Python高级编程
一切皆对象
所有对象都是type对象的实例,type本身也是,还有就是type和object之间是鸡与蛋的关系
print(type(list)) # >>> type
print(type(type)) # >>> type
print(type(object)) # >>> type
print(type.__bases__) # >> object
常见的内置类型
内置类型的三大特征:id,type,value
- None
- 数值类型:整形,浮点型
- 迭代类型
- 序列类型
- 映射类型
dict - 集合类型
setfrozenset - 上下文管理类型
可使用with - 其他类型:
函数类等...
魔法方法
这类方法一般是通过双下划线开头和结尾:例如熟知的__init__ __new__ __getitem__ __setitem__等众多方法,通过实现魔法方法,可以让python对象更加灵活的使用。
- 特殊的
python语言原生的数据结构,例如list,set,dict,它内部是通过c语言实现,所以在len([1,2,3])时会走捷径,所以效率会快一点。
例如: 如果实现了__enter__方法和__exit__方法,或者使用contextlib简化上下文管理类型,得到的对象可以使用上下文管理器with:
import contextlib
@contextlib.contextmanager
def fileopen(filename):
print('enter') # 打开逻辑
yield {} # yield应该返回打开的文件的句柄
print('exit') # 退出逻辑
with - 嵌套会让代码的可读性不好,所以可以使用这个嵌套的语法
# 嵌套:
with open('1.txt','wb') as f1, open('2.txt','rb') as f2:
# do with f1 and f2
鸭子模型
会呱呱的就是鸭子,会giao人人都是giao哥
例如:list.extend()这个方法接收一个对象,只要这个对象实现了可迭代协议,就可以使用这个方法添加到列表中,这就是鸭子模型接受的参数不一定是某个对象的子类,但是一定实现了对象的某些方法
from collections.abc import Iterable
alist = []
if isinstance(a,Iterable):
alist.extend(a) # >> success
# 注意list的实现是c语言,所以在他和python肯定是有一些对接的问题,list不是Iterable的子类,但list对象是。
list不是Iterable的子类,但list对象 是
抽象基类(abc)
- 场景: 想让子类必须实现一些方法,否则抛出异常
- 不宜过多使用,防止定制过度
type 和isinstance区别:
- type判断一个对象是谁的实例
- isinstance是判断这个对象的继承链,isinstance(a,b)如果a在b的下方就返回True,否则False
类变量和实例变量
- 定义在类中的变量是类变量,在初始化实例的时候定义的变量是实例变量
- 从继承的角度来讲:实例变量可以继承类变量,如果为实例变量赋值,那么在查找时就直接找实例变量,此时删除实例变量,又会去到类变量寻值。
- 类变量是全局可变的,动态的修改了类变量,那么实例中找类变量时是改变后的值
如果把实例看成是类,那么类变量就是父类中的属性,而实例变量是子类的属性,子类中没有父类有 会从父类中继承,子类中有父类有 相当于覆盖重写
class A:
name = 'bb'
def __init__(self,x):
self.x = x
a1 = A(1)
a2 = A(2)
print(a1.name) # 继承类变量bb
print(a1.x) # 就是x
print(A.name) # 类变量bb
A.name = 'dd' # 更改了类变量
print(A.name) # 类变量发生更改dd
print(a1.name) # 实例的类变量也更改dd
a1.name = 'namne' # 为实例属性赋值
print(a1.name) # 不去找类变量,直接就是自己的属性name
print(A.name) # 类变量属于父类,所以还是dd
A.name = 'last' # 在此更改类变量
del a1.name # 删除了实例属性
print(a1.name) # 继承类变量last
类变量和属性的调用顺序
在python中,为了重用代码,可以使用在子类中使用父类的方法,但是在多继承中可能会出现重复调用的问题,例如菱形继承关系
class A:
def __init__(self,*args,**kwargs):
self.sex = sex
class B(A):
def __init__(self,*args,**kwargs):
A.__init__(self,*args,**kwargs)
self.name = name
class C(A):
def __init__(self,*args,**kwargs):
A.__init__(self,*args,**kwargs)
self.age = age
class D(B,C):
def __init__(self,*args,**kwargs):
B.__init__(self,*args,**kwargs)
C.__init__(self,*args,**kwargs)
print(D.mro())
# 实际上会去先找B,然后找A,然后是C,然后是A
为了防止多继承中的一些问题,使用C3算法解决,它能够保证调用链中所有的类仅出现一次,也就是说每个节点后面的类都不继承它,否则将它从调用链中删除,D.mro()查看调用链。
而super()的使用就是基于这条调用链,当使用super()时,会查找调用链,找到当前类,调用写一个类,没有则找下一个。super()默认是当前类,也可以写类名
静态方法、类方法、实例方法
- 静态方法:
@staticmethod
和类的关系不是很大,但是又显得不可缺少,较普通函数来说,和类关系密切 - 类方法:
@classmethod
和类的关系密切,接收必须参数cls表示当前类,因为有了cls,所以创建类的时候方便,修改类变量或者修改属性也比较方便 - 实例方法:
它是实例的方法,接收必须参数selfself表示当前实例,因为有self实例,所以在修改实例变量或者属性的时候会很方便
Python通过双下划线来实现私有属性 : 但并不是不可查看,只是一种规范
class A:
def __init__(self,x):
self.__x = x
a = A(1)
print(a._A__x) # >>> 1 私有属性也查看到了
私有属性的getter和setter: 通过property来实现
def Rec:
def __init__(self,x,y):
self.x = x
self.y = y
self.__z = x*y
@property # 为了让z可以向属性一样调用使用property
def z(self):
return self.__z
@z.setter # 可以使用setter来实现订阅-发布的功能,当新的setter时执行时,for循环遍历订阅者。发布订阅
def z(self,z):
if isinstance(z,type): # 判断
self.__z = z
else :
raise "z必须是怎么怎么样的"
多继承问题
因为多继承会有条调用链,而这条调用链是某种算法计算得到的,一般认知可能会出错,所以在使用的时候,可以先查看调用链在使用
类.mro()
或者使用mixin的模式:在DRF中使用了mixin模式多继承:特点就是 :
1.每个mixin类的特点都比较单一,各个mixin类之间基本没有相同代码,所以不要使用super去继承代码
2. 不和基类关联,可以任意基类组合每个mixin都是组件,可以任意选配
序列
序列类型:
- 容器类型:list,tuple,deque,Queue
内部实现使用的是deque - 扁平序列:str,bytes,bytearray,array.array
- 可变序列:list,deque,bytearray,array
- 不可变序列:str,tuple,bytes
容器抽象基类都放在collections.abc里面
from . import (
Container as Container,
Hashable as Hashable,
Iterable as Iterable,
Iterator as Iterator,
Sized as Sized,
Callable as Callable,
Mapping as Mapping,
MutableMapping as MutableMapping,
Sequence as Sequence,
MutableSequence as MutableSequence,
Set as Set,
MutableSet as MutableSet,
MappingView as MappingView,
ItemsView as ItemsView,
KeysView as KeysView,
ValuesView as ValuesView,
)
例如:是Container类实现了__contains__魔法方法,没实现解释器会去看看是否有__getitem__等方法曲线救国,这是解释器的隐式优化
一个对象通过继承多个抽象基类得到新的对象,有点像drf的mixin。
class Sequence(Reversible, Collection):
class Collection(Sized, Iterable, Container):
# Sized --> __len__
# Iterable --> __iter__ __next__
# Container --> __contains__ __getitem__
class Reversible(Iterable):
切片 ☆☆☆☆ [ : : ]
可以通过接片实现插入查看插入和替换,而替换为None则实现了删除:操作如下
alist = [1,2,3,4]
# 切片时第一个冒号前面默认为0,第二个冒号前默认为-1,最后一个默认为1,第二个位置值过大的不合法就会变为合法值
### 查询 创建
a = alist[::] # 得到一个新列表
b = alist[::-1] # 得到逆序列表
c = alist[::2] # 隔一个取一个,从0开始,也就是偶数位
d = alsit[1::2] # 隔一个去一个 ,从1开始,也就是基数位
### 插入
alist[len(alist):] = [9] # 在尾部添加元素9 >>[1,2,3,4,9]
alist[-1:-1] # 在倒数第二个元素位置添加元素9 >> [1,2,3,9,4] 因为-1取不到,所以是倒数第二个值
alist[0:0] = [0,0] # 在头部添加元素9,9 >> [9,9,1,2,3,4]
alist[2:2] = [1,2] # 在指定位置添加1和2
### 替换
a[::] = [1,2,3] # 从0到最后全部替换
