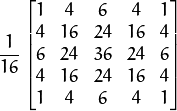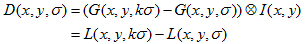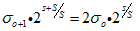我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性。也就是说使用卷积就是为了提取显著特征,减少特征维数,减少计算量。
在对图像进行卷积操作后的只管现象:图像变得模糊了,可是我们依然能够分辨出是什么!所以卷积就是提取显著特征!
1尺度空间理论
每个物体,我们总可以用一些词语或部件来描述它,比如人脸的特征:两个眼睛、一个鼻子和一个嘴巴。对于图像而言,我们需要计算机去理解图像,描述图像就需要计算机去取得图像的特征,对图像比较全面的描述即一个二维矩阵,矩阵内的每个值代表图像的亮度。有时候我们需要让计算机更简化的来描述一个图像,抓住一些显著特征,这些特征要具有一些良好的性质,比如局部不变性。局部不变性一般包括两个方面:尺度不变性与旋转不变性。
-
尺度不变性
:人类在识别一个物体时,不管这个物体或远或近,都能对它进行正确的辨认,这就是所谓的尺度不变性。尺度空间理论经常与生物视觉关联, 有人也称图像局部不变性特征为基于生物视觉的不变性方法。
旋转不变性:
当这个物体发生旋转时,我们照样可以正确地辨认它,这就是所谓的旋转不变性。
全局特征:从整个图像中抽取的特征。较多的运用在图像检索领域,如图像颜色直方图。
局部特征:从图像的局部区域中抽取的特征(这个局部区域往往是图像中的一个像素及它周围的邻域)。
一种好的局部特征应该具有下面的特性:
- 可重复性:同一个物体在不同时间,不同角度拍到图像中,检测到的特征对应的越多越好。
- 独特性:特征在该物体上表现为独特性,能与场景下其他物体区分。
- 局部性:特征往往是物体某个局部的特点,这样才可以避免遮挡时不能匹配的问题。
- 数量性:检测到的特征数目一定要多,密集度最好能在一定程度上反映图像的内容。
- 准确性:得到的特征应该能被精确定位,能够精确到像素。
- 高效性:特征检测算法运算要快。
- 2 具体实施过程
当用一个机器视觉系统分析未知场景时,计算机没有办法预先知识图像中物体尺度,因此,我们需要同时考虑图像在多尺度下的描述,获知感兴趣物体的最佳尺度。
所以在很多时候,我们会在将图像构建为一系列不同尺度的图像集,在不同的尺度中去检测我们感兴趣的特征。比如:在Harr特征检测人脸的时候,因为我们并不知道图像中人脸的尺寸,所以需要生成一个不同大小的图像组成的金字塔,扫描其中每一幅图像来寻找可能的人脸。
图像金字塔化的一般步骤:首先,图像经过一个低通滤波器进行平滑(这个步骤会使图像变模糊,好像模仿人的视觉中远处的物体没有近处的清晰的原理),然后,对这个平滑后的图像进行抽样(一般抽样比例在水平和竖直方向上都为1/2),从而得到一系列的缩小的图像。

假设高斯金字塔的第 $l$ 层图像为$G_l$,则有:
$$G_l(i,j)=\sum^{2}_{m=-2}\sum_{n=-2}^2\omega(m,n)G_{l-1}(2i+m,2j+n)$$
$$(1\le l \le N,0 \le i \le R_l,0 \le j \le C_l)$$
式中,$N$为高斯金字塔顶层 拨动号;$R_l$和$G_l$分别为高斯金字塔第$l$层的行数和列数;$\omega(m,n)$是一个二维可分离的$5 \times 5$窗口函数,表达式为:
$$\omega=\frac{1}{256} \begin{bmatrix} 1 & 4 & 6 & 4 & 1\\ 4 & 16 & 24 & 16 & 4\\ 6 & 24 &36 & 24 & 6\\ 4 & 16 & 24 & 16 & 4\\ 1 & 4 & 6 & 4 & 1 \\ \end{bmatrix} =\frac{1}{16}\begin{bmatrix} 1 & 4 & 6 & 4 &1 \end{bmatrix}\times\frac{1}{16}\begin{bmatrix} 1 \\ 4 \\ 6 \\ 4 \\1 \end{bmatrix} $$
写成上面的形式是为了说明,二维窗口的卷积算子,可以写成两个方向上的1维卷积核(二项核)的乘积。上面卷积形式的公式实际上完成了2个步骤:1)高斯模糊;2)降维。
按上述步骤生成的$G_0,G_1,\dots ,G_N$就构成了图像的高斯金字塔,其中$G_0$为金字塔的底层(与原图像相同),$G_N$为金字塔的顶层。可
见高斯金字塔的当前层图像是对其前一层图像先进行高斯低通滤波,然后做隔行和隔列的降采样(去除偶数行与偶数列)而生成的。当前层图像的大小依次为前一层图像大小的1/4。
下面是用OpenCV中的图像金字塔相关函数写的一个生成图像金字塔的示例程序。程序中,不但生成了图像金字塔,而且生成了图像的拉普拉斯金字塔(接下来的内容)。
enum
pyrType { PYR_GUASS, PYR_LAPLACE };
void genPyr(const Mat& imgSrc, vector& outPutArray, int TYPE, int level)
{
outPutArray.assign(level + 1, Mat());
outPutArray[0] = imgSrc.clone(); // the 0 level is the image.
