【daisy-framework】消息中间件
前言
Github:https://github.com/yihonglei/daisy-framework
Github:https://github.com/yihonglei/message-middle
一 为什么要使用消息队列?
三个核心场景:解耦、异步、削峰。
1、解耦
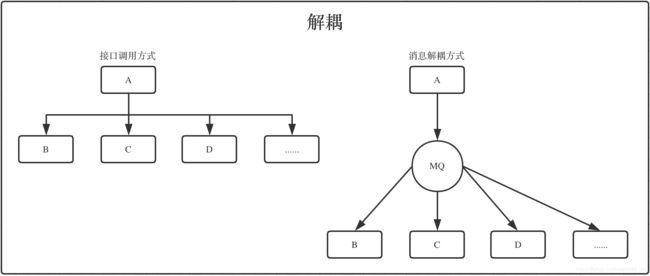
接口调用方式
假如有A、B、C、D四个系统,A系统有重要数据,通过接口调用下游B、C、D系统分别给他们不同的数据,
A系统负责人用烦躁的心情调了他们的接口,假如这个时候有其它系统也告诉他,哥们,我们也要数据,
我们提供了写入的接口,辛苦你调下,谁都让他调,A系统的负责人会哭的,他还要处理每个调用的超时等异常情况,
兄弟,你保重身体!
消息解耦方式
A系统只需要把相应数据发个MQ,B、C、D系统订阅消息,消费做业务处理就行,如果再有人要让A系统负责人调下接口,
可以喝着咖啡,用愉悦的心情告诉他,订阅XXXTopic,自己消费就行。
2、异步

接口调用方式
假如有A、B、C、D系统,用户触发调A系统,A系统调B、C、D系统,用户需要等60ms+30ms+500ms+200ms=790ms的时间,
快1s之后才能看到结果,可能A系统处理的数据是用户想看的,B、C、D系统的处理的数据可能是我们系统内部的一些记录
数据之类的,或者用户不需要实时看到的数据,这些数据可以异步处理,用户的耐心是有限的,别让用户等太久,得到用户
的心太难,但是失去确很容易。
消息异步方式
A系统处理完核心的数据,马上就返回给用户结果,然后发送相应消息,B、C、D系统进行消费处理,将同步处理的业务化为
异步处理,目的是提高响应速度。
3、削峰
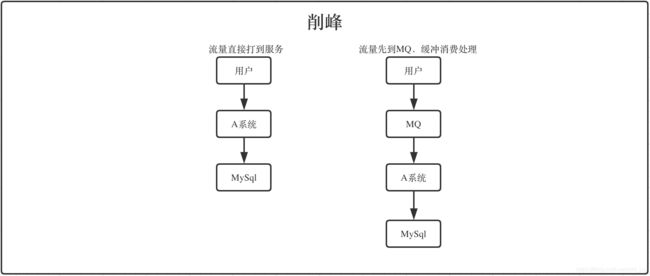
流量直接打到服务
如果平时A系统流量比较小,但是高峰期或者做活动的时候,流量非常大,这个时候数据库承受不了这么大的压力。
一般可以用缓存或者MQ方式解决。
流量先到MQ,A系统消费处理
流量都先打到MQ,由MQ缓冲,A系统负责从MQ根据自己数据库情况分批消费处理。
二 消息队列优缺点?
每种技术各有利弊,有优点,就必然有缺点,如果有哪种技术是集完美于一生,市面上就不会有缤纷多彩的技术出现。
1、优点
优点就是上面说的解耦、异步、削峰。
2、缺点
数据一致性问题
分布式系统里面数据一致性问题一直就是个大问题,使用消息队列数据不一致只是其中之一。为什么会出现数据不一致呢?
A系统处理完,发了个MQ,BC可能消费成功并存入数据了,D可能消费失败,或者存入数据库失败了,这个时候D的数据
就不一致了,因为理论上A的某个状态数据,会对应BCD相应的数据,但是D失败了,这个时候怎么办?