a[::2] = [1,2] # 隔一个替换一个 两边长度相等
需要特别注意:
- 切片对象返回的还是列表,给切片对象赋值时
插入和替换也要使用列表 - 当等号左边切片不连续,那么在替换的时候右边的长度要保证和左边相等,连续就是全替换
- 左闭右开区间
列表的extend接收到是可迭代对象,而+=必须保证符号两边是相同类型,+=是魔法函数实现的,extend是单独实现的
实现可切片对象★★★
Sequence
class Sequence(Reversible, Collection):
# 继承自Reversible,所以需要实现__reversed__
# Collection又继承Sized,Iterable,Container 需要实现__len__,__iter__,__contains__
如果要实现类似的可切片对象其实需要实现相应的魔法方法__getitem__即可
import numbers
class Group:
def __init__(self, staffs):
self.staffs = staffs
def __reversed__(self):
pass
def __getitem__(self, item): # 切片的关键
# return self.staffs[item] #让list代替,但是返回是list类型,所以要生成一个改类的类型
cls = type(self)
if isinstance(item,slice):
return cls(staffs = self.staffs[item]) # 如果是slice对象
elif isinstance(item,numbers.Integral):
return cls(staffs = [self.staffs[item]]) # 如果是int类型,返回某个元素,但是创建类接收的是列表,所以要【】
def __len__(self):
return len(self.staffs)
def __iter__(self):
return iter(self.staffs)
def __contains__(self, item):
if item in self.staffs:
return True
else:
return False
staffs = ['user', 'admin1', 'admin2']
group = Group(staffs=staffs)
sub = group[::2]
if 'user' in sub:
print('Y')
bisect 模块 ·序列·
使得他们可以在插入新数据仍然保持有序,避免先创建在排序而浪费资源
只要是序列就可以使用
bisect = bisect_right
insort = insort_right
# 默认都是后面
import bisect
alist = []
bisect.insort(alist,3)
bisect.insort(alist,2)
bisect.insort(alist,4)
bisect.insort(alist,6)
bisect.insort(alist,5)
print(alist)
print(bisect.bisect(alist,3.1))
# >>>[2, 3, 4, 5, 6]
# >>>2
什么时候duck不必使用list
序列中数据类型一致时,使用array会更好,因为array是一块连续的存储空间,list是不连续的
- 区别: list可以装载不同类型的对象,而array只能装相同数据类型,且要先声明
import array
a = array.array('i') # i表示int d表示double f表示float u表示unicode 等
a.append(1)
a.append(1)
a.append(1)
print(a)
dict和set
get(key,default): 若key不存在则返回default
setdefault(key,default):若key不存在则返回default,并且将default设置到字典中
a_dict = {'q':'Q','w':'W'}
print(a_dict.get('r','R'))
print(a_dict.setdefault('q','QWER'))
print(a_dict)
a_dict.setdefault('r','R')
print(a_dict)
'''output
R
Q
{'q': 'Q', 'w': 'W'}
{'q': 'Q', 'w': 'W', 'r': 'R'}
'''
update方法:合并字典: 接受的参数类型可以是字典,可以是关键字参数的格式,也可以是元组的元组
除了update方法,还可以用强制类型转换的方法合并字典new_dict = dict(a_dict,**c_dict)
a_dict = {'q':'Q','w':'W'}
b_dict = {'r':'R'}
#
a_dict.update(b_dict)
print(a_dict)
#
a_dict.update(i='I')
print(a_dict)
#
a_dict.update((('z','Z'),('x','X')))
print(a_dict)
#
c_dict = {'JJ':'KK'}
new_dict = dict(a_dict,**c_dict)
'''
{'q': 'Q', 'w': 'W', 'r': 'R'}
{'q': 'Q', 'w': 'W', 'r': 'R', 'i': 'I'}
{'q': 'Q', 'w': 'W', 'r': 'R', 'i': 'I', 'z': 'Z', 'x': 'X'}
{'q': 'Q', 'w': 'W', 'r': 'R', 'i': 'I', 'z': 'Z', 'x': 'X', 'JJ': 'KK'}
'''
不要继承dict ,list
继承dict,list在创建的时候不会走python中的方法,会通过c语言已经实现的方法实例化,在添加的时候会用到python中方法,控制性明显差,所以不继承dict,转而继承UserDict
class Mydict(dict):
def __setitem__(self, key, value):
return super().__setitem__(key,value*2)
d1 = Mydict(one = 1)
print(d1)
d1['two'] = 2
print(d1)
'''
{'one': 1}
{'one': 1, 'two': 4}
'''
# 他应该是走了c语言的额捷径,所以魔法函数在创建时没有生效
from collections import UserDict,UserList,User,UserString
继承UserDict就可以让魔法函数生效了,python按照C语言的额语法实现:
可以实现它的__missing__魔法方法,当没有这个key时会去找这个方法,也可以实现__getattr__方法,没有属性调用时就是走这个方法,后面具体说
- defaultdict的使用:value是默认为某种类型
from collections import defaultdict
my = defaultdict(int) # 也可以是dict或者list
print(type(my['das']))
'''
'''
set和frozenset
frozenset是不可变集合freeze --> frozen
# difference 返回差集
s1 = {'a','b','c'}
s2 = set('cef')
ret = s1.difference(s2)
print(ret) # {'a','b'}
ret2 = s1 - s2 # 同上
# 交集
ret3 = s1 & s2
print(ret3) # {‘c’}
# 并集
ret4 = s1 | s2
print(ret4) # {'b', 'c', 'f', 'e', 'a'}
# 子集
print(s1.issubset(ret4)) # 是否为某集合的子集 True
# 超集合
print(ret4.issuperset(s1)) # 是否为某集合的超集 True
dict 和set的实现原理
- list的查找性能远不如dict,而且随着list的数据量增大,会变得越来越慢,而dict就比较平均,但是dict的内存花销大,
python对象都是使用dict进行封装的 - 实现原理 dict和set相同,dict的key和set的值必须可hash,不可变对象str,tuple,frozenset
-
首先字典中的key必须是可hash的,python解释器先申请一段连续的空间,然后对key进行hash运算,并将值放到空间中,当容纳的元素原来越多时,此过程就会出现冲突的几率就越高,当出现冲突时,python通过一个二次探测函数
f计算下一候选位置的addr,如果addr可用则插入,否则继续探测。为了防止大量的冲突,容纳元素超过总长度的2/3时,会扩容,申请一块连续的内存,拷贝过去。所以新增元素的时候可能会使原有的顺序变化,我们不期望的dict是有序的,除非使用OrderDict -
当删除元素的时候,如果删除的元素在中间位置,那么探测链就断开了,所以在采用开放定址的冲突策略中不能真正的删除元素,而是使用伪删除的操作来实现,设置状态为 删除
-
查找时:将对key 哈希定位表元
即实际位置,判断是否为空:如果为空,抛出KeyError异常。如果不为空确认是否冲突例如:查找a,假设a和A的hash相等,hash a 之后得到地址,还要看地址里面的是否为key a,所以要在判断值是否相等,相等那就是找到了,不相等就是错付了,需要散列值的另一部分来定位散列表的另一行,判断是否值相等,如此循环。
list的经典的误导
- 当接收列表作为参数的时候要注意,下面是p1和p2共用的同一个空列表,而列表是可变对象,所以会出现错误。
不让默认的列表变化就可以了:使用切片会得到新的列表
class Person:
def __init__(self,name,staffs=[]):
self.name = name
self.staffs = staffs # 错误
self.staffs = staffs[::] # 将得到的新列表给它
def add(self,name):
self.staffs.append(name)
def remove(self,name):
self.staffs.remove(name)
p1 = Person('Dio')
p2 = Person('JOJO')
p1.add('gui')
print(p2.staffs) # 没有为p2添加员工,竟然有值
print(Person.__init__.__defaults__)
'''
['gui']
(['gui'],)
'''
元类编程
property装饰器
from datetime import date
import datetime
class User:
def __init__(self,name,birthday):
self.name = name
self.birthday = birthday # type:datetime.datetime
