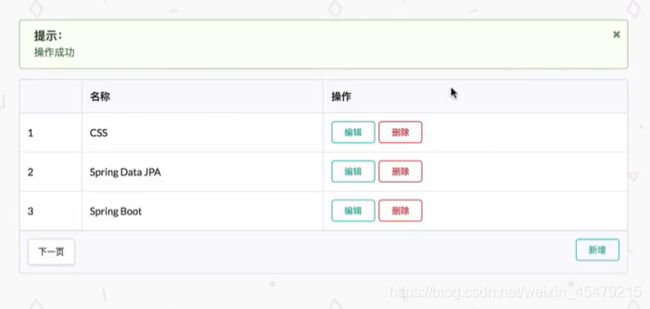
若t为空,则说明没有使用saveType这个函数,原因是已存在对应的内容(重复的)
分页对象:page对象的格式,数据库的数据传到前端是以下的json格式。
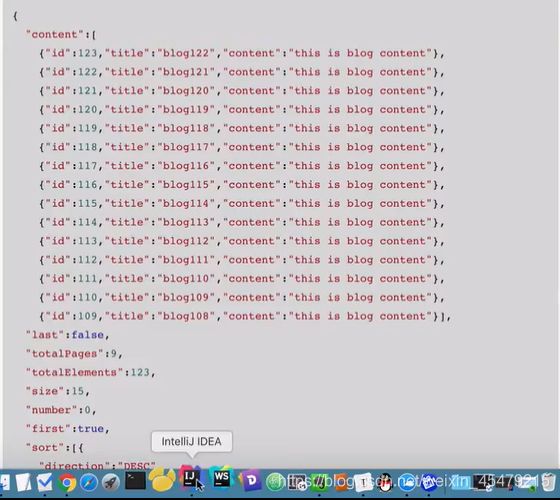
前端显示数据,循环显示,对相应的操作配置路由:
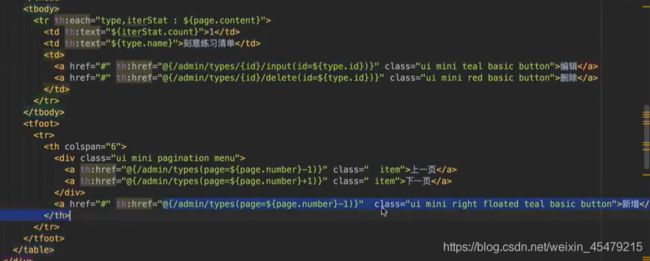
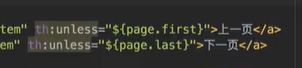
如果不是第一页,则显示上一页;反之,若不是最后一页,则显示下一页:
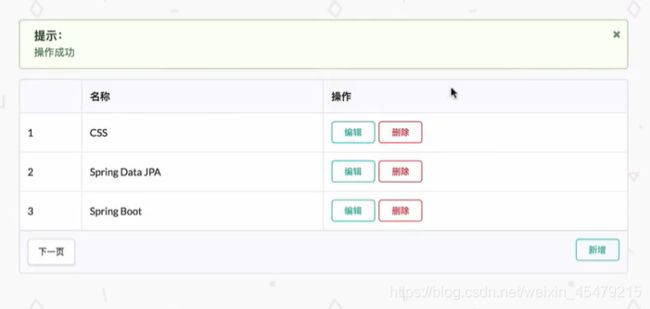
新增功能:不能重复添加分类
提示信息:close icon 删除图标
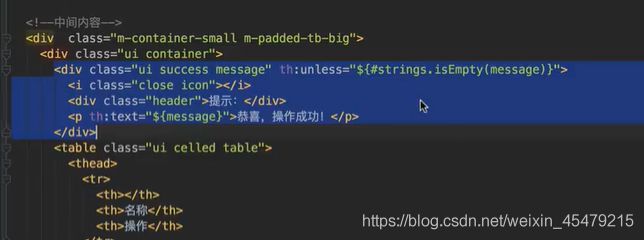
那怎麽弹出错误信息呢?其实也不难,用注释可以解决。
注释的作用:对html来说是纯注释,但对thymeleaf来说,是完全可以解析的,所以,用来隐藏错误信息是最合适了。
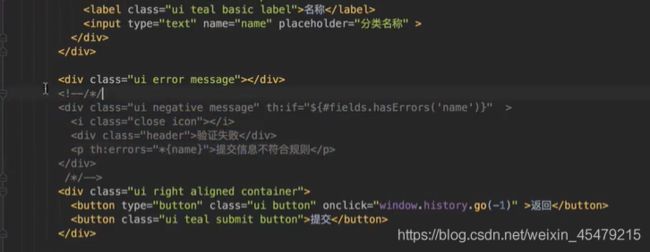
更新分类:
删除功能:

#博客列表
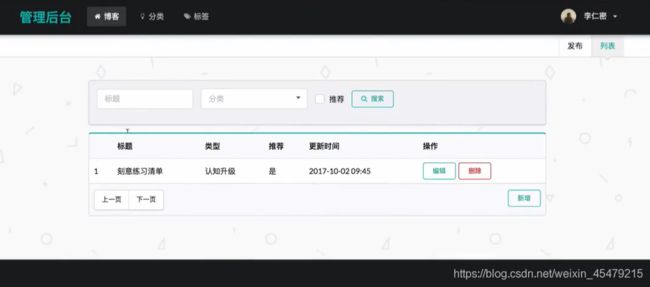
service:
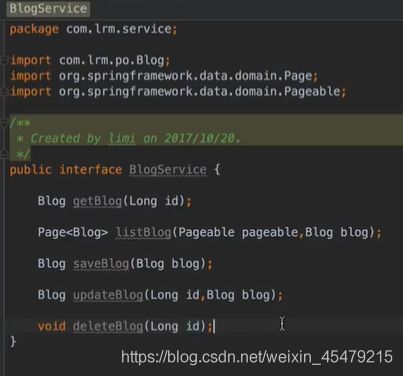
impl:
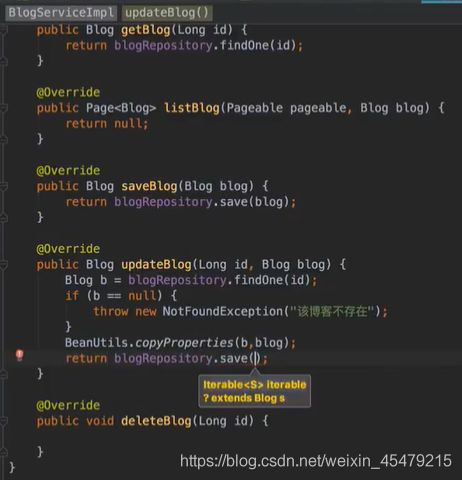
dao:

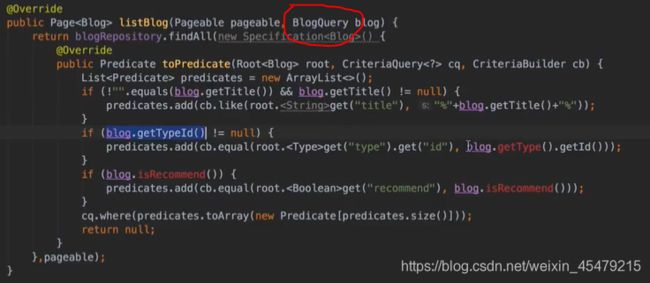
**动态查询:**根据条件来组合。
1.继承jpa的一个类

2.修改impl,cb构建,cq查询,根据我们的拼接自动生成对应的sql语句
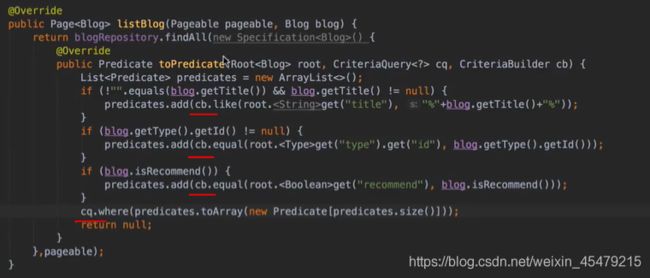
controller:

前端:可以借鉴分类
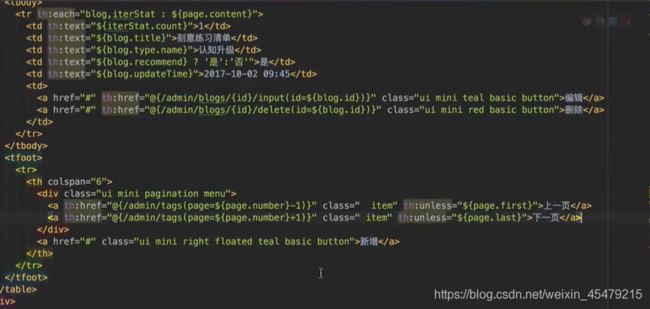
这里的上一页,下一页需要再处理一下,th:attr,可自定义属性