常规处理办法:
1)根据消息队列特性,尝试重复消费 ;
2)如果是消费端拿到消息了,但是只是一直入不了库,消费端可以存储消息某些关键数据,通过定时任务做补偿,
保证最终一致性;
系统复杂度增高
直接调接口方式很爽吧,就是调,哈哈!但是现在加个MQ了,事情也多了些,处理的问题也多了些!
MQ代码要处理吧,重复消费要考虑吧,消息不丢要考虑吧,有顺序消费要求的也要考虑吧等,
这些都会增加复杂度,搞不好都让你头大,搞好了才能喝咖啡;
系统可用性降低
MQ的高可用必须保证吧,挂掉了就不好玩了,如果用的XX云服务,还得花点钱;
三 如何保证消息消费幂等性?
在正常情况下,使用MQ就是生产消息,消费消息,然后给MQ确认,不同的消息队列发送的确认信息形式不同,
例如RabbitMQ是发送一个ACK确认消息,RocketMQ是返回一个CONSUME_SUCCESS成功标志,kafka实际上有个offset的概念。
看上去很完美,但是,很多情况下可能存在重复消费,比如,就是因为网络原因闪断,ACK返回失败等等故障,
确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将该消息分发给其他的消费者。
(因为消息重试等机制的原因,如果一个consumer断了,rocketmq有consumer集群,会将该消息重新发给其他consumer)。
针对重复消费一般在消费端处理,使用MQ如果消费端幂等性没做好,会产生很多脏数据,业务都可能错乱了。
常规处理消费幂等性方法:
1、消费端执行业务前,通过幂等id查询业务是否处理过,处理过,则不需要进行处理;
2、数据库层面建立唯一索引,保证不出现重复的数据;
3、消息记录表,这个表记录消费国的消息,一旦查询到消费过,则不进行消费;
4、数据库乐观锁,根据消费数据,通过数据库乐观锁尝试更新,获取锁成功,则消费,否则不消费;
5、Redis的setnx,分布式锁形式,天然支持幂等性;
6、Redis里面建立唯一id,记录每次的消费,如果已经存在,则不再消费;
实际要根据业务情况处理幂等性,有必要的情况还需要做适当的补偿机制,要保证消息在出现任何异常情况,
数据都能达到最终一致性。
四 如何保证消息不丢失?
使用MQ有些非核心场景,可以允许丢失,但是有些数据非常重要,如果用MQ处理,就需要保证你的消息不能丢。
消息丢失可能在生产端,压根可能没发出来,也有可能发到MQ了,丢失在MQ里面,还有可能在消费端没拉到消息。
如果用的RocketMQ,他帮我们提供了消息不丢的一些处理。
RocketMQ消息大致流程过程:
producer(生产者生产消息) --》broker(存储消息) --》cunmser(消费消息)
producer如何保证消息不丢失:
1、默认情况下,可以通过同步的方式阻塞式的发送,check SendStatus,状态是OK,表示消息一定成功的投递到了Broker,
状态超时或者失败,则会触发默认的2次重试。此方法的发送结果,可能Broker存储成功了,也可能没成功。
2、采取事务消息的投递方式,并不能保证消息100%投递成功到了Broker,但是如果消息发送Ack失败的话,
此消息会存储在CommitLog当中,但是对ConsumerQueue是不可见的。可以在日志中查看到这条异常的消息,
严格意义上来讲,也并没有完全丢失。
3、RocketMQ支持日志的索引,如果一条消息发送之后超时,也可以通过查询日志的API,来check是否在Broker存储成功。
broker如何保证消息不丢失:
1、消息支持持久化到Commitlog里面,即使宕机后重启,未消费的消息也是可以加载出来的。
2、Broker自身支持同步刷盘、异步刷盘的策略,可以保证接收到的消息一定存储在本地的内存中。
3、Broker集群支持1主N从的策略,支持同步复制和异步复制的方式,同步复制可以保证即使Master磁盘崩溃,
消息仍然不会丢失。
cunmser如何保证消息不丢失:
1、Consumer自身维护一个持久化的offset(对应MessageQueue里面的min offset),标记已经成功消费或者已经成功
发回到broker的消息下标。
2、如果Consumer消费失败,那么它会把这个消息发回给Broker,发回成功后,再更新自己的offset。
3、如果Consumer消费失败,发回给broker时,broker挂掉了,那么Consumer会定时重试这个操作。
4、如果Consumer和broker一起挂了,消息也不会丢失,因为consumer里面的offset是定时持久化的,重启之后,
继续拉取offset之前的消息到本地。
五 如何保证消息顺消费?