self._age = 0
@property
def age(self):
if self._age == 0:
self._age = datetime.datetime.now().year-self.birthday.year
return self._age
else:
return self._age
@age.setter
def age(self,val):
self._age = val
if __name__ == '__main__':
user = User('body',date(year=2001,month=1,day=1))
# user.age = 100
print(user.age)
# print(user.age)
user.age = 100
print(user.age)
'''
19
100
'''
__getattr__ __getattribute__
当类中没有调用的属性的时候就会到 __getattr__ 中。
class User:
def __init__(self,name,birthday):
self.name = name
self.birthday = birthday # type:datetime.datetime
self._age = 0
def __getattr__(self, item):
return f'do not have {item}'
user = User('body',date(year=2001,month=1,day=1))
print(user.activate)
'''
do not have activate
'''
应用2: 没有的属性可能在属性的属性中,可以自定义,简化操作
class User:
def __init__(self,name,birthday,info={}):
self.name = name
self.birthday = birthday # type:datetime.datetime
self._age = 0
self.info = info
def __getattr__(self, item):
return self.info[item]
user = User('body',date(year=2001,month=1,day=1),{'jojo':'NB'})
print(user.jojo)
'''
NB
'''
__getattribute__:调用类属性和方法直接进入它,所以定制不好会导致类不可用,谨慎用。
getattr(instance,'func_name')和__getattr__有区别的,getattr是python自省的内建函数,接受两个参数实例 和属性的字符串,会返回实例的属性。
object对象内部__getattribute__返回的就是
Return getattr(self, name)
属性描述符及属性的查找顺序pro
属性描述符类似于Django中的字段类型,他有两种类型:数据描述符:实现了__get__ __set__ __delete__三个魔法方法;非数据描述符:仅实现了__get__方法
import numbers
class Integer:
def __set__(self, instance, value):
if isinstance(value,numbers.Integral):
self.val = value
else:
raise ValueError(f'need int')
def __get__(self, instance, owner):
return self.val
def __delete__(self, instance):
pass
- 如果属性出现在基类的__dict__中,并且该属性是通过数据描述符修饰,优先级最高,使用数据描述符的__get__方法
class Number:
age = Integer()
n = Number()
n.age = 20
print(n.age)
print(n.__dict__)
'''
20
{}
'''
# 说明age并不是实例中的值。
- 其次:除了上述之外,使用实例为它赋值就会将值放入实例的__dict__中,宰相地位
常用 - 如果属性出现在基类的__dict__中,并且该属性被非数据描述符修饰,此时调用会直接返回它的__get__方法
总结:先入为主
class NoneY:
def __get__(self, instance, owner):
return '1234'
class Number:
age = NoneY()
n = Number()
print(n.age)
print(n.__dict__)
'''
1234
{}
'''
3.1 如果不是非数据描述符,就返回基类的__dict__[属性]
4. 如果还没有找到,到__getattr__中在看看,否则抛出AttributeError。
new和init的区别
- new方法他要返回一个对象,他控制的的是类的生成过程,在new方法调用结束后会使用init方法对类中的属性进行初始化,而如果new方法没有生成类,则不会去执行init方法。
元类
元类:用于创建类的类
type是最大的元类
- type的使用:第一个接收字符串表示类的名字,第二个参数接收一个元组表示该类的基类,第三个参数是字典,表示类的属性。
def say(self):
return self.name
User = type('User',(),{'name':'jojo','say':say}) #这个say函数必须有self参数,和类中保持一致否则Error
user = User()
print(user.name)
print(user.say())
'''
jojo
jojo
'''
一般使用:创建类的时候指明该类的元类metaclass =ABCMeta:该元类就可以控制类实例化的过程
- 类的实例化过程:首先会找当前类中有没有metaclass,如果没有去基类中找metaclass,最后没找到使用type创建类对象,找到了就使用metaclass来创建。
体验元类编程
# 元类编程实现ORM
# 首先我们需要得到两个数据符
# 类似Django name = CharField(db_col,max_length)
# age = IntegerField(db_col,max_length,min_length)
from numbers import *
class CharField:
def __init__(self,db_col,max_length=None):
self._value = None # 让数据描述符默认为None
self.db_col = db_col
if not max_length:
raise ValueError('你必须指定Char类型的最大值')
self.max_length = max_length
# 然后定义get set魔法方法
def __get__(self, instance, owner):
return self._value
def __set__(self, instance, value):
# 在设置值的时候有一些校验,是否为str,是否超出最大值
if not isinstance(value,str):
raise ValueError('必须是字符串类型')
if len(value) > self.max_length:
raise ValueError('字符串长度超出最大值')
class IntegerField:
def __init__(self,min_length,max_length):
self._value = None
if min_length and isinstance(min_length,Integral):
self.min_length = min_length
if max_length and isinstance(max_length,Integral):
self.max_length = max_length
if max_length and min_length and type(max_length) == type(min_length):
if self.min_length > self.max_length:
raise ValueError('最小值不可以大于最大值')
else:
raise ValueError('请你好好传值')
# get,set
def __get__(self, instance, owner):
return self._value
def __set__(self, instance, value):
if not isinstance(value,Integral):
raise ValueError('需要整型参数')
if value < 0:
value = abs(value)
self._value = value
目前完成了字段:下面就是设计模型类,及其模型类元类--------
让ModelMetaClass继承type,现在ModelMetaClass就是一个元类,将User类的元类设置为ModelMetaClass,在创建的时候会直接去ModelMetaClass中完成类的创建。但最终还是由type的完成的,我们使用元类相当于中间件,在type创建类之前做一些操作
class ModelMetaClass(type):
def __new__(cls, *args, **kwargs):
pass
class User(metaclass=ModelMetaClass):
name = CharField(db_col='',max_length=34)
age = IntegerField(db_col='',max_length=3,min_length=1)
class Meta:
db_table = "user"
此时在pass上打个断点:
- 看到元类的__new__方法的args参数:因为args是个元组(‘User’, (), {‘module’: ‘main’, ‘qualname’: ‘User’, ‘name’: <main.CharField object at 0x04B548F0>, ‘age’: <main.IntegerField object at 0x04B54910>, ‘Meta’:
main.User.Meta’>})
类似type: 都是字符串类名,父类元组,类的属性字典:方便args中参数的使用,可以解包
class ModelMetaClass(type):
def __new__(cls, name, bases, attrs, **kwargs): # 解包,方便使用属性
pass
我们现在需要的属性只有name和age,暂时不需要想__module__,__main__这样的属性,让CharField和IntegerField都继承Field ,然后判断如果是Field类型的,我们就存起来
class Field:
pass
class CharField(Field):...
