WEBMAGIC——JAVA爬虫也很牛哦
目录
webmagic的那些事儿
webmagic的环境准备
webmagic的四大组件的介绍
定制PageProcessor
定制Pipeline
数据库配置
Pipeline的编写
设置代理
定制Downloader
看完这篇博文需要30分钟,耐心哦,手把手超详细的java爬虫教学呢!手打一个多小时!
我的 github 的地址:https://github.com/cxkjntm/Recommend_News
webmagic的那些事儿
webmagic是一款java网络爬虫,目前开发到0.7.3版,作者已经放弃他了,但是不妨碍他是一款很不错的爬虫框架。懒得学python爬虫,又稍微熟悉Java的朋友可以直接上手,原因是他有中文文档,不需要你费劲的去翻译。
WEBMAGIC点我去往官网哦
webmagic的环境准备
前期的准备很简单的,下载一个webmagic-core包,然后以maven工程形式导入到IDEA,然后就可以着手开发了。

然后你就不需要再动什么配置了,作者这个已经很完善了。
webmagic的四大组件的介绍
以下是作者对四大组件的介绍。
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,
PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
定制PageProcessor
PageProcessor是用来解析页面的,但是每个人的需求,每个站点也不一样,故而我这里只演示爬取环球网新闻的AJAXPageProcessor
package us.codecraft.webmagic.processor.example;
import com.sun.xml.internal.fastinfoset.util.StringArray;
import org.apache.commons.collections.CollectionUtils;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Request;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.MysqlPipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.JsonPathSelector;
import us.codecraft.webmagic.sql.NewsInfo;
import java.sql.SQLException;
import java.util.List;
/**
* @author lxy
* since 2020-1-29
*/
public class AjaxPageProcessor implements PageProcessor {
private Site site = Site.me().setDomain("www.huanqiu.com").setSleepTime(3000);
private static final String LIST_URL = "https://www.huanqiu.com/article/.*";
private static final String Help_URL = "https://[a-z]+.huanqiu.com/api/list";
public final int count = 0;
@Override
public void process(Page page) {
NewsInfo newsInfo = new NewsInfo();
if (page.getUrl().regex(LIST_URL).match()) {
System.out.println("进入目标页");
newsInfo.setContent(page.getHtml().xpath("//section[@data-type='rtext']/tidyText()").toString());
newsInfo.setTitle(page.getHtml().xpath("//div[@class='t-container-title']/allText()").toString());
newsInfo.setAuthor(page.getHtml().xpath("//span[@class='source']/span/allText()").toString());
page.putField("msg", newsInfo);
} else {
if(page.getUrl().regex(Help_URL).match()) {
System.out.println("进入列表页");
List aids = new JsonPathSelector("$.list[*].aid").selectList(page.getRawText());
for(String a:aids){
String NEXTURL = "https://www.huanqiu.com/article/";
NEXTURL += a;
System.out.println(NEXTURL);
page.addTargetRequest(NEXTURL);
}
}
else {
List nodes = new JsonPathSelector("$.children[*].children[*].node").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(nodes)) {
List URL = new JsonPathSelector("$.children[*].url").selectList(page.getRawText());
//截取请求前部
String NEXTURL = "list?node=";
//添加节点
for (String n : nodes) {
NEXTURL = NEXTURL + "%22" + n +"%22,";
}
//去除最后一个逗号
NEXTURL = NEXTURL.substring(0, NEXTURL.length()-1);
//添加数据库限制值
for(int i = 0 ; i < 100 ; i += 20) {
String nexturl = NEXTURL;
nexturl += "&offset=" + i + "&limit=" + (i + 20);
System.out.println("page for "+i+" to "+ (i+20));
page.addTargetRequest(nexturl);
}
NEXTURL=null;
}
}
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) throws SQLException {
MysqlPipeline mysqlPipeline = new MysqlPipeline();
Request request = new Request();
//真实请求地址
StringArray urls = new StringArray();
urls.add("//world.huanqiu.com");
urls.add("//china.huanqiu.com");