对应的js方法:

这里也有个问题,每次输入条件查询时,整个页面都会刷新,会导致输入框内的信息也都清空,而且,性能上也会降低。所以,这里用局部页面刷新**(ajax)来解决这个问题,只刷新下面的查询结果。这里用thymeleaf的片段来实现**。
编写js方法,去请求/admin/blogs/search这个控制器里的方法,到达局部刷新的目的(即只提交blog-list片段),分页的时候调用loaddata。
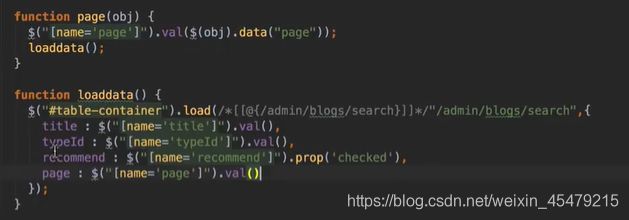
搜索按钮:id=“search-btn”
![]()
js:也是一样的加载数据
在idea里直接使用数据库也是很方便:输个用户名密码啥的
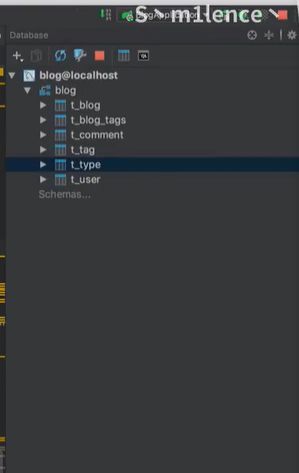
我们直接在渲染页面的时候,就把查询好的数据返回过去,即返回一个含有所有种类信息的列表:
![]()
前端循环展示:

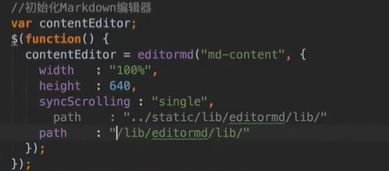
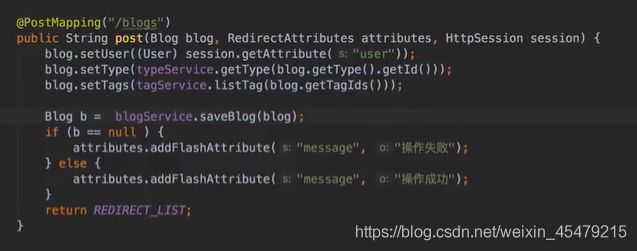
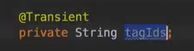
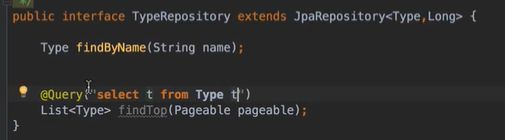
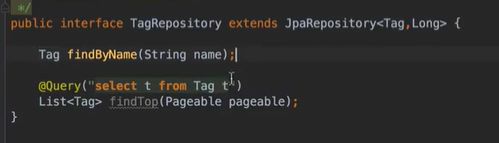
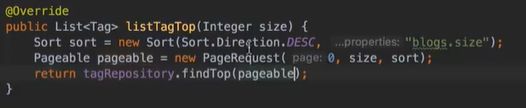
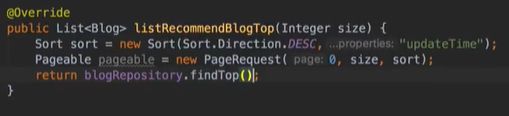
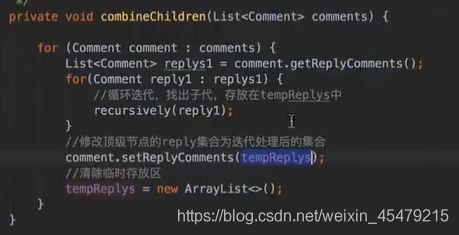
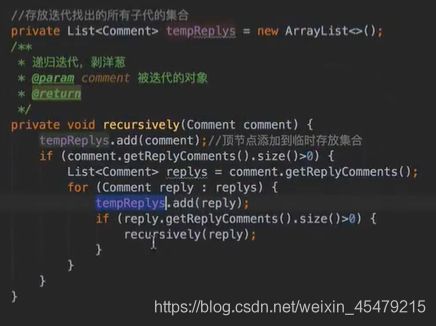
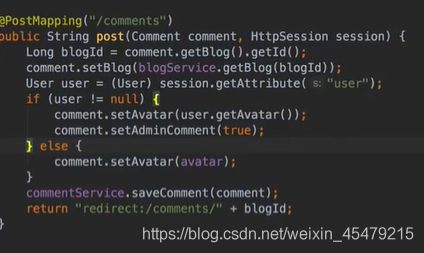
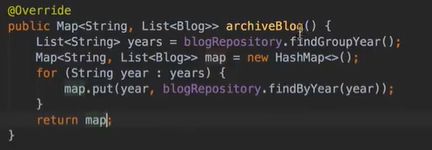
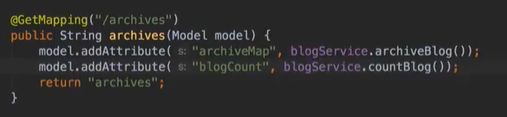
vo(传值对象):专门用于传递值,其对象属性种类数 专用于博客查询的对象: 直接从查询对象来解释。 引入一些公用的组件,一些js,css。 保存和发布按钮的js: 对相关字段的校验:必填 定义大写常量,增强代码可读性: 初始化md编辑器: 添加博客的controller: @Transient:表示该字段不会和数据库对应 在添加文章时,后台要自己为用户写的文章设置时间,浏览次数: 由于文本内容需要很长,所以我们把这个属性定义为大字段类型,对应到数据库是longtext类型。 清除按钮:点一下,框里的种类信息就会清零 对于标签,由于一个文章可以有多个标签,所以把这些id封装为一个数组: 根据id,进入博客编辑页面,并且携带这个id对象的一些值(标题,内容)传入。其实这个页面和新建文章页面是共用的。前端接受这个id对象,把值赋到对应的地方。 初始化,将标签都先转为字符串:传过去标签id 支持自定义标签: controller:向前端发送分好页的博客列表,种类和标签的top榜。 博客首页,种类的top榜: 业务层: dao: 博客首页,标签的top榜 标签dao层实现接口方法: 业务层的实现:构造sort对象,规定每页尺寸,取第一页(page:0) 推荐博客: 先写底层dao:根据更新时间,选最新的,并且是允许推荐的。 service:请求分页,和之前的套路一样。 controller:提交model,取八条数据。 日期格式化: 传递“上一页”,“下一页”参数: 显示top榜的种类数量,因为一对多的关系,一个种类对应多个文章,也就是对应一个数组,用arrays.length()求长度,即该种类的文章数量。 新建search.html: 搜索框用form表单包裹:用于提交信息到search页面,跳转新页面。写上name,相当于为信息配一个key值。 dao:使用jbq语句like查询,?1表示传入第一个参数 sercice实现: controller:提交查询结果page,并把插叙语句query保留在搜索框,知道自己查的啥,以及插叙的结果。 前端展示:搜索框里保存查询语句。 根据博客id来进入详情页,用thymeleaf的语法来整改整个页面。 这里用个md转html的小插件: 为了保持原数据的安全性,我们新建一个b对象,把要改的copy给b即可,并将md转为HTML。 controller:实现详情页功能。 子父类循环嵌套 校验非空:当点击按钮时触发校验。 提交内容,后续清空,添加回滚功能:commentId=-1说明没有父对象,是最顶层评论对象。 实现:1.根据对应的博客id返回相应的评论列表;2.添加评论,只要该父评论id不是-1,说明不是顶层评论,那么,就绑定该评论并设置时间。 controller:第一个实现局部刷新;第二个实现添加评论 评论信息列表展示:加载完页面,就加载评论列表 评论的层级关系:只要两级关系,级别太多不合适,只要根节点是小白,其他所有评论都是同层关系。 凡是顶级的评论,父评论id都为空,我们先把第一层(顶级评论)的数据拿出。 把顶级评论下的所有一级子级评论都做循环迭代。 将第一个子节点放入迭代器,把所有子评论都存放在tempReplys这个集合中,这样所有评论都是同级关系了。 实现@某人的效果: **管理员回复:**和普通访客区别,首先,从session里判断是否有用户,若有则是管理员(因为管理员才能登陆)。首先,要登录后台管理系统,这样前端就能从session里取值。 controller: 前端:判断类型id是否一致,若一致,则追加一个teal的样式。 专门构建一个tagid的查询方法:关联查询。 前端看代码,也之前的类似。 查出所有数据的年份,再分组排序一下 service: 自定义jpq语句:实现和sql一样的功能 根据年份查博客列表: controller调用业务获得service返回的map,并获得博客总数: 对应的前端展示,直接看代码,也没啥分析的。 做一个静态页面,页面引入头部,footer,标题,这些都在_fragment.html页面里定义好的,之后写controller 底部可显示最新博客,并且,点击可进入 js向controller请求数据,返回到newblog-container 数据返回到_fragment下的newblogList片段 ;在message.properties里,配置邮箱及qq信息;以及在i18n文件夹里国际化信息
#博客新增