class IntegerField(Field):...
class ModelMetaClass(type):
def __new__(cls, name, bases, attrs, **kwargs):
fields = {}
for key,value in attrs.items:
if isinstance(value,Field):
fields[key] = value
# 这个fields存放的全是关于数据表相关的信息
然后处理Meta中的db_table,Meta中可能还会有很多属性,不止db_table,而Meta中的信息也是和数据表有关:把Meta中的信息抠出来,然后复制给一个字典,字典作为值再放到attrs中
class ModelMetaClass(type):
def __new__(cls, name, bases, attrs, **kwargs):
fields = {}
for key,value in attrs.items():
if isinstance(value,Field):
fields[key] = value
_meta = {}
attrs_meta = attrs.get('Meta',None) # Meta信息
db_table = name.lower() # name是类名,默认使用类名的小写
if attrs_meta:
meta_db_table = getattr(attrs_meta,'db_table',None)
# 因为 attrs_meta就是Meta,是一个类,使用getattr或者属性值
db_table = meta_db_table or name.lower()
# 把值从Meta抠出来 到_meta中
_meta['db_name'] = db_table
# 将Meta中抠出来的值,放到attrs中,因为这些也是和数据表有关
attrs['_meta'] = _meta
# 将之前的fields也放里面
attrs['fields'] = fields
# 现在Meta没有用了
del attrs['Meta']
# 一定要返回一个类,否则无意义,这一步交个type就可以了
return super().__new__(cls, name, bases, attrs, **kwargs)
# 元类创建完对象,也就是执行完new方法,就会到__init__中
class User(metaclass=ModelMetaClass):
name = CharField(db_col='',max_length=34)
age = IntegerField(db_col='',max_length=3,min_length=1)
def __init__(self):
pass # 在这埋个断点
class Meta:
db_table = "user"
user = User()
# 断点调试中,可以看到self中有fields属性,和受保护的_meta属性
此时的init是为了断点调试,其实已经完成了一半了,如果用户在创建时指定了参数,就需要重写init方法了,在User中需要的参数的name和age,但是如果定义别的类就需要自己再重写init方法,参照Django的model,在模型类中并没有自己写init方法。因为Django model都继承了model.Model类
BaseModel:给BaseModel设置metaclasspython解释器会向上找metaclass,所以可以放在比较靠上的位置,让User类继承BaseModel。
**巧妙地运用了setattr和super().init(),先set在让父类中初始化**
# 麻烦的init让BaseModel做
class BaseModel(metaclass=ModelMetaClass):
def __init__(self,*args,**kwargs):
for key,value in kwargs.items():
# 没有使用self.key = value
setattr(self,key,value) #
# 初始化交给父类
return super().__init__()
def save(self):
pass
现在的问题的是:现在BaseModel的元类ModelMetaClass生成的,但是BaseModel里面并没有age,name之类的属性,在ModelMetaClass元类中,如果类名是’BaseModel’ 让type元类去创建,该元类不管他。
class ModelMetaClass(type):
def __new__(cls, name, bases, attrs, **kwargs):
if name == 'BaseModel': ## 添加
return super().__new__(cls, name, bases, attrs, **kwargs)## 这两行够了
在save函数中,拿出来我们的fields属性,sql字段名就是db_col,但是可能没有,没有就是属性的小写
def save(self):
fields = []
values = []
for key, value in self.fields.items(): # type:CharField
# 其中key是属性,value是Field类型,而Field类型有db_col属性
db_col = value.db_col or key.lower()
fields.append(db_col)
value = getattr(self,key) # 获取value的值,
# 也可以通过getattr(value,key) 更容易理解
values.append(str(value))
# sql = "insert user(name,age) value('admin',20)"
sql = f"insert {self._meta['db_name']}({','.join(fields)}) values({','.join(values)})"
print(sql)
完整代码片段
https://gist.github.com/shangdidaren/0d79435eb46e1ac75766e5ce77b80641
迭代器 | 可迭代对象 | 生成器
迭代器 | 可迭代对象
可迭代对象实现了__iter__,需要返回迭代器
迭代器本身:其实最终还是交给了最基本的迭代器类型做这件事,所以可以将该对象的某个属性转换为迭代器在__iter__中返回
例如:Company对象中维护了一个列表,想要遍历就必须让Company的实例是一个可迭代对象,也就是要实现__iter__方法,遍历的对象实际上就是列表,那么将列表转换为iterator返回就可以了
class Company:
def __init__(self,emp_list):
self.emp_list = emp_list
def __iter__(self):
return iter(self.emp_list)
cp = Company(['admin','user','guest'])
iter(cp)
for i in iter(cp):
print(i)
# output
'''
admin
user
guest
'''
迭代器首先要实现__iter__方法,返回它本身,这个在 Iterator 中已经实现 return self,所以继承Iterator,然后去实现它的_next__方法即可,它实际上就是维护了一个索引,然后每次调用next的时候,返回当前索引对应的值,然后 索引+=1
- 为了准守规范,想让一个对象变为迭代器,一般实现一个对应的迭代器类,然后在__iter__方法中返回对应的迭代器
++——+——+——+——+——+——++
如下:让对应的迭代器去专门维护一个索引值。
class Company:
def __init__(self,emp_list):
self.emp_list = emp_list
def __iter__(self):
# return iter(self.emp_list)
return MyIterator(self.emp_list)
class MyIterator(Iterator):
# 已经实现了__iter__方法
def __init__(self,emp_list):
self.iter_list = emp_list
self.index = 0
def __next__(self): # 取值next()
try:
word = self.iter_list[self.index]
except IndexError:
raise StopIteration
self.index += 1
return word
# iter方法交给了MyIterator的__iter__,而这个__iter__又返回MyIterator类型。
生成器
- 如果函数中有yield,那么这个函数就是一个生成器对象。
- 生成器是懒加载的,只有在需要值的时候才会去结算,所以节省内存。
def gen():
yield 1
yield 2
yield 3
f = gen() # f是一个生成器对象,可以用for遍历
for i in f:
print(i)
'''
1
2
3
'''
可以使用dis.dis(callable object) 查看callable object的字节码过程
原理:python解释其会让一个c语言的函数去执行函数function:这个函数会创建一个栈帧,然后运行函数function的字节码dis.dis(),如果在里面发生了函数调用,又会走这一流程,创建栈帧… 所有的栈帧都是分配在堆内存上堆内存不去释放就会一直存在,这就决定了栈帧可以独立于调用者,单独存在。而生成器函数就是由此而来的。
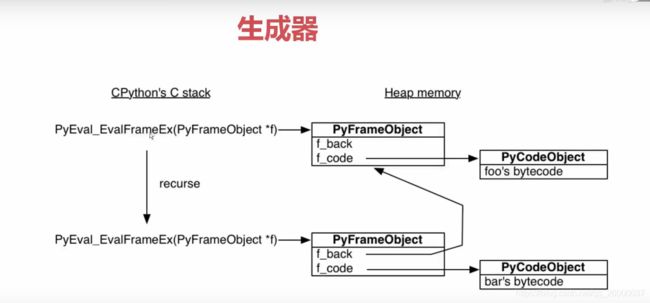
- 生成器每次执行到yield的时候就会停止,然后索引记住前位置
字节码中yield的位置,和函数中的赋值通过字典保存,下次运行的时候从堆中运行索引位置,即实现函数的暂停。
如果实现了
__getitem__也能够在for循环中进行遍历:因为在循环的时候,for会拿着对象的iter() 如果对象没有实现__iter__方法,就会看是否有__getitem__方法,然后这个方法生成一个默认的迭代器对象
生成器读取大文件
首先这个是非常大的数据,另外这个数据只有一行,所以不能使用逐行读取的方式,readlines是将行读到内存中,也不可行,用生成器,判断分隔符yield输出
