How to Use the uniq Command on Linux
The Linux uniq command whips through your text files looking for unique or duplicate lines. In this guide, we cover its versatility and features, as well as how you can make the most of this nifty utility.
Finding Matching Lines of Text on Linux
The uniq command is fast, flexible, and great at what it does. However, like many Linux commands, it has a few quirks—which is fine, as long as you know about them. If you take the plunge without a bit of insider know-how, you could well be left scratching your head at the results. We’ll point out these quirks as we go.
The uniq command is perfect for those in the single-minded, designed-to-do-one-thing-and-do-it-well camp. That’s why it’s also particularly well-suited to work with pipes and play its part in command pipelines. One of its most frequent collaborators is sort because uniq has to have sorted input on which to work.
Let’s fire it up!
RELATED: How to Use Pipes on Linux
Running uniq with No Options
We’ve got a text file that contains the lyrics to Robert Johnson’s song I Believe I’ll Dust My Broom. Let’s see what uniq makes of it.
We’ll type the following to pipe the output into less:
uniq dust-my-broom.txt | less

We get the entire song, including duplicate lines, in less:

That doesn’t seem to be either the unique lines nor the duplicate lines.
Right—because this is the first quirk. If you run uniq with no options, it behaves as though you used the -u (unique lines) option. This tells uniq to print only the unique lines from the file. The reason you see duplicate lines is because, for uniq to consider a line a duplicate, it must be adjacent to its duplicate, which is where sort comes in.
When we sort the file, it groups the duplicate lines, and uniq treats them as duplicates. We’ll use sort on the file, pipe the sorted output into uniq, and then pipe the final output into less.
To do so, we type the following:
sort dust-my-broom.txt | uniq | less

A sorted list of lines appears in less.
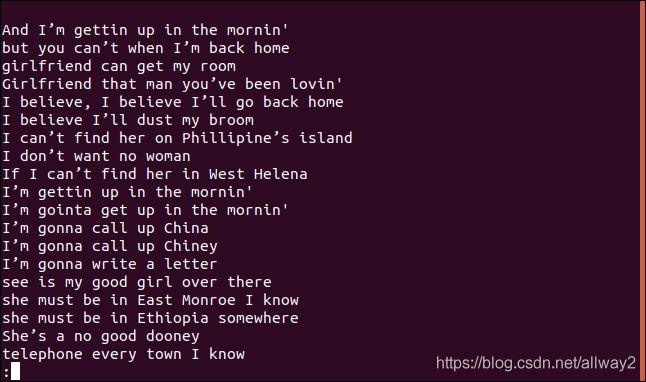
The line, “I believe I’ll dust my broom,” definitely appears in the song more than once. In fact, it’s repeated twice within the first four lines of the song.
So, why is it showing up in a list of unique lines? Because the first time a line appears in the file, it’s unique; only the subsequent entries are duplicates. You can think of it as listing the first occurrence of each unique line.
Let’s use sort again and redirect the output into a new file. This way, we don’t have to use sort in every command.
We type the following command:
sort dust-my-broom.txt > sorted.txt

Now, we have a presorted file to work with.
Counting Duplicates
You can use the -c (count) option to print the number of times each line appears in a file.
Type the following command:
uniq -c sorted.txt | less

Each line begins with the number of times that line appears in the file. However, you’ll notice the first line is blank. This tells you there are five blank lines in the file.

If you want the output sorted in numerical order, you can feed the output from uniq into sort. In our example, we’ll use the -r (reverse) and -n (numeric sort) options, and pipe the results into less.
We type the following:
uniq -c sorted.txt | sort -rn | less

The list is sorted in descending order based on the frequency of each line’s appearance.

Listing Only Duplicate Lines
If you want to see only the lines that are repeated in a file, you can use the -d (repeated) option. No matter how many times a line is duplicated in a file, it’s listed only once.
To use this option, we type the following:
uniq -d sorted.txt

The duplicated lines are listed for us. You’ll notice the blank line at the top, which means the file contains duplicate blank lines—it isn’t a space left by uniq to cosmetically offset the listing.

