ambari hbase 调优
hbase配置
[root@node1 test]# cat /usr/hdp/current/hbase-client/conf/hbase-site.xml
#Todo
dfs.domain.socket.path
/var/lib/hadoop-hdfs/dn_socket
#Todo
hbase.bulkload.staging.dir
/apps/hbase/staging
#每条记录的最大大小为1MB
hbase.client.keyvalue.maxsize
1048576
#hbase client操作失败重新请求数为35
hbase.client.retries.number
35
#当一次scan操作不在本地内存时,需要从disk中获取时,缓存的条数,这里设置为100000条,该值不能大于下文中hbase.client.scanner.timeout.period配置项的值
hbase.client.scanner.caching
100000
下图中的第一个配置项hbase.client.scanner.timeout.period对应的是上文中的Number of Fetched Rows when Scanning from Disk,它的值必须小于下图中的第一个配置项才行。
第二个配置项的话默认是true的,无需额外配置,之前在解决一个相关问题时,将它置为了false。

hbase.client.scanner.timeout.period
120000
#hbase是否配置为分布式
hbase.cluster.distributed
true
#Todo
hbase.coprocessor.master.classes
#Todo
hbase.coprocessor.region.classes
org.apache.hadoop.hbase.security.access.SecureBulkLoadEndpoint
#设置为ture,忽略对默认hbase版本的检查(设置为false的话在maven工程的编译过程中可能会遇到版本相关的问题)
hbase.defaults.for.version.skip
true
#设置系统进行1次majorcompaction的启动周期,如果设置为0,则系统不会主动出发MC过程,默认为7天
hbase.hregion.majorcompaction
604800000
#用来作为计算MC时间周期,与hbase.hregion.majorcompaction相结合,计算出一个浮动的MC时间。默认是0.50,简单来说如果当前store中hfile的最早更新时间早于某个MCTime,就会触发major compaction,hbase通过这种机制定期删除过期数据。MCTime是一个浮动值,浮动区间为[ hbase.hregion.majorcompaction - hbase.hregion.majorcompaction * hbase.hregion.majorcompaction.jitter , hbase.hregion.majorcompaction + hbase.hregion.majorcompaction * hbase.hregion.majorcompaction.jitter ]
hbase.hregion.majorcompaction.jitter
0.50
#单个region的大小为10G,当region大于这个值的时候,一个region就会split为两个,适当的增加这个值的大小可以在写操作时减少split操作的发生,从而减少系统性能消耗而增加写操作的性能,默认是10G,官方建议10G~30G
hbase.hregion.max.filesize
10737418240
#当一个region的memstore总量达到hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size (默认2*128M)时,会阻塞这个region的写操作,并强制刷写到HFile,触发这个刷新操作只会在Memstore即将写满hbase.hregion.memstore.flush.size时put了一个巨大的记录的情况,这时候会阻塞写操作,强制刷新成功才能继续写入
hbase.hregion.memstore.block.multiplier
8
#每个单独的memstore的大小(默认128M),这里调成了256M,每个列族columnfamily在每个region中都分配有它单独的memstore,当memstore超过该值时,就会发生flush操作,将memstore中的内容刷成一个hfile,每一次memstore的flush操作,都会为每一次columnfamily创建一个新的hfile;调高该值可以减少flush的操作次数,减少每一个region中的hfile的个数,这样就会减少minor compaction的次数和split的次数,从而降低了系统性能损耗,提升了写性能,也提升了读性能(因为读操作的时候,首先要去memstore中查数据,查找不到的话再去hfile,hflie存储在hdfs中,这就涉及到了对性能要求较高的io操作了)。当然这个值变大了之后,每次flush操作带来的性能消耗也就更大。
hbase.hregion.memstore.flush.size
268435456
#mslab特性是在分析了HBase产生内存碎片后的根因后给出了解决方案,这个方案虽然不能够完全解决Full GC带来的问题,但在一定程度上延缓了Full GC的产生间隔,总之减少了内存碎片导致的full gc,提高整体性能。
hbase.hregion.memstore.mslab.enabled
true
#当任意一个store中有超过hbase.hstore.blockingStoreFiles个数的storefiles时,这个store所在region的update操作将会被阻塞,除非这个region的compaction操作完成或者hbase.hstore.blockingWaitTime超时。