for (int i = 0; i != level; i++)
{
pyrDown(outPutArray[i], outPutArray[i + 1]);
}
if (PYR_GUASS == TYPE)
{
return;
}
for (int i = 0; i != level; i++)
{
Mat UpSampleImg;
pyrUp(outPutArray[i + 1], UpSampleImg, outPutArray[i].size());
outPutArray[i] -= UpSampleImg;
}
}
将$G_l$进行内插(这里内插用的不是双线性而是用的与降维时相同的滤波核)得到放大图像$G_l^{\ast}$,使$G_l^{\ast}$的尺寸与$G_{l-1}$的尺寸相同,表示为:
$$ G_l^{\ast}(i,j)=4\sum_{m=-2}^2\sum_{n=-2}^2\omega(m,n)G_l(\frac{i+m}{2},\frac{j+n}{2}) \\ (0 \le l \le N,0 \le i \le R_l,0 \le j \le G_l) $$
上面的系数4,是因为每次能参与加权的项,的权值和为4/256,这个与我们用的$\omega$的值有关。
式中,
$$ G_l(\frac{i+m}{2},\frac{j+n}{2})=\begin{cases} G_l(\frac{i+m}{2},\frac{j+n}{2}), & 当\frac{i+m}{2},\frac{j+n}{2}为整数时 \\ 0, & 其他 \end{cases} $$
$$ \begin{cases} LP_l=G_l-G_{l+1}^{\ast}, & 当0 \le l \le N时 \\ LP_N=G_N, & 当l=N时 \end{cases} $$
式中,$N$为拉普拉斯金字塔顶层号,$LP_l$是拉普拉斯金字塔分解的第$l$层图像。
由$LP_0,LP_1, \dots,LP_l,\dots,LP_N$构成的金字塔即为拉普拉斯金字塔。
它的每一层图像是高斯金字塔本层图像与其高一级的图像经内插放大后图像的差,此过程相当于带通滤波,因此拉普拉斯金字塔又称为带通金字塔分解。
下图为小猫图像的拉普拉斯金字塔图像:

图像的金字塔化能高效地(计算效率也较高)对图像进行多尺度的表达
,但它缺乏坚实的理论基础,不能分析图像中物体的各种尺度(虽然我们有小猫的金字塔图像,我们还是不知道原图像内小猫的大小)。
尺度空间理论本质
以及其理论支撑:信号的尺度空间刚提出是就是通过一系列单参数、宽度递增的高斯滤波器将原始信号滤波得到到组低频信号。那么一个很明显的疑问是:除了高斯滤波之外,其他带有参数t的低通滤波器是否也可以用来生成一个尺度空间。
后来Koenerink、Lindeberg[Scale-space theory in computer vision]、Florack等人用精确的数学形式通过不同的途径都证明了高斯核是实现尺度变换的唯一变换核。
虽然很多研究者从可分性、旋转不变性、因果性等特性推出高斯滤波器是建立线性尺度空间的最优滤波器。然后在数字图像处理中,需要对核函数进行采样,离散的高斯函数并不满足连续高斯函数的的一些优良的性质。所以后来出现了一些非线性的滤波器组来建立尺度空间,如B样条核函数。
使用高斯滤波器对图像进行尺度空间金塔塔图的构建,让这个尺度空间具有下面的性质:
信号在尺度t上的表达可以看成是原信号在空间上的一系列加权平均,权重就是具有不同尺度参数的高斯核。
信号在尺度t上的表达也对应于用一个无方向性的孔径函数(特征长度为$\sigma=\sqrt{t}$)来观测信号的结果。这时候信号中特征长度小于$\sigma$的精细结构会被抑制[理解为一维信号上小于$\sigma$的波动会被平滑掉。
也叫高斯核族的半群(Semi-Group)性质:两个高斯核的卷积等同于另外一个不同核参数的高斯核卷积。
$$g(\mu,\sigma_1)\ast g(\mu,\sigma_2)=g(\mu,\sqrt{\sigma_1^2+\sigma_2^2})$$
这个性质的意思就是说不同的高斯核对图像的平滑是连续的。
这个特征可以从人眼的视觉原理去理解,人在看一件
物体时,离得越远,物体的细节看到的越少,细节特征是在减少的。
高斯核对图像进行滤波具有压制局部细节的性质。
这里只是一个公式推导的问题,对原来的信号加一个变换函数,对变换后的信号再进行高斯核的尺度空间生成,新的信号的极值点等特征是不变的。
Young对经生理学的研究中发现,哺乳动物的视网膜和视觉皮层的感受区域可以很好地用4阶以内的高斯微分来建模。
一般我们采集到的图像中,我们并不知道我们感兴趣的目标在图像中的尺度,在这样的情况下,我们对图像进行分析时就无法选择合适的参数,比如边缘检测,可能由于参数不当,而造成过多的局部细节。
3 为什么用高斯核
图像的金字塔化能高效地(计算效率也较高)对图像进行多尺度的表达,但它缺乏坚实的理论基础,不能分析图像中物体的各种尺度(虽然我们有小猫的金字塔图像,我们还是不知道原图像内小猫的大小)。