We can also combine the -d (repeated) and -c (count) options and pipe the output through sort. This gives us a sorted list of the lines that appear at least twice.
Type the following to use this option:
uniq -d -c sorted.txt | sort -rn

Listing All Duplicated Lines
If you want to see a list of every duplicated line, as well as an entry for each time a line appears in the file, you can use the -D (all duplicate lines) option.
To use this option, you type the following:
uniq -D sorted.txt | less

The listing contains an entry for each duplicated line.

If you use the --group option, it prints every duplicated line with a blank line either before (prepend) or after each group (append), or both before and after (both) each group.
We’re using append as our modifier, so we type the following:
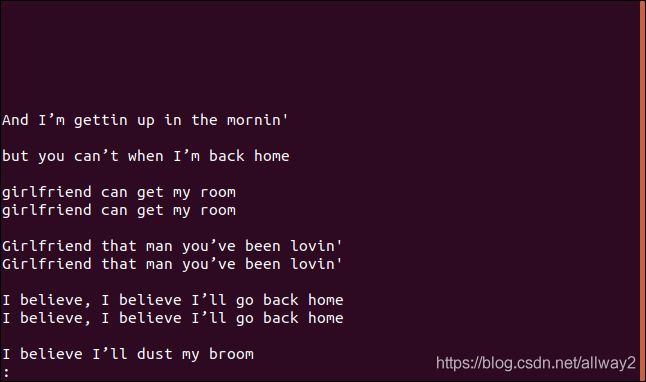
uniq --group=append sorted.txt | less

The groups are separated by blank lines to make them easier to read.
Checking a Certain Number of Characters
By default, uniq checks the entire length of each line. If you want to restrict the checks to a certain number of characters, however, you can use the -w (check chars) option.
In this example, we’ll repeat the last command, but limit the comparisons to the first three characters. To do so, we type the following command:
uniq -w 3 --group=append sorted.txt | less

The results and groupings we receive are quite different.

All lines that start with “I b” are grouped together because those portions of the lines are identical, so they’re considered to be duplicates.
Likewise, all lines that start with “I’m” are treated as duplicates, even if the rest of the text is different.
Ignoring a Certain Number of Characters
There are some cases in which it might be beneficial to skip a certain number of characters at the beginning of each line, such as when lines in a file are numbered. Or, say you need uniq to jump over a timestamp and start checking the lines from character six instead of from the first character.
Below is a version of our sorted file with numbered lines.

If we want uniq to start its comparison checks at character three, we can use the -s (skip chars) option by typing the following:
uniq -s 3 -d -c numbered.txt

The lines are detected as duplicates and counted correctly. Notice the line numbers displayed are those of the first occurrence of each duplicate.
You can also skip fields (a run of characters and some white space) instead of characters. We’ll use the -f (fields) option to tell uniq which fields to ignore.
We type the following to tell uniq to ignore the first field:
uniq -f 1 -d -c numbered.txt

We get the same results we did when we told uniq to skip three characters at the start of each line.
Ignoring Case
By default, uniq is case-sensitive. If the same letter appears capped and in lowercase, uniq considers the lines to be different.
For example, check out the output from the following command:
uniq -d -c sorted.txt | sort -rn

The lines “I Believe I’ll dust my broom” and “I believe I’ll dust my broom” aren’t treated as duplicates because of the difference in case on the “B” in “believe.”
If we include the -i (ignore case) option, though, these lines will be treated as duplicates. We type the following:
uniq -d -c -i sorted.txt | sort -rn

The lines are now treated as duplicates and grouped together.
Linux puts a multitude of special utilities at your disposal. Like many of them, uniq isn’t a tool you’ll use every day.
That’s why a big part of becoming proficient in Linux is remembering which tool will solve your current problem, and where you can find it again. If you practice, though, you’ll be well on your way.