def one_line_data_read(f, mark):
"""传入读取的文件和标识"""
# 将文件通过分隔符分开转换为生成器,然后再用for循环遍历
buf = "" # 缓冲区
while True:
while mark in buf: # 防止读的块太大,导致buf中有多个{|},所以while没有分隔符的时候才能再次读取chunk块
pos = buf.index(mark)
yield buf[:pos]
buf = buf[pos+len(mark):]
chuck = f.read(4096) # 读取一块
if not chuck:
# 已经到结尾了
yield buf
break
buf += chuck
with open('2.txt') as f:
for i in one_line_data_read(f,'{|}'):
print(i)
Socket实现聊天和多用户连接
## client
import socket
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(('127.0.0.1',8888))
while True:
data = input().encode()
client.send(data)
re_data = client.recv(1024).decode()
print(re_data)
# server
# server 中有两个套接字,一个用来监听,一个用收发信息
import socket
import threading
server = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server.bind(('0.0.0.0', 8888))
server.listen()
def handle_msg(sock, addr):
while True:
data = sock.recv(1024)
print(data.decode())
re_data = input().encode()
sock.send(re_data)
while True:
sock, addr = server.accept()
sock_thread = threading.Thread(target=handle_msg, args=(sock,addr))
sock_thread.start()
Socket模拟Http请求
Socket处于Http协议的下层,他是TCP和UDP的api接口,所以可以模拟http
from urllib.parse import urlparse
import socket
def get_url(url):
url = urlparse(url)
host = url.netloc # 解析主域名
path = url.path # 解析相对路径
if not path:
path = '/'
client = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
client.connect((host, 80)) # 链接80端口
client.send("GET {} HTTP/1.1\r\nHOST:{}\r\nConnection:close\r\n\r\n".format(path,host).encode())
# 规范 GET {相对路径} {协议HTTP/1.1}\r\nHOST:{主域名}\r\nConnection:close\r\n\r\n
# Connection和Host是必须的,有的网站可能还需要其他的,用\r\n分割,两个\r\n表示请求头信息结束
## \r是将光标移到开头,\n是另起一行
# print('first\rlast') # 只会显示last,first会被覆盖
data = b''
while True:
d = client.recv(1024)
if d:
data += d
else:
break
print(data.decode())
client.close()
if __name__ == '__main__':
get_url('http://www.baidu.com')
GIL: 全局解释器锁
- 全局解释器锁:cpython是使用c语言是实现的,使用gil可以保证线程安全,他在同一时间保证只有一个线程在cpu上执行字节码,而I/O操作不受影响。
- GIL不会无限制的占用cpu,当字节码执行到一定长度或者根据时间片轮转他会释放GIL,所以在python中线程是不安全的。
例如两个线程一个做全局变量的+1循环10000;一个做全局变量的-1循环10000次,但是两个线程执行结束后,全局变量的值会发生变化。- 在涉及IO的操作的时候,会释放全局锁防止来回的切换,所以python多线程可以解决IO密集任务。所以GIL也是比较灵活的
多线程、多进程编程
对于IO密集任务,多线程和多进程的速度是相差无几的,多线程会快点,线程是操作系统进行调度的最小单位,所以他是轻量级的,越是I/O密集,多线程的优势越明显。
线程
创建线程的方式
-
简单的多线程可以使用threading.Thread(target=func)来创建
-
复杂一点和可以继承Thread类,并重写run方法实现多线程。
setDaemon主线程结束,自己就结束
join插队
import threading
import time
def func1(start,end):
print(threading.current_thread())
print('start with {}'.format(start))
time.sleep(2)
print('end with {}'.format(end))
def func2(start,end):
print(threading.current_thread())
print('start with {}'.format(start))
time.sleep(4)
print('end with {}'.format(end))
class MThread(threading.Thread):
def __init__(self,name):
super(MThread, self).__init__(name=name)
def run(self) -> None:
print('{} is starting'.format(self.name))
time.sleep(2)
print('over')
if __name__ == '__main__':
# t1 = threading.Thread(target=func1, args=(1, 2), name='q')
# t2 = threading.Thread(target=func2, args=(34, 22), name='w')
# t1.start()
# t2.start()
t = MThread('me')
t.start()
线程通信
1. 线程通信,通过共享变量
- 因为他们处在同一个进程下,所以可以通过共享变量来进行通信。
注意:
当共享的变量过多时,我们呢可以将变量放到一个py文件中进行管理,但要注意的是from some import var和import some,some.var是有区别的,前者是将变量引入不会变了,后者是将变量的指针some引入变量被其他线程修改会变化 - 共享变量是不是安全的,也就带了一些问题,所以需要线程同步
2. 通过Queue通信:
- Queue是线程安全的,内部实现用的deque,效率高
- 通过参数Queue来进行通信,
get队列没值会阻塞put队列满的时候会阻塞qsizeemptyfullgetnowait等。
queue.task_done() ,queue.join()成对出现,表明队列中任务已经完成。
线程同步
-
Lock锁:threading.Lock(),
获取acquire(),释放 release(),或者直接用with上下文
锁要避免死锁多资源竞争,会影响性能 -
Condition条件:线程之间协同合作,内部实现是使用Rlock,有acquire和release,重要的是
wait和notify,前者会等待某个条件,当notify调用时,会通知等待的线程可以开始运行
import threading
# 实现一问一答的模式,线程合作
class TianMao(threading.Thread):
def __init__(self,cond):
self.cond = cond
super(TianMao, self).__init__(name='天猫精灵')
def run(self) -> None:
with cond:
print('小爱同学')
cond.notify()
cond.wait()
print('我们来对诗吧')
cond.notify()
cond.wait()
class XiaoAi(threading.Thread):
def __init__(self,cond):
self.cond = cond
super(XiaoAi, self).__init__(name='天猫精灵')
def run(self) -> None:
with cond:
cond.wait()
print('在')
cond.notify()
cond.wait()
print('好啊')
cond.notify()
if __name__ == '__main__':
cond = threading.Condition()
xiaoai = XiaoAi(cond)
tianmao = TianMao(cond)
xiaoai.start()
tianmao.start()
这里线程的启动顺序可能会影响结果,如果先启动tianmao,那么可能运行完notify之后才会启动xiaoai,导致小爱永远接受不到notify信号,也就无法进行下去
Condition内部实现使用的是RLock,with的操作就是acquire这个RLock的和release这个RLock,所以当a线程with condition的时候,b线程是无法进去with condition的
- 能够继续执行的原因在于wait,wait方法会获取一个锁
内部锁,然后加到Condition的一个双端队列中,然后将Condition的锁释放,这样,就可以让另一个线程的with condition方法执行了,所以一般是先执行wait方法的线程先执行- notify就是从双端队列中弹出一个锁,然后让这个锁释放,需要这个锁的线程就可以执行。