信号的尺度空间刚提出是就是通过一系列单参数、宽度递增的高斯滤波器将原始信号滤波得到到组低频信号。那么一个很明显的疑问是:除了高斯滤波之外,其他带有参数t的低通滤波器是否也可以用来生成一个尺度空间。
后来Koenerink、Lindeberg[Scale-space theory in computer vision]、Florack等人用精确的数学形式通过不同的途径都证明了高斯核是实现尺度变换的唯一变换核。
虽然很多研究者从可分性、旋转不变性、因果性等特性推出高斯滤波器是建立线性尺度空间的最优滤波器。然后在数字图像处理中,需要对核函数进行采样,离散的高斯函数并不满足连续高斯函数的的一些优良的性质。所以后来出现了一些非线性的滤波器组来建立尺度空间,如B样条核函数。
使用高斯滤波器对图像进行尺度空间金塔塔图的构建,让这个尺度空间具有下面的性质:
1)加权平均和有限孔径效应
信号在尺度t上的表达可以看成是原信号在空间上的一系列加权平均,权重就是具有不同尺度参数的高斯核。
信号在尺度t上的表达也对应于用一个无方向性的孔径函数(特征长度为σ=t√)来观测信号的结果。这时候信号中特征长度小于σ的精细结构会被抑制[理解为一维信号上小于σ的波动会被平滑掉。]。
2)层叠平滑
也叫高斯核族的半群(Semi-Group)性质:两个高斯核的卷积等同于另外一个不同核参数的高斯核卷积。
g(μ,σ1)?g(μ,σ2)=g(μ,σ21+σ22???????√)
这个性质的意思就是说不同的高斯核对图像的平滑是连续的。
3)局部极值递性
这个特征可以从人眼的视觉原理去理解,人在看一件物体时,离得越远,物体的细节看到的越少,细节特征是在减少的。
高斯核对图像进行滤波具有压制局部细节的性质。
4)尺度伸缩不变性。
这里只是一个公式推导的问题,对原来的信号加一个变换函数,对变换后的信号再进行高斯核的尺度空间生成,新的信号的极值点等特征是不变的。
Young对经生理学的研究中发现,哺乳动物的视网膜和视觉皮层的感受区域可以很好地用4阶以内的高斯微分来建模。
4 尺度的选择
一般我们采集到的图像中,我们并不知道我们感兴趣的目标在图像中的尺度,在这样的情况下,我们对图像进行分析时就无法选择合适的参数,比如边缘检测,可能由于参数不当,而造成过多的局部细节。
如下图所示:红色圆圈内的斑点的大小(直径)比例对应着两幅图像之间尺度比例(scale ratio)。如果对两幅图像采用相同的固定尺度的LoG检测器检测,很难将这两个斑点检测出来。LoG检测器相当于一个匹配滤波器,只有当LoG的尺度与图片中斑点结构尺度相当时才会有较强的响应。如果用与左图中斑点结构相当大小尺度LoG算子,在中的大斑点的对应的LoG响应很小不能被检测出来,反之亦然。因此固定尺度的LoG斑点检测器不具有尺度不变性。使用尺度空间进行多尺度检测可以将两幅图像中不同尺度的斑点检测出来。但是由于斑点结构是在一定尺度范围之内存在的,比如用5~8尺度的LoG可能都能检测出来右边图像中的斑点结构,所以在尺度空间中进行斑点检测会有重复检测的缺点。
在实际操作中,我们需要定义一个特征响应函数,在不同的尺度空间上寻找一个极值点。比如小猫的金字塔图像分析时,我们定义了一个大小为[w,h]的小猫的模板,用这个模板去与金字塔系列图像匹配,一定有匹配度最佳(即特征响应最强)。
需要注意的是,图像结构往往是在粗糙的尺度上被检测到,此时位置信息未必是最准确的,因此通常图像的尺度分析包含两个阶段:首先在粗尺度上进行特征(结构)检测,然后再在细尺度上进行精确定位。
5.高斯金字塔
Gaussian Pyramid
Imagine the pyramid as a set of layers in which the higher the layer, the smaller the size.
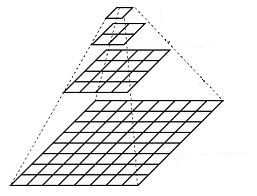
Every layer is numbered from bottom to top, so layer 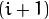 (denoted as
(denoted as 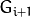 is smaller than layer
is smaller than layer  (
(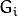 ).
).
To produce layer in the Gaussian pyramid, we do the following:
You can easily notice that the resulting image will be exactly one-quarter the area of its predecessor. Iterating this process on the input image 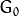 (original image) produces the entire pyramid.
(original image) produces the entire pyramid.