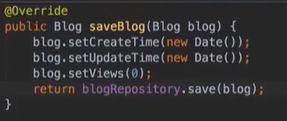

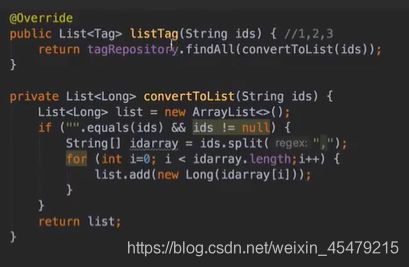
![]()
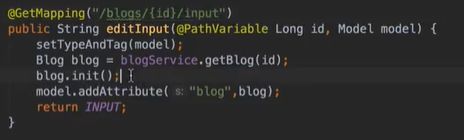
#博客编辑
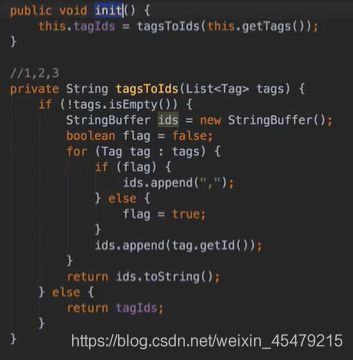
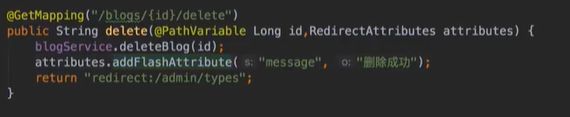
#删除

#前端展示
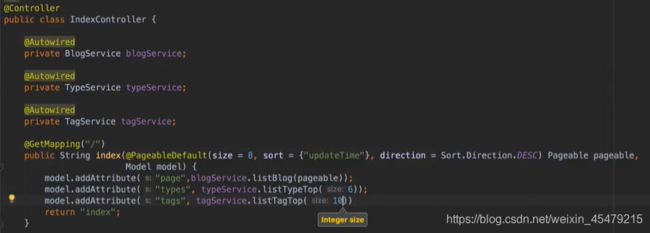
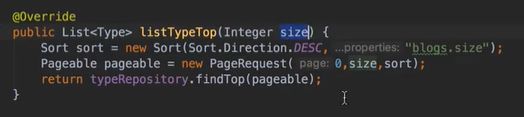


![]()


#前端首页的全局搜索
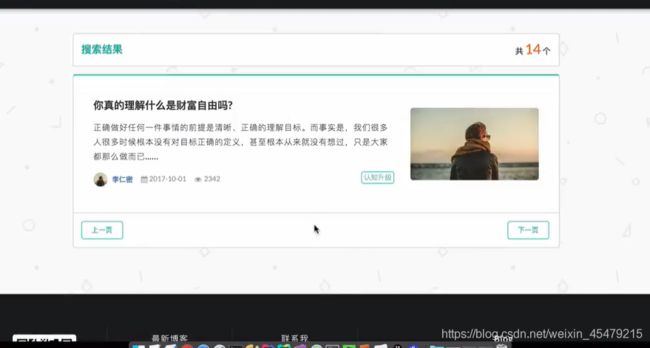

![]()