- 所以Condition中有两种锁,一个用来控制Condition的线程安全,另一种锁用来锁资源的方式让线程合作
Queue能够线程安全就是用到了信号量
- Semaphore: 控制进入数量的锁:内部实现是通过Condition,维护一个值,控制进入线程的数量,当数量为0的时候就condition.wait()
类似于进程池,充足的时候随便进,当为0的时候禁止进入,谁用完了就+1,在供其使用
线程池
使用from concurrent.futures import ThreadPoolExecutor:具体使用看下面
concurrent.futures:☆☆☆☆☆
futures可以让多线程和多进程的编码接口一致;可以立即获取任务的状态和返回值,当一个线程完成的时候,主线程可以立刻知道
from concurrent.futures import ThreadPoolExecutor, wait, as_completed
import time
def get_html(times):
time.sleep(times)
print('get_page {} success'.format(times))
return times
excutor = ThreadPoolExecutor(max_workers=2)
task1 = excutor.submit(get_html, 3) # 添加任务,不会阻塞,立即返回给task1结果:是一个Future对象
task2 = excutor.submit(get_html, 2)
# task3 = excutor.submit(get_html, 2)
print(task2.cancel()) # 取消任务,成功返回True,这里加到里面了所以无法取消,如果将max_workers改为1则能正常去取消
# 如果任务进去的时候没有不需要等待,那么就会加载上下文,也就无法取消
print(type(task2))
print(task1.done()) # 判断任务是否执行完
print(task1.result()) # 阻塞的方法,会等待线程执行完返回结果
'''
True
False
get_page 2 success
get_page 3 success
3
'''
1 .获取成功的task的返回:谁先完成谁返回
每当task完成,立马通知主线程:as_completed得到的是生成器
from concurrent.futures import ThreadPoolExecutor, wait, as_completed
import time
def get_html(times):
time.sleep(times)
print('get_page {} success'.format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [1, 2, 3]
all_tasks = [executor.submit(get_html, url) for url in urls]
for future in as_completed(all_tasks):
data = future.result()
print(data)
'''
get_page 1 success
1
get_page 2 success
2
get_page 3 success
3
'''
2. 通过executor获取已完成的task: executor.map的使用
他会按照任务的顺序输出,而不是谁完成谁输出
from concurrent.futures import ThreadPoolExecutor, wait, as_completed
import time
def get_html(times):
time.sleep(times)
print('get_page {} success'.format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [1, 2, 3]
for data in executor.map(get_html,urls):
print(data)
'''
get_page 1 success
1
get_page 2 success
2
get_page 3 success
3
'''
3. wait:让当前线程等待某个或者某些线程执行。
from concurrent.futures import ThreadPoolExecutor, wait, as_completed, ALL_COMPLETED
import time
def get_html(times):
time.sleep(times)
print('get_page {} success'.format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [1, 2, 3]
all_tasks = [executor.submit(get_html, url) for url in urls]
wait(all_tasks,return_when=ALL_COMPLETED)
print('main')
'''
get_page 1 success
get_page 2 success
get_page 3 success
main
'''
在ThreadPoolExecutor中实现了上下文协议,所以可以使用with,futures中的多数类都可以使用with语句,主要是因为他们继承的父类实现了上下文协议
Future对象 - 异步编程的核心: 未来对象,或者说是task的返回容器,此刻可能未完成,但是会随时更新task的状态
进程
充分利用多核优势,使用在cpu密集型的任务上。
创建进程的方式
- 基本的使用和多线程的类似,可以通过
from multiprocessing import Process创建, - 或者继承Process类,并重写run方法实现
进程池:
1. from concurrent.futures import ProcessPoolExecutor,然后使用with管理,和线程池的使用相同。
import time
from multiprocessing import Process
from concurrent.futures import ProcessPoolExecutor
if __name__ == '__main__':
with ProcessPoolExecutor(2) as pool:
ret1 = pool.submit(time.sleep,4)
ret2 = pool.submit(time.sleep,3)
print(ret1,ret2)
2. 另一种更加底层的方式是通过from multiprocessing import Pool
from multiprocessing import Pool
if __name__ == '__main__':
with Pool(4) as pool:
ret1 = pool.apply_async(time.sleep,args=(1,)) # apply_async异步方式,会立刻返回结果,和executor的submit一致
ret2 = pool.apply_async(time.sleep,args=(2,))
ret3 = pool.apply_async(time.sleep,args=(3,))
ret4 = pool.apply_async(time.sleep,args=(4,))
pool.close() # 一定要要关闭之后在join,join是添加到当前的时间循环中
print(ret1,ret2,ret3,ret4)
pool.join()
# print(re1.get()) # get会阻塞等待,因为time.sleep()返回None,所以这会等待一段时间,然后返回None
imap和imap_unordered
- imap按照顺序 2 . imap_unordered谁先完成谁nb
from multiprocessing import Pool
if __name__ == '__main__':
# with ProcessPoolExecutor(2) as pool:
# ret1 = pool.submit(time.sleep,4)
# ret2 = pool.submit(time.sleep,3)
# print(ret1,ret2)
with Pool(4) as pool:
# ret1 = pool.apply_async(time.sleep,args=(1,))
# ret2 = pool.apply_async(time.sleep,args=(2,))
# ret3 = pool.apply_async(time.sleep,args=(3,))
# ret4 = pool.apply_async(time.sleep,args=(4,))
# pool.close()
# # print(ret1,ret2,ret3,ret4)
# pool.join()
# print(ret1.get())
for ret in pool.imap(time.sleep,[1,5,3]):
print(ret)
# 先打印1的None在打印5的None,在打印3的None
for ret in pool.imap_unordered(time.sleep,[1,5,3]):
print(ret)
# 先打印1的None,在打印3的None在打印5的None
进程通信 :进程Queue,Pipe, Manager
- Queue不适用于进程池Pool的通信,可以使用Manager.Queue()解决
- Pipe:简化版的Queue
child,parent = Pipe(),只能用于两个进程间的通信,性能高于Queue - Manager:有dict,list,Array,Queue,NameSpace等可以进行共享内存,共享内存就会出现同步问题
进程同步:
使用Manager对象中的Event,Condition,RLock,Lock等用于进程同步。
协程
- 同步异步:当遇到IO操作时,等待io执行就是同步,切换执行其他操作就是异步
- 阻塞非阻塞:调用函数,直到返回结果前,该函数都被挂起等待
- io模型:阻塞io,非阻塞io,io多路复用,信号驱动,异步io