The procedure above was useful to downsample an image. What if we want to make it bigger?:
- First, upsize the image to twice the original in each dimension, wit the new even rows and columns filled with zeros (
 )
)
- Perform a convolution with the same kernel shown above (multiplied by 4) to approximate the values of the “missing pixels”
These two procedures (downsampling and upsampling as explained above) are implemented by the OpenCV functions pyrUp and pyrDown, as we will see in an example with the code below:
Note
When we reduce the size of an image, we are actually losing information of the image.
Code
This tutorial code’s is shown lines below. You can also download it from here
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
#include
#include
#include
using namespace cv;
/// Global variables
Mat src, dst, tmp;
char* window_name = "Pyramids Demo";
/**
* @function main
*/
int main( int argc, char** argv )
{
/// General instructions
printf( "\n Zoom In-Out demo \n " );
printf( "------------------ \n" );
printf( " * [u] -> Zoom in \n" );
printf( " * [d] -> Zoom out \n" );
printf( " * [ESC] -> Close program \n \n" );
/// Test image - Make sure it s divisible by 2^{n}
src = imread( "../images/chicky_512.jpg" );
if( !src.data )
{ printf(" No data! -- Exiting the program \n");
return -1; }
tmp = src;
dst = tmp;
/// Create window
namedWindow( window_name, CV_WINDOW_AUTOSIZE );
imshow( window_name, dst );
/// Loop
while( true )
{
int c;
c = waitKey(10);
if( (char)c == 27 )
{ break; }
if( (char)c == 'u' )
{ pyrUp( tmp, dst, Size( tmp.cols*2, tmp.rows*2 ) );
printf( "** Zoom In: Image x 2 \n" );
}
else if( (char)c == 'd' )
{ pyrDown( tmp, dst, Size( tmp.cols/2, tmp.rows/2 ) );
printf( "** Zoom Out: Image / 2 \n" );
}
imshow( window_name, dst );
tmp = dst;
}
return 0;
}
Explanation
Let’s check the general structure of the program:
Load an image (in this case it is defined in the program, the user does not have to enter it as an argument)
/// Test image - Make sure it s divisible by 2^{n}
src = imread( "../images/chicky_512.jpg" );
if( !src.data )
{ printf(" No data! -- Exiting the program \n");
return -1; }
Create a Mat object to store the result of the operations (dst) and one to save temporal results (tmp).
