Clickhouse基本操作
原文链接:https://blog.csdn.net/liang_0609/article/details/86707845
一、先来说一下,ClickHouse为啥快
ClickHouse有多少CPU,吃多少资源,所以飞快;
ClickHouse不支持事务,不存在隔离级别。这里要额外说一下,有人觉得,你一个数据库都不支持事务,不支持ACID还玩个毛。ClickHouse的定位是分析性数据库,而不是严格的关系型数据库。又有人要问了,数据都不一致,统计个毛。举个例子,汽车的油表是100%准确么?为了获得一个100%准确的值,难道每次测量你都要停车检查么?统计数据的意义在于用大量的数据看规律,看趋势,而不是100%准确。
IO方面,MySQL是行存储,ClickHouse是列存储,后者在count()这类操作天然有优势,同时,在IO方面,MySQL需要大量随机IO,ClickHouse基本是顺序IO。
有人可能觉得上面的数据导入的时候,数据肯定缓存在内存里了,这个的确,但是ClickHouse基本上是顺序IO,用过就知道了,对IO基本没有太高要求,当然,磁盘越快,上层处理越快,但是99%的情况是,CPU先跑满了(数据库里太少见了,大多数都是IO不够用)。
二、创建库
CREATE/ATTACH DATABASE zabbix ENGINE = Ordinary;
ATTACH 也可以建库,但是metadata目录下不会生成.sql文件,一般用于metadata元数据sql文件被删除后,恢复库表结构使用
三、创建本地表
CREATE TABLE test02( id UInt16,col1 String,col2 String,create_date date ) ENGINE = MergeTree(create_date, (id), 8192);
ENGINE:是表的引擎类型,
MergeTree:最常用的,MergeTree要求有一个日期字段,还有主键。
Log引擎没有这个限制,也是比较常用。
ReplicatedMergeTree:MergeTree的分支,表复制引擎。
Distributed:分布式引擎。
create_date:是表的日期字段,一个表必须要有一个日期字段。
id:是表的主键,主键可以有多个字段,每个字段用逗号分隔。
8192:是索引粒度,用默认值8192即可。
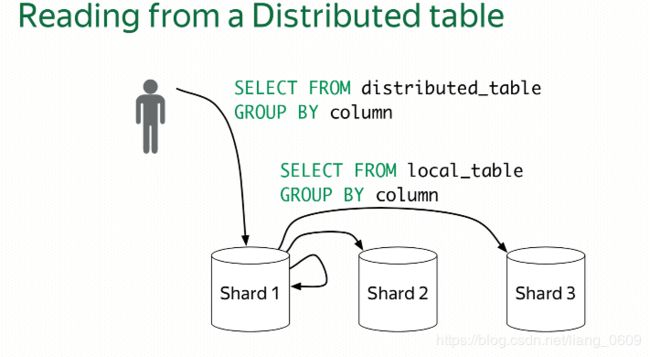
四、创建分布式表
CREATE TABLE distributed_table AS table ENGINE = Distributed(cluster, db, table, rand());
cluster:配置文件中的群集名称。
db:库名。
table:本地表名。
rand():分片方式:随机。
intHash64():分片方式:指定字段做hash。
Distribute引擎会选择每个分发到的Shard中的”健康的”副本执行SQL
五、DDL
如果想按集群操作,需要借助zookeeper,在config.xml中添加配置
一个节点创建表,会同步到各个节点
CREATE TABLE db.table [ON CLUSTER cluster] (...)
添加、删除、修改列
ALTER TABLE [db].table [ON CLUSTER cluster] ADD|DROP|MODIFY COLUMN ...
rename 支持*MergeTree和Distributed
rename table db.table1 to db.table2 [ON CLUSTER cluster]
truncate table db.table;不支持Distributed引擎
六、delete/update 不支持Distributed引擎
ALTER TABLE [db.]table DELETE WHERE filter_expr...
ALTER TABLE [db.]table UPDATE column1 = expr1 [, ...] WHERE ...
七、分区表
按时间分区:
toYYYYMM(EventDate):按月分区
toMonday(EventDate):按周分区
toDate(EventDate):按天分区
按指定列分区:
PARTITION BY cloumn_name
对分区的操作:
alter table test1 DROP PARTITION [partition] #删除分区
alter table test1 DETACH PARTITION [partition]#下线分区
alter table test1 ATTACH PARTITION [partition]#恢复分区
alter table .test1 FREEZE PARTITION [partition]#备份分区
八、数据同步
1) 采用remote函数
insert into db.table select * from remote('目标IP',db.table,'user','passwd')
2) csv文件导入clickhouse
cat test.csv | clickhouse-client -u user --password password --query="INSERT INTO db.table FORMAT CSV"
3) 同步mysql库中表
CREATE TABLE tmp ENGINE = MergeTree ORDER BY id AS SELECT * FROM mysql('hostip:3306', 'db', 'table', 'user', 'passwd') ;
4) clickhouse-copier 工具
九、时间戳转换
select toUnixTimestamp('2018-11-25 00:00:02');
select toDateTime(1543075202);
十、其他事项
1) clickhouse的cluster环境中,每台server的地位是等价的,即不存在master-slave之说,是multi-master模式。
2) 各replicated表的宿主server上要在hosts里配置其他replicated表宿主server的ip和hostname的映射。
3) 上面描述的在不同的server上建立全新的replicated模式的表,如果在某台server上已经存在一张replicated表,并且表中已经有数据,这时在另外的server上执行完replicated建表语句后,已有数据会自动同步到其他server上面。
4) 如果zookeeper挂掉,replicated表会切换成read-only模式,不再进行数据同步,系统会周期性的尝试与zk重新建立连接。
5) 如果在向一张replicated表insert数据的时候zookeeper挂掉,这时候会抛一个异常,等到与zk重新建立连接以后,系统(其他replicated表所在server)会检查本地文件与预期文件(保存在zk上)的差别,如果是轻微的差别,直接同步覆盖,如果发现有数据块损坏或者识别不了,则将这些数据文件移动到“detached”子目录,然后重新根据zk所记录的文件信息进行副本的同步。
6) drop掉某一台server上的replicated表,不会对其他server上面的replicated表造成影响。
————————————————
版权声明:本文为CSDN博主「MYSQL轻松学」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/liang_0609/article/details/86707845