Block操作会严重影响当前regionserver的响应时间,但过多的storefiles会影响读性能,站在实际使用的角度,为了获取较为平滑的响应时间,可以将该值设得很大,甚至无限大。默认值为7,这里暂时调大到100。
hbase.hstore.blockingStoreFiles
100
#一次minor compaction的最大file数
hbase.hstore.compaction.max
10
#一次minor compaction的最小file数
hbase.hstore.compactionThreshold
4
#本地文件目录用来作为hbase在本地的存储
hbase.local.dir
${hbase.tmp.dir}/local
#todo
#与前文配置项图中第二红线标注的配置项重复
hbase.master.distributed.log.splitting
ture
#hbase master web界面绑定的IP地址(任何网卡的ip都可以访问)
hbase.master.info.bindAddress
0.0.0.0
#hbase master web界面绑定端口
hbase.master.info.port
16010
#todo
hbase.master.port
16000
#分配1%的regionserver的内存给写操作当作缓存,这个参数和下面的hfile.block.cache.size(读缓存)息息相关,二者之和不能超过总内存的80%,读操作时,该值最好为0,但是这里有个bug,取不到0,所以取值1%即0.01,系统尽可能的把内存给读操作用作缓存
hbase.regionserver.global.memstore.size
0.01
#regionserver处理IO请求的线程数,默认是30这里调高到240
hbase.regionserver.handler.count
240
#regionserver 信息 web界面接口
hbase.regionserver.info.port
16030
#regionserver服务端口
hbase.regionserver.port
16020
#todo
hbase.regionserver.wal.codec
org.apache.hadoop.hbase.regionserver.wal.WALCellCodec
#hbase所有表的文件存放在hdfs中的路径,用户可以在hdfs的web页面和后台命令行中查看,若要彻底删除表,现在hbase中删除,然后在hdfs中删除源文件即可,drop命令运行过后hdfs上内容没有删除情况下。
hbase.rootdir
hdfs://node1.dcom:8020/apps/hbase/data
#todo
hbase.rpc.protection
authentication
#hbase rpc操作超时时间
hbase.rpc.timeout
90000
#todo
hbase.security.authentication
simple
#todo
hbase.security.authorization
false
#todo
hbase.superuser
hbase
#本地文件系统上的临时目录,最好不要使用/tmp下的目录,以免重启后丢失文件
hbase.tmp.dir
/tmp/hbase-${user.name}
#zookeeper配置文件zoo.cfg中定义的内容,zookeeper 客户端通过该port连接上zookeeper服务
hbase.zookeeper.property.clientPort
2181
#zookeeper服务的节点数目和各节点名称
hbase.zookeeper.quorum
node1.dcom,node2.dcom,node3.dcom
#zookeeper支持多重update
hbase.zookeeper.useMulti
true
#将regionserver的内存的79%分配作为读缓存,默认是40%,这里因为是单独的读操作性能调优所以调到了79%,上文中提到了一个bug,不能调为最高的80%。该配置项与上文中的hbase.regionserver.global.memstore.size关系密切,二者的总和不能大于regionserver内存的80%,读操作为主时就将该值调高,写操作为主时就将hbase.regionserver.global.memstore.size调高
hfile.block.cache.size
0.79
#todo
phoenix.query.timeoutMs
60000
#zookeeper session会话超时时间
zookeeper.session.timeout
90000
#znode 存放root region的地址
#todo
zookeeper.znode.parent
/hbase-unsecure
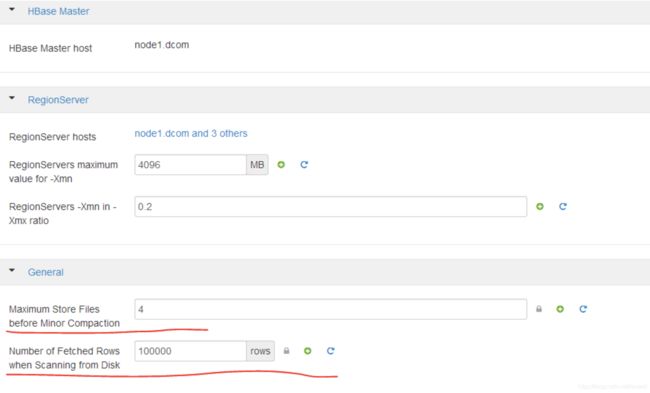
# RegionServers maximum value for –Xmn 新生代jvm内存大小,默认是1024,这里调到了4096,这个参数影响到regionserver 的jvm的CMS GC,64G内存的话建议1~3G,最大为4G,regionserver –Xmn in –Xmx ratio配置项也密切相关,该比例设置的太大或者太小都不好,这方面涉及到的内容太多,后续再详细介绍。
# Number of Fetched Rows when Scanning from Disk这个就是上文中提到的hbase.client.scanner.caching
# Maximum Store Files before Minor Compaction 在执行Minor Compaction合并操作前Store Files的最大数目,默认是3,这里调到了4
————————————————
# The maximum amount of heap to use, in MB. Default is 1000.
#export HBASE_HEAPSIZE=3000 分配给hbase服务的内存,默认是1000,由于hbase较耗内存,所以提高到了3000
这个地方有疑问:这里配置这么小的内存到底是给谁用的?