Mat src, dst, tmp;
/* ... */
tmp = src;
dst = tmp;
Create a window to display the result
namedWindow( window_name, CV_WINDOW_AUTOSIZE );
imshow( window_name, dst );
Perform an infinite loop waiting for user input.
while( true )
{
int c;
c = waitKey(10);
if( (char)c == 27 )
{ break; }
if( (char)c == 'u' )
{ pyrUp( tmp, dst, Size( tmp.cols*2, tmp.rows*2 ) );
printf( "** Zoom In: Image x 2 \n" );
}
else if( (char)c == 'd' )
{ pyrDown( tmp, dst, Size( tmp.cols/2, tmp.rows/2 ) );
printf( "** Zoom Out: Image / 2 \n" );
}
imshow( window_name, dst );
tmp = dst;
}
Our program exits if the user presses ESC. Besides, it has two options:
Perform upsampling (after pressing ‘u’)
pyrUp( tmp, dst, Size( tmp.cols*2, tmp.rows*2 )
We use the function pyrUp with 03 arguments:
- tmp: The current image, it is initialized with the src original image.
- dst: The destination image (to be shown on screen, supposedly the double of the input image)
- Size( tmp.cols*2, tmp.rows*2 ) : The destination size. Since we are upsampling, pyrUp expects a size double than the input image (in this case tmp).
Perform downsampling (after pressing ‘d’)
pyrDown( tmp, dst, Size( tmp.cols/2, tmp.rows/2 )
Similarly as with pyrUp, we use the function pyrDown with 03 arguments:
- tmp: The current image, it is initialized with the src original image.
- dst: The destination image (to be shown on screen, supposedly half the input image)
- Size( tmp.cols/2, tmp.rows/2 ) : The destination size. Since we are upsampling, pyrDown expects half the size the input image (in this case tmp).
Notice that it is important that the input image can be divided by a factor of two (in both dimensions). Otherwise, an error will be shown.
Finally, we update the input image tmp with the current image displayed, so the subsequent operations are performed on it.
Results
After compiling the code above we can test it. The program calls an image chicky_512.jpg that comes in the tutorial_code/image folder. Notice that this image is 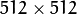 , hence a downsample won’t generate any error (
, hence a downsample won’t generate any error (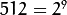 ). The original image is shown below:
). The original image is shown below:

First we apply two successive pyrDown operations by pressing ‘d’. Our output is:

Note that we should have lost some resolution due to the fact that we are diminishing the size of the image. This is evident after we apply pyrUp twice (by pressing ‘u’). Our output is now:
六:补充说明【OpenCV】SIFT原理与源码分析:DoG尺度空间构造
《SIFT原理与源码分析》系列文章索引:http://blog.csdn.net/xiaowei_cqu/article/details/8069548
尺度空间理论
自然界中的物体随着观测
尺度不同有不同的表现形态。例如我们形容建筑物用“米”,观测分子、原子等用“纳米”。更形象的例子比如 Google地图,滑动鼠标轮可以改变观测地图的尺度,看到的地图绘制也不同;还有电影中的拉伸镜头等等……
尺度空间中各尺度图像的模糊程度逐渐变大,能够模拟人在距离目标由近到远时目标在视网膜上的形成过程。
尺度越大图像越模糊。
为什么要讨论尺度空间?