- c10k问题:无法通过开先线程的方式解决,通过协程
- select,poll,epoll:非阻塞io会一直询问kernel是否准备好,而select可以处理多个文件句柄,有一个变化就可以马上知道,但…还是要for循环去找变化的是哪一个文件句柄。poll没有最大的数量限制,他是使用结构体,然后将结构体的指针传递实现,但是还是要遍历才能确定哪一个文件就绪,大量文件句柄有一个变化就需要全部遍历,效率是低下的。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的事件表中,用户空间和内核空间只需要拷贝一次。但并发高,且连接不活跃的情况下epoll会比较好
例如网站,在并发不高,链接活跃的情况下poll好例如游戏- 信号驱动io,基于信号驱动的。
- 异步io:编码难度较高,io多路复用用的比较多,比较成熟。
select(poll/epoll) + 回调函数 + 事件循环模式:单线程模式实现高并发
小案例:
1. 使用非阻塞IO完成模拟http发出请求的过程
from urllib.parse import urlparse
import socket
def get_url(url):
url = urlparse(url)
host = url.netloc
path = url.path
if not path:
path = '/'
client = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
client.setblocking(False) # 设置为非阻塞IO
try:
client.connect((host, 80)) # 一定会抛出异常,这是正常的,将其捕获就好了
except BlockingIOError:
pass
while True: # 使用send的方法也会抛出异常,因为套接字没有建立好,所以要一直询问,直到成功发送信息,break掉
try:
client.send("GET {} HTTP/1.1\r\nHOST:{}\r\nConnection:close\r\n\r\n".format(path, host).encode())
break
except OSError as e:
pass
data = b''
while True:
try:
d = client.recv(1024) # 可能会他抛异常,捕获之后,继续轮询
except BlockingIOError:
continue
if d:
data += d
else:
break
print(data.decode())
client.close()
if __name__ == '__main__':
get_url('http://www.baidu.com')
2. 使用select + 回调 + 事件循环:
select(poll/epoll) + 回调函数 +事件循环实现小案例:python内部实现select的包
import select但是里面的接口比较底层,难用。
可以使用from selector import DefaultSelector,他会根据操作系统选择select还是epoll
from urllib.parse import urlparse
from selectors import DefaultSelector,EVENT_WRITE,EVENT_READ
import socket
s = DefaultSelector()
urls = ['https:/www.baidu.com','https://www.bing.com/']
STOP = False
# 使用select完成http请求
class Fetcher:
# 链接可用
def connected(self, key):
s.unregister(key.fd) # 进来了就可以将他取消
self.client.send("GET {} HTTP/1.1\r\nHOST:{}\r\nConnection:close\r\n\r\n".format(self.path, self.host).encode())
s.register(self.client.fileno(), EVENT_READ, self.readable)
def readable(self, key):
d = self.client.recv(1024)
if d:
self.data += d
else:
s.unregister(key.fd)
data = self.data.decode()
html_data = data.split('\r\n\r\n')[1]
print(html_data)
self.client.close()
urls.remove(self.spider_url)
if not urls:
global STOP
STOP = True
def get_url(self, url):
self.spider_url = url
url = urlparse(url)
self.host = url.netloc
self.path = url.path
self.data = b''
if not self.path:
self.path = '/'
self.client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.client.setblocking(False)
try:
self.client.connect((self.host, 80))
except BlockingIOError:
pass
# 注册
s.register(self.client.fileno(), EVENT_WRITE, self.connected)
def loop():
# 1 . select 本身是不支持register模式的
# 2 . socket 状态变化后的回调是由程序员完成的,并不是有操作系统自动识别的,`否则就是aio了`
while not STOP:
ready = s.select()
for key, mask in ready: # 在win中会出现异常,因为没有提供参数
call_back = key.data
call_back(key)
if __name__ == '__main__':
fet = Fetcher()
for url in urls:
fet.get_url(url)
loop()
# 难以维护,编码思路不同于同步
# 因为步骤被分的四分五裂,所以管理尽量使用类来管理变量,方便
协程:
生成器技巧实现
send:yield在等号右边的时候,此时它可以接收值,send(None)的作用就是推动生成器,和next()相同,send值的时候,会将值传入到yield左边,并且生成器向前推动
value = yield 1:含义:1 . 将yield的值返回给调用方,2. 调用方通过send的方式将值给生成器。
def gen_func():
yield 1
html = yield 2
print(html)
yield 3
yield 4
if __name__ == '__main__':
gen = gen_func()
print(gen.send(None))
print(gen.send(None))
gen.send("next") # 输出 next,因为生成器向前走,生成器的输出,而不是产出
# print(gen.send('next')) # 输出3
print(next(gen))
'''
1
2
next
4
'''
close(),关闭生成器,继续执行会在生成器中抛出异常,并且向上到close处,不要在生成器中捕获这个异常。
throw向生成器中扔一个异常,可以在扔异常的那一步捕获gen.throw(Exception,'{异常的name}')
★★★ 小知识点:from itertools import chain:可以将迭代对象链接起来
from itertools import chain
alist = [1,2,3]
dict = {4:4,5:5,6:6}
for i in chain(alist,dict,range(7,10)):
print(i)
yield from iterable: 因为这个特性,使得我们的代码可以在函数之间实现切换
这里的
yield from所在的函数是委托方,它会在子生成器和调用方之间建立一条双向通道,调用方send 的数据会流入子生成器
- 流程:创建委托生成器,预激,通过向委托生成器send值,让子生成器接受值,子生成器返回StopIteration异常时,委托将异常捕获,然后将返回值提取,委托生成器再将值进行进一步赋值,或者返回。
final_ret = {}
def sales_sum(pro_name):
total = 0 # 默认的初始量为0
nums = [] # 将send进来的值在转换为一个列表
while True:
x = yield
# print(pro_name, '销量',x)
if not x:
break
total += x
nums.append(x)
return total,nums
def middle(key):
while True:
final_ret[key] = yield from sales_sum(key)
# print(f'key:{key} 统计完成')
def main(): # 协程实现
data_sets = dict(
bobby面膜=[1200, 1300, 1500],
bobby手机=[25, 35, 45, 65],
bobby大衣=[200, 400, 600]
)
for key, data_set in data_sets.items():
# print(f'start key {key}')
m = middle(key) # 委托生成器
m.send(None) # 预激协程
for value in data_set:
m.send(value)
m.send(None)
# print(f'over final_ret :{final_ret}')
def main2(): # 同步实现
final_ret = {}
data_sets = dict(
bobby面膜=[1200, 1300, 1500],
bobby手机=[25, 35, 45, 65],
bobby大衣=[200, 400, 600]