1)另外还有几个重要的配置参数介绍一下(这里其实是我遇到个一个疑问)
Hbase.regionserver.global.memstore.uppperLimit默认0.4
Hbase.regionserver.global.memstore.lowerLimit默认0.35
一个regionserver会有多个region,多个memstore,所以可能单个region并没有超过阈值,但是整个regionserver的内存占用已经非常多了,上面这两个参数也会去控制和影响内存的刷写,当regionserver上全部的memstore占用超过heap(heap的值在hbase-env.sh中设置,HBASE_HEAPSIZE默认为1000,我们这里设置为3000)的40%时,强制阻塞所有的写操作,将所有的memstore刷写到HFile;当所有的memstore占用超过heap的35%时,会选择一些占用内存比较大的memstore阻塞写操作并进行flush。
注意:
这两个配置项,在当前的环境中并未找到!怀疑是直接当作默认值,用户可以自行添加修改?
Hbase的scan操作是一种批量读取的操作,scan与read不同,scan一次性请求大量数据,默认的话是读取全表,这就需要在客户端的本地占用很大的内存来缓存一次批量拉取的数据,下面介绍一下几个关系密切的配置项。
读取hbase数据的顺序是:
先去memstore中查找,找不到再去blockcahe中,如果没有就去hdfs中查找,找到之后读取的同时保存一份到blockcahe中便于下次查找。
memstore和blockcahe都是在内存中查找速度很快,延时很低,性能很好,而在hdfs中查找和读取就涉及到磁盘的读取操作,磁盘IO消耗性能较大。
(1)hadoop配置
#当一次scan操作不在本地内存时,需要从disk中获取时,缓存的条数,这里设置为100000条,该值不能大于下文中hbase.client.scanner.timeout.period配置项的值。该数值也并不是越高越好,太高的话scan超时时间就会很长,影响性能,一次性获取条数固然多,但由于带宽和其他的限制并不能很好的消化掉,太低当然也不行,配置时需要根据具体情况具体设置。
一条数据长度为9k的话,一次缓存100000条就需要900MB,所以对ycsb client端有较高的内存要求。
#Scanner超时时间,必须大于hbase.client.scanner.caching的数值。这个参数是在配置hbase.client.scanner.caching后hadoop报错之后我自己加的。
Hbase本身提供了读缓存,具体可以查看上面hbase-site.xml文件解析,本集群环境中每个regionserver可提供最多40G左右的读缓存。
简单介绍下Hbase读操作read的原理,首先去memstore中查找,查不到就在读缓存blockcache中查找,再查不到就去hdfs也就是硬盘中查,并且将查到的结果放置在读缓存blockcache中以便下次查找。Blockcache是一个LRU,当blockcache达到上限(heapsize*hfile.block.cache.size*0.85)时,会启动淘汰机制,淘汰掉最老的一批数据。
Scan操作可以设置每次scan取到的条数,一次读的越大每条数据消耗的RPC也就越少,性能也就相应会提高,但是设置的越大对内存的要求也就越高,应根据实际设备性能调整大小。
(1)hadoop配置
这里介绍几个关键配置:
#分配1%的regionserver的内存给写操作当作缓存,这个参数和下面的hfile.block.cache.size(读缓存)息息相关,二者之和不能超过总内存的80%,读操作时,该值最好为0,但是这里有个bug,取不到0,所以取值1%即0.01,系统尽可能的把内存给读操作用作缓存。
#将regionserver的内存的79%分配作为读缓存,默认是40%,这里因为是单独的读操作性能调优所以调到了79%,上文中提到了一个bug,不能调为最高的80%。该配置项与上文中的hbase.regionserver.global.memstore.size关系密切,二者的总和不能大于regionserver内存的80%,读操作为主时就将该值调高,写操作为主时就将hbase.regionserver.global.memstore.size调高。
配置调优要点
本次测试一条数据长度为9KB,共写入40000000条,大概有1TB左右,集群总共是200个region,每个region大小为默认的10G,集群总大小为2TB。集群总量足够,rowkey分布均匀的话不会发生集群的splits操作。
(1)这里简单介绍下hbase 写流程和原理:
客户端流程解析:
a) 用户提交put请求后,HBase客户端会将put请求添加到本地buffer中,符合一定条件就会通过 AsyncProcess异步批量提交。HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;用户可以设置autoflush=false,这样的话put请求会首先放到本地buffer,等到本地buffer大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者采用groupcommit机制提交请求,可以极大地提升写入性能,但是因为没有保护机制,如果客户端崩溃的话会导致提交的请求丢失。
b) 在提交之前,HBase会在元数据表.meta.中根据rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的。如果是批量请求的话还会把这些rowkey按照 HRegionLocation分组,每个分组可以对应一次RPC请求。
c) HBase会为每个HRegionLocation构造一个远程RPC请求 MultiServerCallable
服务器端流程解析
a) 服务器端RegionServer接收到客户端的写入请求后,首先会反序列化为Put对象,然后执行各种检查操作,比如检查region是否是只读、memstore大小是否超过blockingMemstoreSize等。检查完成之后,就会执行如下核心操作:
b) 获取行锁、Region更新共享锁:HBase中使用行锁保证对同一行数据的更新都是互斥操作,用以保证更新的原子性,要么更新成功,要么失败。
c) 开始写事务:获取write number,用于实现MVCC,实现数据的非锁定读,在保证读写一致性的前提下提高读取性能。
d) 写缓存memstore:HBase中每列都会对应一个store,用来存储该列数据。每个store都会有个写缓存memstore,用于缓存写入数据。HBase并不会直接将数据落盘,而是先写入缓存,等缓存满足一定大小之后再一起落盘。
e) Append HLog:HBase使用WAL机制保证数据可靠性,即首先写日志再写缓存,即使发生宕机,也可以通过恢复HLog还原出原始数据。该步骤就是将数据构造为WALEdit对象,然后顺序写入HLog中,此时不需要执行sync操作。0.98版本采用了新的写线程模式实现HLog日志的写入,可以使得整个数据更新性能得到极大提升。
f) 释放行锁以及共享锁
g) Sync HLog:HLog真正sync到HDFS,在释放行锁之后执行sync操作是为了尽量减少持锁时间,提升写性能。如果Sync失败,执行回滚操作将memstore中已经写入的数据移除。
h) 结束写事务:此时该线程的更新操作才会对其他读请求可见,更新才实际生效。
i) flush memstore:当写缓存满256M之后,会启动flush线程将数据刷新到硬盘。刷新操作涉及到HFile相关结构可参考相关资料,这里不细说。
(2)hadoop配置
#当一个region的memstore总量达到hbase.hregion.memstore.block.multiplier* hbase.hregion.memstore.flush.size (默认2*128M)时,会阻塞这个region的写操作,并强制刷写到HFile,触发这个刷新操作只会在Memstore即将写满hbase.hregion.memstore.flush.size时put了一个巨大的记录的情况,这时候会阻塞写操作,强制刷新成功才能继续写入。
该配置项默认为2,调大至8,降低block发生的概率。
#每个单独的memstore的大小(默认128M),这里调成了256M,每个列族columnfamily在每个region中都分配有它单独的memstore,当memstore超过该值时,就会发生flush操作,将memstore中的内容刷成一个hfile,每一次memstore的flush操作,都会为每一次columnfamily创建一个新的hfile;调高该值可以减少flush的操作次数,减少每一个region中的hfile的个数,这样就会减少minor compaction的次数和split的次数,从而降低了系统性能损耗,提升了写性能,也提升了读性能(因为读操作的时候,首先要去memstore中查数据,查找不到的话再去hfile,hflie存储在hdfs中,这就涉及到了对性能要求较高的io操作了)。当然这个值变大了之后,每次flush操作带来的性能消耗也就更大。
#分配75%的regionserver的内存给写操作当作缓存,这个参数和下面的hfile.block.cache.size(读缓存)息息相关,二者之和不能超过总内存的80%,追求写入性能时,该值尽量设置的大一些;追求读操作性能时,该值尽量取得小一些,但这里有个bug,该值取不到0,现将该值设置为0.75。
#与上面相呼应,将regionserver的内存的5%分配作为读缓存,默认是40%,上文中提到了一个bug,不能调为最高的80%。该配置项与上文中的hbase.regionserver.global.memstore.size关系密切,二者的总和不能大于regionserver内存的80%,读操作为主时就将该值调高,写操作为主时就将hbase.regionserver.global.memstore.size调高。