用机器视觉系统分析未知场景时,计算机并不预先知道图像中物体的尺度。
我们需要同时考虑图像在多尺度下的描述,获知感兴趣物体的最佳尺度。另外如果不同的尺度下都有同样的关键点,那么在不同的尺度的输入图像下就都可以检测出来关键点匹配,也就是尺度不变性。
图像的尺度空间表达就是图像在所有尺度下的描述。
尺度空间表达与金字塔多分辨率表达
高斯模糊
高斯核是唯一可以产生多尺度空间的核(《Scale-space theory: A basic tool for analysing structures at different scales》)。一个图像的尺度空间L(x,y,σ) ,定义为原始图像I(x,y)与一个可变尺度的2维高斯函数G(x,y,σ)卷积运算。
二维空间高斯函数:
尺度空间:
尺度是自然客观存在的,不是主观创造的。高斯卷积只是表现尺度空间的一种形式。
二维空间高斯函数是等高线从中心成正太分布的同心圆:
分布不为零的点组成卷积阵与原始图像做变换,即每个像素值是周围相邻像素值的高斯平均。一个5*5的高斯模版如下所示:
高斯模版是圆对称的,且卷积的结果使原始像素值有最大的权重,距离中心越远的相邻像素值权重也越小。
在实际应用中,在计算高斯函数的离散近似时,在大概
3σ
距离之外的像素都可以看作不起作用,这些像素的计算也就可以忽略。所以,通常程序只计算
(6σ+1)*(6σ+1)
就可以保证相关像素影响。
高斯模糊另一个很厉害的性质就是线性可分:使用二维矩阵变换的高斯模糊可以通过在水平和竖直方向各进行一维高斯矩阵变换相加得到。

O(N^2*m*n)次乘法就缩减成了O(N*m*n)+O(N*m*n)次乘法。(N为高斯核大小,m,n为二维图像高和宽)
其实高斯这一部分只需要简单了解就可以了,在OpenCV也只需要一句代码:
- GaussianBlur(dbl, dbl, Size(), sig_diff, sig_diff);
这里详写了一下是因为这块儿对分析算法效率比较有用,而且高斯模糊的算法真的很漂亮~
金字塔多分辨率
金字塔是早期图像多尺度的表示形式。图像金字塔化一般包括两个步骤:使用低通滤波器平滑图像;对平滑图像进行降采样(通常是水平,竖直方向1/2),从而得到一系列尺寸缩小的图像。
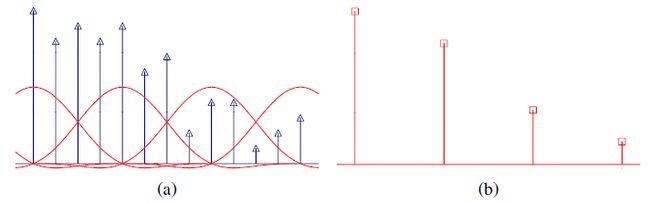
上图中(a)是对原始信号进行低通滤波,(b)是降采样得到的信号。
而对于二维图像,一个传统的金字塔中,每一层图像由上一层分辨率的长、宽各一半,也就是四分之一的像素组成:

多尺度和多分辨率
尺度空间表达和金字塔多分辨率表达之间最大的不同是:
- 尺度空间表达是由不同高斯核平滑卷积得到,在所有尺度上有相同的分辨率;
- 而金字塔多分辨率表达每层分辨率减少固定比率。
所以,金字塔多分辨率生成较快,且占用存储空间少;而多尺度表达随着尺度参数的增加冗余信息也变多。
多尺度表达的优点在于图像的局部特征可以用简单的形式在不同尺度上描述
;而金字塔表达没有理论基础,难以分析图像局部特征。
DoG(Difference of Gaussian)
高斯拉普拉斯LoG金字塔
结合尺度空间表达和金字塔多分辨率表达,就是在使用尺度空间时使用金字塔表示,也就是计算机视觉中最有名的拉普拉斯金子塔( 《The Laplacian pyramid as a compact image code》)。
高斯拉普拉斯LoG(Laplace of Guassian)算子就是对高斯函数进行拉普拉斯变换:
核心思想还是高斯,这个不多叙述。
高斯差分DoG金字塔
DoG(Difference of Gaussian)其实是对高斯拉普拉斯LoG的近似,也就是对

的近似。SIFT算法建议,在某一尺度上的特征检测可以通过对两个相邻高斯尺度空间的图像相减,得到DoG的响应值图像D(x,y,σ)。然后仿照LoG方法,通过对响应值图像D(x,y,σ)进行局部最大值搜索,在空间位置和尺度空间定位局部特征点。其中:
k为相邻两个尺度空间倍数的常数。
上图中(a)是DoG的三维图,(b)是DoG与LoG的对比。
为了得到DoG图像,先要构造高斯金字塔。我们回过头来继续说高斯金字塔~
高斯金字塔在多分辨率金字塔简单降采样基础上加了高斯滤波,也就是对金字塔每层图像用不同参数的σ做高斯模糊,使得每层金字塔有多张高斯模糊图像。
金字塔每层多张图像合称为一组(Octave)
,每组有多张(也叫层Interval)图像。另外,降采样时,金字塔上边一组图像的第一张图像(最底层的一张)是由前一组(金字塔下面一组)图像的倒数第三张隔点采样得到。
以下是OpenCV中构建高斯金字塔的代码,我加了相应的注释:
-
- void SIFT::buildGaussianPyramid( const Mat& base, vector& pyr, int nOctaves ) const
- {
- vector<double> sig(nOctaveLayers + 3);
- pyr.resize(nOctaves*(nOctaveLayers + 3));
-
-
-
-
- sig[0] = sigma;
- double k = pow( 2., 1. / nOctaveLayers );
- for( int i = 1; i < nOctaveLayers + 3; i++ )
- {
- double sig_prev = pow(k, (double)(i-1))*sigma;
- double sig_total = sig_prev*k;
- sig[i] = std::sqrt(sig_total*sig_total - sig_prev*sig_prev);
- }
-
- for( int o = 0; o < nOctaves; o++ )
