R-CNN三兄弟对比
转载自:xiaoiker

FASTER R-CNN
相比FAST R-CNN,Faster R-CNN主要两处不同:
(1)使用RPN (Region Proposal Network) 代替原来的Selective Search方法产生建议窗口;
(2) 产生建议窗口(Proposal)的CNN和目标检测的CNN共享,减少运算量

(1)输入测试图像;
(2)将整张图片输入CNN,进行特征提取;
(3)用RPN生成建议窗口(proposals),每张图片生成300个建议窗口;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层,使每个RoI生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
RPN由两部分构成:一个卷积层,一对全连接层,二者分别输出分类结果(cls layer)以及 坐标回归结果(reg layer)。卷积层:stride为1,卷积核大小为3*3,输出256张特征图(这一层实际参数为3*3*256*256)。相当于一个sliding window 探索输入特征图的每一个3*3的区域位置。当这个13*13*256特征图输入到RPN网络以后,通过卷积层得到13*13个 256特征图。也就是169个256维的特征向量,每一个对应一个3*3的区域位置,每一个位置提供9个anchor。
于是,对于每一个256维的特征,经过一对 全连接网络(也可以是1*1的卷积核的卷积网络),一个输出 前景还是背景的输出2D;另一个输出回归的坐标信息(x,y,w, h,4*9D,但实际上是一个处理过的坐标位置)。于是,在这9个位置附近求到了一个真实的候选位置。
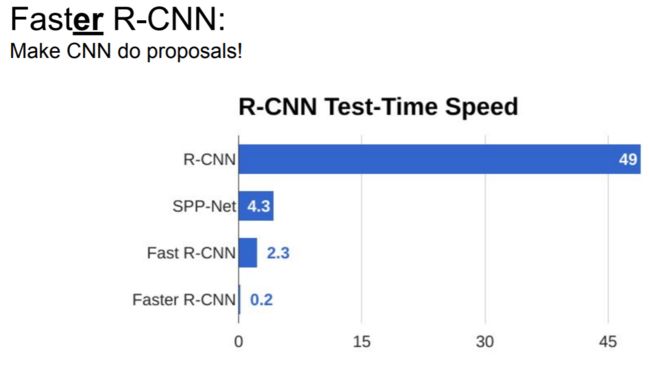
使用效果
在测试阶段,对于每张图片,Faster R-CNN大约是需要0.2s,基本做到了实时反馈。
RPN-anchor机制
anchor是RPN网络的核心。由于目标大小和长宽比例不一,需要多个尺度的窗。Anchor即给出一个基准窗大小,按照倍数和长宽比例得到不同大小的窗。例如论文中基准窗大小为16,给了(8、16、32)三种倍数和(0.5、1、2)三种比例,这样能够得到一共9种尺度的anchor,如图(摘自http://blog.csdn.net/shenxiaolu1984/article/details/51152614)。
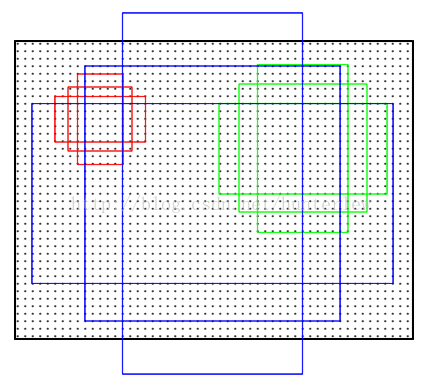
因此,在对60*40的map进行滑窗时,以中心像素为基点构造9种anchor映射到原来的1000*600图像中,映射比例为16倍。那么总共可以得到60*40*9大约2万个anchor。
Anchors:字面上可以理解为锚点,位于之前提到的n*n的sliding window的中心处。对于一个sliding window,我们可以同时预测多个proposal,假定有k个。k个proposal即k个reference boxes,每一个reference box又可以用一个scale,一个aspect_ratio和sliding window中的锚点唯一确定。所以,我们在后面说一个anchor,你就理解成一个anchor box 或一个reference box.作者在论文中定义k=9,即3种scales和3种aspect_ratio确定出当前sliding window位置处对应的9个reference boxes, 4*k个reg-layer的输出和2*k个cls-layer的score输出。对于一幅W*H的feature map,对应W*H*k个锚点。所有的锚点都具有尺度不变性。
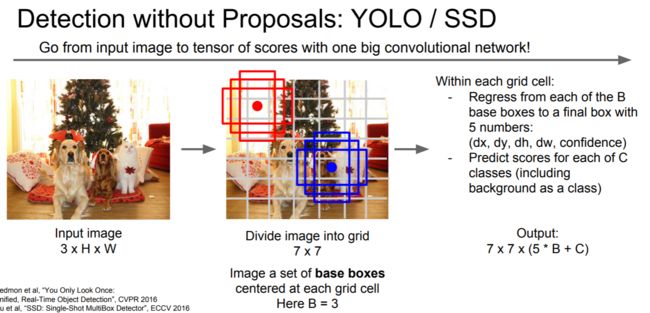
YOLO
RPN的设计相当于是一个sliding window,对最后的特征图feature map上每一个位置都进行了估计,由此找出anchor上面不同变换的proposal,设计非常经典,代价就是sliding window的代价。
相比较 yolo比较暴力 ,直接将图片划为7*7的网格(如下图),估计以网格为中心两个位置也就是总共98个”proposal“。快的很明显,精度和格子的大小有关。该网络将图像划分为区域并且预测每个区域的边界框和概率。这些边界框由预测概率加权。
实施细节
比如RPN网络得到的大约2万个anchor不是都直接给Fast-RCNN,因为有很多重叠的框。通过非极大值抑制的方法,设定IoU为0.7的阈值,即仅保留覆盖率不超过0.7的局部最大分数的box(粗筛)。最后留下大约2000个anchor,然后再取前N个box(比如300个)给Fast-RCNN。
Fast-RCNN将输出300个判定类别及其box,对类别分数采用阈值为0.3的非极大值抑制(精筛),并仅取分数大于某个分数的目标结果(比如,只取分数60分以上的结果)。