)
for key,data_set in data_sets.items():
tatal = 0
for i in data_set:
tatal += i
final_ret[key] = tatal,data_set
print(final_ret)
import time
if __name__ == '__main__':
s = time.perf_counter()
main()
print(time.perf_counter()-s)
d = time.perf_counter()
main2()
print(time.perf_counter()-d)
## 协程可能会略有优势,一点点,因为没有遇到大io操作,所以不明显,有优势是因为还是有的地方会有超简单的io,基本上是相等的
原生协程
asyncawait关键字:将协程和生成器严格区分
async 将函数声明为一个协程,内部不再允许使用yield
await 跟的对象必须是Awaitable的,即await内部虽然是使用生成器来实现的协程,但是为了语义明确保证各司其职,await是不可以跟生成器的,除非通过@types.coroutine装饰器进行装饰。await可以理解为yield from
- 协程加事件循环的方式实现高并发:少了麻烦
变量的状态,异常的处理,同步格式的编码让代码可读
asyncio并发
它使用的是协程,解决的是异步IO的问题,协程搭配事件循环才能发挥效力

- 事件循环
import asyncio
import time
async def get_html(url):
print(f'start url:{url}')
await asyncio.sleep(2)
print(f'{url}end')
if __name__ == '__main__':
start_time = time.perf_counter()
loop = asyncio.get_event_loop() # 获取当前的事件循环,如果没有就创建一个
# loop = asyncio.get_running_loop() # 获取当前的事件循环,如果没有就异常
tasks = [get_html(f'http://www.baidu.com/{i}') for i in range(9)]
loop.run_until_complete(asyncio.wait(tasks))
print(time.perf_counter()-start_time)
'''
start url:http://www.baidu.com/2
start url:http://www.baidu.com/3
start url:http://www.baidu.com/4
start url:http://www.baidu.com/5
start url:http://www.baidu.com/6
start url:http://www.baidu.com/0
start url:http://www.baidu.com/7
start url:http://www.baidu.com/8
start url:http://www.baidu.com/1
## 约2秒后
http://www.baidu.com/2end
http://www.baidu.com/4end
http://www.baidu.com/7end
http://www.baidu.com/1end
http://www.baidu.com/0end
http://www.baidu.com/8end
http://www.baidu.com/6end
http://www.baidu.com/3end
http://www.baidu.com/5end
2.0059278999999997
Process finished with exit code 0
'''
- 回调
add_done_callback实现在Future中
可以配合partialfrom functools import partial使用,如果callback需要接受参数url,那么就在add_done_callback,参数为partial(callback,url=‘http://www.baidu.com’)。
import asyncio
import time
async def get_html(url):
print(f'start url:{url}')
await asyncio.sleep(2)
return 'bb'
def callback(future):
# def callback(url,fut) 不放在前面也可以
print('send email to me')
print(url)
if __name__ == '__main__':
loop = asyncio.get_event_loop() # 获取当前的事件循环,如果没有就创建一个
# 1. 添加future对象到事件循环中
# get_future = asyncio.ensure_future(get_html(f'http://www.baidu.com/1'))
# loop.run_until_complete(get_future)
# print(get_future.result())
# 2. 添加task对象到事件循环中
task = loop.create_task(get_html('http://www.baidu.com/1'))
loop.run_until_complete(task)
# todo 为某个协程函数添加回调函数:回调函数必须参数future,会由asyncio给他传过去
task2 = loop.create_task(get_html('http://www.baidu.com/2'))
task2.add_done_callback(callback)
from functools import partial
# task2.add_done_callback(partial(callback,url = 'this is perfect'))
loop.run_until_complete(task2)
- gather和wait的区别:gather聚合,实现了wait的功能,它可以进行分组操作
tasks1 = [get_html(f'http://www.baidu.com/{i}') for i in range(9)]
task2 = loop.create_task(get_html('http://www.baidu.com/2'))
loop.run_until_complete(asyncio.gather(*tasks1,task2))
# 或者这样更能显示分组的概念
group1 = asyncio.gather(*tasks1)
group2 = asyncio.gather(task2)
group2.cancel() # 取消
loop.run_until_complete(asyncio.gather(group1,group2))
- 协程的取消和协程的嵌套
# 没太搞懂
# 假设我们通过ctrl + c来取消
# 通过捕获Key异常
tasks = [task1,task2,task3]
loop = asyncio.get_event_loop()
try:
loop.run_until_cimplete(asyncio.wait(tasks))
except KeyboardInterrupt as e:
for task in asyncio.all_tasks():
print(task.cancel())
loop.stop()
loop.run_forever() # 在stop后一定要run_forever,否则可能会抛出异常
finally:
loop.close()
# 协程嵌套的结果就是调用方和子生成器`协程`建立连接,子生成器在await的时候会和调用方联系,在StopIteration异常的时候会给父协程联系
call_latercall_soon,call_at,call_soon_thread_safe
call_later(delay, callback, *args):延迟调用
call_at(time, callback, *args):time是loop.time(),在某时刻调用
call_soon(callback,*args): 等到下一个循环的时候执行
线程安全的call_soon
ThreadExecutor 配合asyncio
- 如果有阻塞的代码
可以将阻塞的代码方法线程池中ThreadExecutor中运行
loop.run_in_executor(executor, fun, *args):如果没有传入executor,会生成默认的。
asyncio模拟http请求
import asyncio
import socket
from urllib.parse import urlparse
async def get_url(url):
url = urlparse(url)
host = url.netloc
path = url.path
if not path:
path = '/'
reader, writer = await asyncio.open_connection(host, 80) # 协程的方式建立连接
writer.write("GET {} HTTP/1.1\r\nHOST:{}\r\nConnection:close\r\n\r\n".format(path, host).encode())
# 然后reader中就会有数据
all_lines = []
async for row_data in reader:
all_lines.append(row_data.decode())
html = '\n'.join(all_lines)
return html
async def main():
tasks = []
for _ in range(20):
url = 'https://www.baidu.com'
tasks.append(asyncio.ensure_future(get_url(url)))
for task in asyncio.as_completed(tasks):
ret = await task
print(ret)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())