urls.add("//mil.huanqiu.com");
urls.add("//taiwan.huanqiu.com");
urls.add("//opinion.huanqiu.com");
urls.add("//finance.huanqiu.com");
urls.add("//tech.huanqiu.com");
urls.add("//auto.huanqiu.com");
urls.add("//art.huanqiu.com");
urls.add("//go.huanqiu.com");
urls.add("//health.huanqiu.com");
urls.add("//sports.huanqiu.com");
urls.add("//quality.huanqiu.com");
urls.add("//bigdata.huanqiu.com");
urls.add("//look.huanqiu.com");
urls.add("//chamber.huanqiu.com");
urls.add("//biz.huanqiu.com");
for(int i = 0 ; i < 17 ;i ++) {
request.setUrl("https:"+urls.get(i)+"/api/channel_pc");
request.setMethod("get");
//System.out.println("now crawer for page "+i);
Spider.create(new AjaxPageProcessor()).addRequest(request).addPipeline(mysqlPipeline).thread(20).run();
}
}
} 对代码解释一下。
AJAXPageProcessor通过继承PageProcessor类,通过实现
public void process(Page page)方法和public Site getSite()
完成页面解析。由于我所爬取的环球网使用前端渲染界面,所以这就用到了对AJAX请求的分析。下面对站点的请求进行分析。
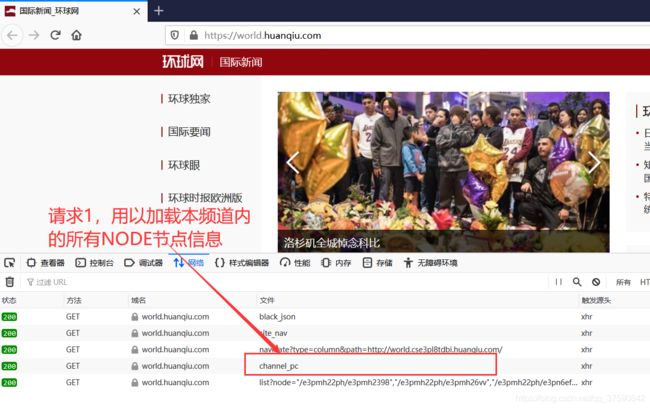
点击channel_pc查看请求方法
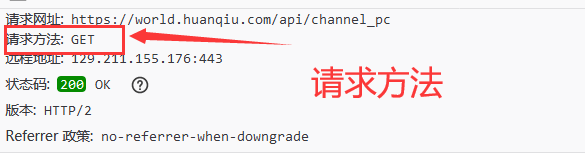
发现请求方法为get,对请求2的分析可以得知,之后的请求是用来加载新闻列表的,也就是说我们通过这些请求的json数组分析可以得到所有的新闻地址。

双击查看channel_pc请求的json数组

之后的请求连接

你会发现原来加载新闻列表是通过https://xxxx.huanqiu.com/api/list?node=再加上channel_pc json数组中所有children的node属性完成的。哇塞!下面我们就可以通过直接请求https://xxxx.huanqiu.com/api/lis?node=[所有node属性] 得到所有的新闻列表。
那么现在我们得到了新闻列表,即helpurl,并没有进入目标页,即targeturl。
request.setUrl("https:"+urls.get(i)+"/api/channel_pc");
request.setMethod("get");上面两行代码便是设置请求url和请求方法。
Spider.create(new AjaxPageProcessor())
.addRequest(request)
.addPipeline(mysqlPipeline)
.thread(20)
.run();Spider融合四大组件,通过addRequest()添加请求,addPipeline()添加持久化方式,thread()设置线程数,run方法启动
public void process(Page page)这个函数就是设置如何解析页面。
下面这两行为设置helpurl和targeturl,这样设置是为了使用正则过滤请求网址,实现分流,达到对不同网址进行不同操作。
private static final String LIST_URL = "https://www.huanqiu.com/article/.*";
private static final String Help_URL = "https://[a-z]+.huanqiu.com/api/list";下面是分流方法
if (page.getUrl().regex(LIST_URL).match()) {
System.out.println("进入目标页");
newsInfo.setContent(page.getHtml().xpath("//section[@data-type='rtext']/tidyText()").toString());
newsInfo.setTitle(page.getHtml().xpath("//div[@class='t-container-title']/allText()").toString());
newsInfo.setAuthor(page.getHtml().xpath("//span[@class='source']/span/allText()").toString());
page.putField("msg", newsInfo);
} else {
if(page.getUrl().regex(Help_URL).match()) {
System.out.println("进入列表页");
List aids = new JsonPathSelector("$.list[*].aid").selectList(page.getRawText());
for(String a:aids){
String NEXTURL = "https://www.huanqiu.com/article/";
NEXTURL += a;
System.out.println(NEXTURL);
page.addTargetRequest(NEXTURL);
}
}
else {
List nodes = new JsonPathSelector("$.children[*].children[*].node").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(nodes)) {
List URL = new JsonPathSelector("$.children[*].url").selectList(page.getRawText());
//截取请求前部
String NEXTURL = "list?node=";
//添加节点
for (String n : nodes) {
NEXTURL = NEXTURL + "%22" + n +"%22,";
}
//去除最后一个逗号
NEXTURL = NEXTURL.substring(0, NEXTURL.length()-1);
//添加数据库限制值
for(int i = 0 ; i < 100 ; i += 20) {
String nexturl = NEXTURL;
nexturl += "&offset=" + i + "&limit=" + (i + 20);
System.out.println("page for "+i+" to "+ (i+20));
page.addTargetRequest(nexturl);