- {
-
-
- for( int i = 0; i < nOctaveLayers + 3; i++ )
- {
-
- Mat& dst = pyr[o*(nOctaveLayers + 3) + i];
-
- if( o == 0 && i == 0 )
- dst = base;
-
-
-
- else if( i == 0 )
- {
- const Mat& src = pyr[(o-1)*(nOctaveLayers + 3) + nOctaveLayers];
- resize(src, dst, Size(src.cols/2, src.rows/2),
- 0, 0, INTER_NEAREST);
- }
-
-
- else
- {
- const Mat& src = pyr[o*(nOctaveLayers + 3) + i-1];
- GaussianBlur(src, dst, Size(), sig[i], sig[i]);
- }
- }
- }
- }
高斯金字塔的组数为:
代码10-17行是计算高斯模糊的系数σ,具体关系如下:
其中,σ为尺度空间坐标,s为每组中层坐标,σ0为初始尺度,S为每组层数(一般为3~5)。根据这个公式,我们可以得到金字塔组内各层尺度以及组间各图像尺度关系。
组内相邻图像尺度关系:
相邻组间尺度关系:
所以,
相邻两组的同一层尺度为2倍的关系。
最终尺度序列总结为:
o为金字塔组数,n为每组金字塔层数。
构建DoG金字塔
构建高斯金字塔之后,就是用金字塔相邻图像相减构造DoG金字塔。
下面为构造DoG的代码:
-
- void SIFT::buildDoGPyramid( const vector& gpyr, vector& dogpyr ) const
- {
- int nOctaves = (int)gpyr.size()/(nOctaveLayers + 3);
- dogpyr.resize( nOctaves*(nOctaveLayers + 2) );
-
- for( int o = 0; o < nOctaves; o++ )
- {
- for( int i = 0; i < nOctaveLayers + 2; i++ )
- {
-
- const Mat& src1 = gpyr[o*(nOctaveLayers + 3) + i];
- const Mat& src2 = gpyr[o*(nOctaveLayers + 3) + i + 1];
- Mat& dst = dogpyr[o*(nOctaveLayers + 2) + i];
- subtract(src2, src1, dst, noArray(), CV_16S);
- }
- }
- }
SIFT简介
Scale Invariant Feature Transform,尺度不变特征变换匹配算法,是由David G. Lowe在1999年(《Object Recognition from Local Scale-Invariant Features》)提出的高效区域检测算法,在2004年(《Distinctive Image Features from Scale-Invariant Keypoints》)得以完善。
SIFT特征对旋转、尺度缩放、亮度变化等保持不变性,是非常稳定的局部特征,现在应用很广泛。而SIFT算法是将Blob检测,特征矢量生成,特征匹配搜索等步骤结合在一起优化。我会更新一系列文章,分析SIFT算法原理及OpenCV 2.4.2实现的SIFT源码:
- DoG尺度空间构造(Scale-space extrema detection)http://blog.csdn.net/xiaowei_cqu/article/details/8067881
- 关键点搜索与定位(Keypoint localization)http://blog.csdn.net/xiaowei_cqu/article/details/8087239
- 方向赋值(Orientation assignment)http://blog.csdn.net/xiaowei_cqu/article/details/8096072
- 关键点描述(Keypoint descriptor)http://blog.csdn.net/xiaowei_cqu/article/details/8113565
- OpenCV实现:特征检测器FeatureDetectorhttp://blog.csdn.net/xiaowei_cqu/article/details/8652096
- SIFT中LoG和DoG的比较http://blog.csdn.net/xiaowei_cqu/article/details/27692123
OpenCV2.3之后实现了SIFT的代码,2.4改掉了一些bug。本系列文章主要分析OpenCV 2.4.2SIFT函数源码。
SIFT位于OpenCV nonfree的模块, David G. Lowe申请了算法的版权,请尊重作者权力,务必在允许范围内使用。
SIFT in OpenCV
OpenCV中的SIFT函数主要有两个接口。
构造函数:
- SIFT::SIFT(int nfeatures=0, int nOctaveLayers=3, double contrastThreshold=0.04, double edgeThreshold=
- 10, double sigma=1.6)
nfeatures:特征点数目(算法对检测出的特征点排名,返回最好的nfeatures个特征点)。
nOctaveLayers:金字塔中每组的层数(算法中会自己计算这个值,后面会介绍)。