#详情页



#评论功能

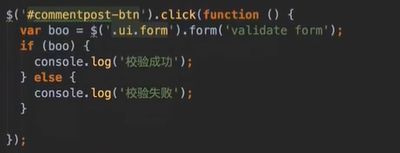
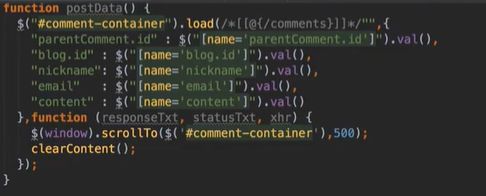
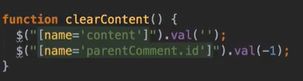
回复功能:给个提示 @XXX,表示回复谁的信息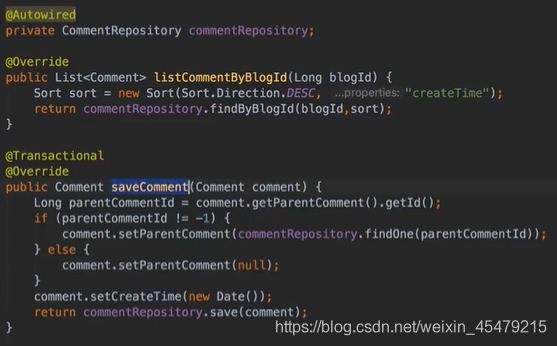
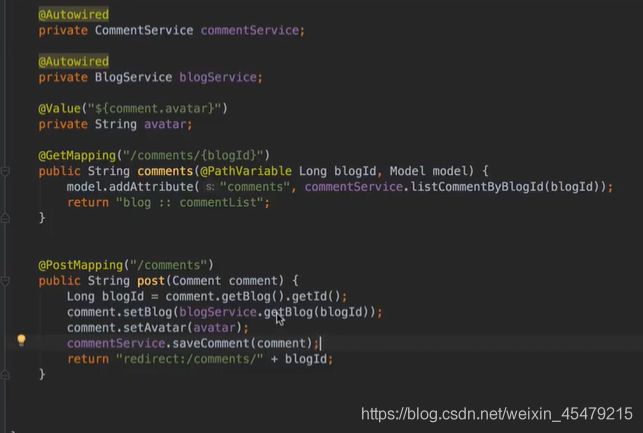
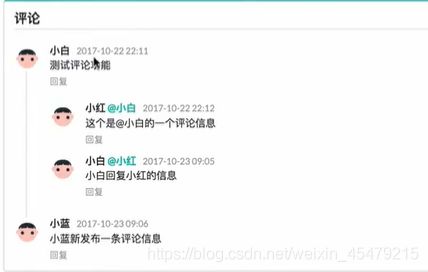


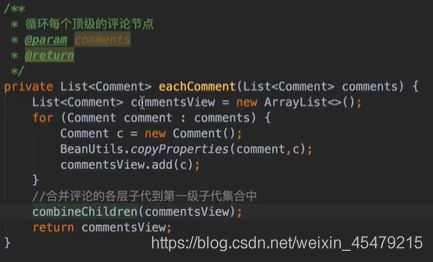
![]()
#更新浏览次数
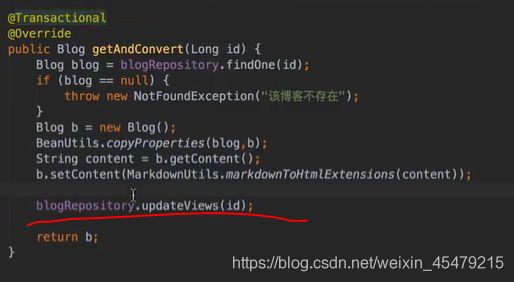

#博客按分类展示
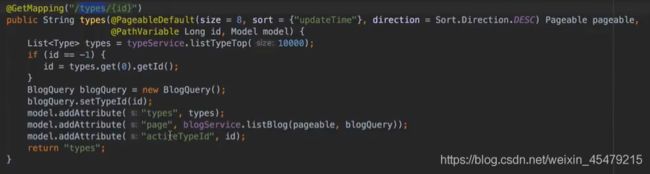
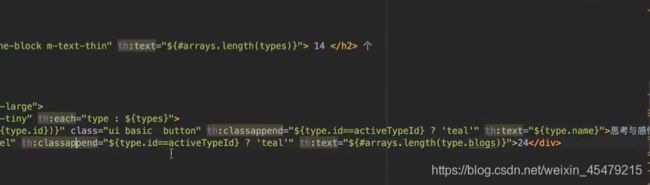
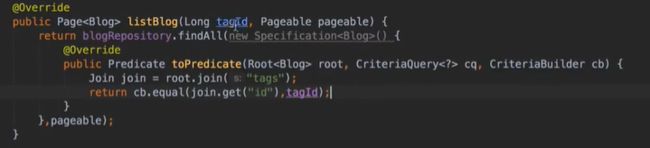
#博客按标签展示

#归档页

![]()
![]()

#关于我
#footer完善