有时候我们发出的消息是按顺序发的,消费的时候也需要顺序消费,如果错乱了,会导致数据异常。
每种MQ通用处理办法,就是建多个queue,发送的时候保证需要顺序消费的消息都顺序的发送到同一个queue,
消费端需要按照队列的FIFO顺序消费,如果采用多线程消费,交给多个worker处理,就需要注意了,
多线程消费你保证不了每个线程处理的先后顺序,需要特别小心。
六 如何处理消息积压、延迟、过期、爆满问题?
1、消息大量积压
消息大量积压,一般情况不会出现,但是一旦出现,就是个大问题。
消息大量积压最普通的原因一般是你的消费端挂了,或者消费端入库异常,或者程序异常,
一直不能给MQ反馈消费过了,消息一直在MQ里面,而生产端却一直不断生产消息。
这个时候最常见的处理办法就是修复消费端,上线继续消费,如果积压比较小,可能很快就消费完了,影响不大,
但是要是积压量比较大,消费处理好几个小时,这个时候依赖MQ的数据都不一致,没法玩了,等不起这个时间,
处理办法就是写一个零时程序,将消息均摊给不同消息队列,分开队列消费,等差不多在切回正常消费程序,
正常消费可能会有重复消息,消费端幂等性要做好。
2、消息队列延时和过期失效
RabbitMQ可以设置消息过期时间,多长时间不消费,消息自动清除,积压太久,消息就从队列丢了,
这个需要根据MQ持久化日志,把丢的消息补回来,批量重新导入到MQ队列。
3、消息队列爆满
消息队列爆满不容易遇到,之前用过RabbitMQ,现在公司自己搭的RocketMQ,
RocketMQ支持10亿消息积压,当消息积压超过一定量后,我们做了监控报警,你的系统消息积压到爆满了,
你还神不知鬼不觉,系统监控做的就不够全面了啊,谁要负责这个东西,估计可以去找下家了。
从网上搜了下,处理消息爆满这个场景的话题比较少,如果真出现了,处理中心思想就是写入一个消息,
丢掉一个消息,等量下来后,半夜喝咖啡去补消息。
七 如何对消息中间件进行技术选型?
RocketMQ、RabbitMQ、ActiveMQ、Kafka 对比?
| 特性 | 可用性 | 消息可靠性 | 时效性 | 单机吞吐量 | 功能支持 | 应用领域 |
| RocketMQ | 分布式架构实现,基于Netty通信实现,非常高 | 经过参数优化配置,可以做到 0 丢失 | ms 级 | 10 万级,支撑高吞吐 | MQ 功能较为完善,还是分布式的,扩展性好 | 业务用得多 |
| RabbitMQ | 基于主从架构实现高可用,比较高 | 基本不丢,可以开启消息持久化功能 | 微秒级,这是 RabbitMQ 的一大特点,延迟最低 | 万级,比 RocketMQ、Kafka 低一个数量级 | 基于 erlang 开发,并发能力很强,性能极好,延时很低 | 业务用得多 |
| ActiveMQ | 同RabbitMQ | 有较低的概率丢失数据 | ms 级 | 同RabbitMQ | MQ 领域的功能极其完备 | 业务用得多 |
| Kafka | 分布式,一个数据多个副本,非常高 | 同RocketMQ | 延迟在 ms 级以内 | 10 万级,高吞吐 | 功能较为简单,主要支持简单的 MQ 功能 | 在大数据领域的实时计算以及日志采集被大规模使用 |