contrastThreshold:过滤掉较差的特征点的对阈值。contrastThreshold越大,返回的特征点越少。
edgeThreshold:过滤掉边缘效应的阈值。edgeThreshold越大,特征点越多(被多滤掉的越少)。
sigma:金字塔第0层图像高斯滤波系数,也就是σ。
重载操作符:
- void SIFT::operator()(InputArray img, InputArray mask, vector& keypoints, OutputArray
- descriptors, bool useProvidedKeypoints=false)
img:8bit灰度图像
mask:图像检测区域(可选)
keypoints:特征向量矩阵
descipotors:特征点描述的输出向量(如果不需要输出,需要传cv::noArray())。
useProvidedKeypoints:是否进行特征点检测。ture,则检测特征点;false,只计算图像特征描述。
函数源码
构造函数SIFT()主要用来初始化参数,并没有特定的操作:
- SIFT::SIFT( int _nfeatures, int _nOctaveLayers,
- double _contrastThreshold, double _edgeThreshold, double _sigma )
- : nfeatures(_nfeatures), nOctaveLayers(_nOctaveLayers),
- contrastThreshold(_contrastThreshold), edgeThreshold(_edgeThreshold), sigma(_sigma)
-
-
- {
- }
主要操作还是利用重载操作符()来执行:
- void SIFT::operator()(InputArray _image, InputArray _mask,
- vector& keypoints,
- OutputArray _descriptors,
- bool useProvidedKeypoints) const
-
-
-
-
-
- {
- Mat image = _image.getMat(), mask = _mask.getMat();
-
- if( image.empty() || image.depth() != CV_8U )
- CV_Error( CV_StsBadArg, "image is empty or has incorrect depth (!=CV_8U)" );
-
- if( !mask.empty() && mask.type() != CV_8UC1 )
- CV_Error( CV_StsBadArg, "mask has incorrect type (!=CV_8UC1)" );
-
-
-
- Mat base = createInitialImage(image, false, (float)sigma);
- vector gpyr, dogpyr;
-
- int nOctaves = cvRound(log( (double)std::min( base.cols, base.rows ) ) / log(2.) - 2);
-
-
-
-
-
- buildGaussianPyramid(base, gpyr, nOctaves);
-
- buildDoGPyramid(gpyr, dogpyr);
-
-
-
-
-
-
- if( !useProvidedKeypoints )
- {
-
- findScaleSpaceExtrema(gpyr, dogpyr, keypoints);
-
- KeyPointsFilter::removeDuplicated( keypoints );
-
-
- if( !mask.empty() )
- KeyPointsFilter::runByPixelsMask( keypoints, mask );
-
-
- if( nfeatures > 0 )
- KeyPointsFilter::retainBest(keypoints, nfeatures);
-
-
- }
- else
- {
-
-
- }
-
-
- if( _descriptors.needed() )
- {
-
- int dsize = descriptorSize();
- _descriptors.create((int)keypoints.size(), dsize, CV_32F);
- Mat descriptors = _descriptors.getMat();
-
- calcDescriptors(gpyr, keypoints, descriptors, nOctaveLayers);
-
-
- }
- }
函数中用到的构造金字塔: buildGaussianPyramid(base, gpyr, nOctaves);等步骤请参见文章后续系列。
[1] opencv教程:图像金字塔
[2] 计算机视觉——算法与应用 3.5节 金字塔与小波
[3] 现代数字图像 1.1节 图像多分辨率真金字塔
[4] OpenCV的5种图像内插方法
[5]
http://www.360doc.com/content/15/1115/12/25664332_513338038.shtml
[6]
http://blog.csdn.net/xiaowei_cqu/article/details/8067881
[7]
http://blog.csdn.net/xiaowei_cqu/article/details/8069548
[8]