}
NEXTURL=null;
}
}
} 使用XpathSelector完成页面元素选取,更多信息可以看一下作者对Selector的介绍。页面选取也是多样化的,css选取也是可以的,我本人偏爱xpath

选取后的结果使用page.putField(key,value)放入结果集,可以在Pipeline中使用resultItem.get(key)方法获取,更多介绍将会在Pipeline中介绍。
而剩余两路则是对频道首页请求和新闻列表请求的处理,就是使用JsonPathSelector完成对json数组中值的获取,然后拼接url放入队列中等待处理。
![]()
上图结果为下载频道首页
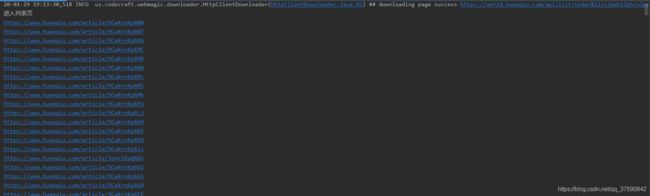
而这张图表示解析新闻列表页,获取新闻目标页。https://www.huanqiu.com/article/.* 为新闻内容所在网址。
至此,PageProcessor定制解说完毕。
定制Pipeline
Pipeline是为了完成爬取结果持久化的。由于每个人的数据库不一样,所需要的信息也不一样,所以作者没有提供现成的数据库持久化方案,所以,定制自己的数据库持久化方案就得提上日程。
数据库配置
在项目的pom.xml中添加mysql依赖
mysql
mysql-connector-java
5.1.38
这样我们就可以直接在Maven工程中使用mysql了。
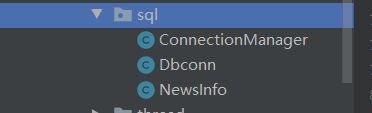
这个是我们要编写的java类。
ConnectionManager是数据库连接池的配置文件。
package us.codecraft.webmagic.sql;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Date;
import java.util.Stack;
public class ConnectionManager {
int minConn = 2; // 连接池最少连接数
int maxConn = 22;// 连接池最多连接数
String user = "root"; // 连接数据库使用的用户名
String password = "123456"; // 连接数据库使用的用户名密码
String url = "jdbc:mysql://localhost:3306/Recommend_News?useUnicode=true&characterEncoding=utf8&useSSL=false";// 所连接的数据库的URL(连接字符串)
String logFile = "D:\\spider\\dbpool.log";// 日志文件路径
PrintWriter loger = null; // 记录日志Log的对象
int connAmount = 0; // 当前现有的连接的个数
Stack connStack = new Stack(); // 使用Stack保存数据库连接, 也可以使用数组, Vector等保存
/**
* 构造函数 功能: 1.初始化 2.打开Log文件 3.注册驱动程序 4.根据最小连接数生成连接
*/
private ConnectionManager() {
try {
loger = new PrintWriter(new FileWriter(logFile, true), true);
} catch (IOException ioe) {
loger = new PrintWriter(System.err);
}
// 注册驱动程序
try {
Class.forName("com.mysql.jdbc.Driver");
log("成功注册驱动程序");
} catch (Exception e) {
log("无法注册驱动程序");
}
// 根据最少连接数生成连接
for (int i = 0; i < minConn; i++) {
Connection con = newConnection();
if (con != null)
connStack.push(con);
}
}
// 将文本信息msg写入日志文件
private void log(String msg) {
loger.println(new Date() + ":" + msg);
}
private static ConnectionManager instance; // 数据库连接池ConnManager的实例
public static synchronized ConnectionManager getInstance() {
// 返回唯一实例。如果是第一次调用此方法,则创建该实例
if (instance == null) {
instance = new ConnectionManager();
}
return instance;
}
// 创建新的连接
private Connection newConnection() {
Connection con = null;
try {
con = DriverManager.getConnection(url, user, password);
connAmount++;
log("连接池创建一个新的连接");
} catch (SQLException e) {
log("无法创建下列url的连接: " + url);
return null;
}
return con;
}
public synchronized Connection getConnection() {
/**
* 从连接池获得一个可用连接.如没有空闲的连接且当前连接数小于最大连接数限制, 则创建新连接
*/
Connection con = null;
log("从连接池申请一个连接");
log("现在可用的连接总数为: " + connStack.size());
if (!connStack.empty()) {
con = (Connection) connStack.pop();
} else if (connAmount < maxConn) {
con = newConnection();
} else {
try {
log("等待连接");
wait(100000);// 等待其他进程释放连接,单位是毫秒
return getConnection();
} catch (InterruptedException ie) {
}
}
return con;
}
public synchronized void freeConnection(Connection con) {
// 将不再使用的连接返回给连接池
connStack.push(con);
notifyAll();// 唤醒在此对象监视器上等待的所有线程
log("归还一个连接到连接池");
}
} Dbconn是为了实例化连接。
package us.codecraft.webmagic.sql;
import java.sql.*;
public class Dbconn {
public static Statement ReturnStatement() throws SQLException {
ConnectionManager pool = ConnectionManager.getInstance();
Connection connection = pool.getConnection();
Statement statement = connection.createStatement();
return statement;
}
}
NewsInfo是对应于数据表的列名和方法。
package us.codecraft.webmagic.sql;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.List;
import java.util.Vector;
public class NewsInfo {
private long ID;
private String title;
private String author;
private String content;
private String category;
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
public long getID() {
return ID;
}
public void setID(long ID) {
this.ID = ID;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public void print(){
System.out.println("---------------------------print newinfo start--------------------------------");
System.out.println("author: "+ this.getAuthor()+"\ntitle: "+this.getTitle()+"\ncontents: "+this.getContent());
System.out.println("---------------------------print newinfo over --------------------------------");
}
public boolean save(Statement statement) throws SQLException {
String sql = "INSERT ignore INTO news(AUTHOR,TITLE,CONTENT) VALUES('"+this.getAuthor()+"','"+this.getTitle()+"','"+this.getContent()+"')";
int flag = statement.executeUpdate(sql);
if(flag<0) return false;
return true;
}
}
数据库新闻表的脚本文件
/*
Navicat Premium Data Transfer
Source Server : Recommend_News
Source Server Type : MySQL
Source Server Version : 100119
Source Host : localhost:3306
Source Schema : recommend_news
Target Server Type : MySQL
Target Server Version : 100119
File Encoding : 65001
Date: 29/01/2020 19:28:00
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for news
-- ----------------------------
DROP TABLE IF EXISTS `news`;
CREATE TABLE `news` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`AUTHOR` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '新闻来源',
`TITLE` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '新闻标题',
`CONTENT` longtext CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '新闻正文',
`CATEGORY` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '类别',
PRIMARY KEY (`ID`, `TITLE`) USING BTREE,
UNIQUE INDEX `title_index`(`TITLE`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 26172 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
SET FOREIGN_KEY_CHECKS = 1;
至此,数据库的配置结束。
Pipeline的编写
作者提供了一个很好的环境,只要我们重写Pipline的process方法就可以完成持久化。
public class MysqlPipeline implements Pipeline {
//获得Statement对象
Statement statement= Dbconn.ReturnStatement();
public MysqlPipeline() throws SQLException {
}
@Override
public void process(ResultItems resultItems, Task task) throws SQLException {
//获取来自PageProcessor的processor中putField(key,value)中的值
NewsInfo newsInfo = resultItems.get("msg");
//如果爬取的新闻内容不为空就向数据库写入一条记录
if(newsInfo.getContent() != null){
System.out.println("save sucessfully");
newsInfo.save(statement);
}
}
}
怎么样,定制Pipeline还是很方便的吧。
设置代理
是不是疑问为什么要设置代理?其实很简单,很多大企业的网站都会设置限制,如果爬虫一直爬取网页信息就会占用他的带宽,其他人有可能就不能登上他的网站浏览信息。甚至会出现拒绝服务的现象,也就是dos攻击了,为了防止这种状况的出现,通过封禁ip的方式使得爬虫不得对该网站进行爬取了,这就对我们的信息采集又很大影响了。于是我们为了防止被封禁ip,就得设置代理了。
定制Downloader
webmagic设置代理的方法是通过HttpClientDownloader.setProxyProvider(SimpleProxyProvider.from(new Proxy(ip,port)))完成的
首先实例化一个对象,然后调用上面的方法,最后在Spider.create()方法后追加.Downloder()方法即可,方法同MysqlPipeline。环球网比较大气好像没有设置封禁,于是,我没有用上这个代理。其他网站建议使用代理哦。
推荐代理服务器网址:米扑代理
至此,我们的爬虫就全部搞定了,运行一下就可以在数据库中找到新闻啦。庆祝!