基于基尼指数的决策树特征选择算法(CART)及其python实现
基于基尼指数的决策树特征选择算法(CART)及其python实现
基尼指数
与信息增益和增益率类似,基尼指数是另外一种度量指标,由CART决策树使用,其定义如下:

对于二类分类问题,若样本属于正类的概率为 p,则基尼指数为:
![]()
对于给定的样本集合D,其基尼指数定义为:
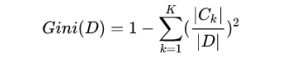
其中Ck是D中属于第k类的样本子集。
如果样本集合D被某个特征A是否取某个值分成两个样本集合D1和D2,则在特征A的条件下,集合D的基尼指数定义为:
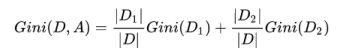
基尼指数Gini(D)反应的是集合D的不确定程度,跟熵的含义相似。Gini(D,A)反应的是经过特征A划分后集合D的不确定程度。所以决策树分裂选取Feature的时候,要选择使基尼指数最小的Feature,但注意信息增益则是选择最大值,这个值得选取是相反的。
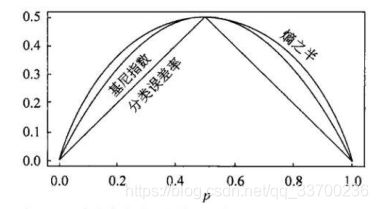
下图表示二分类问题中基尼指数Gini(P)、熵的一半1/2H(P)和分类误差率的关系,横坐标表示概率p,纵坐标表示损失,可以看出基尼指数和熵的一半的曲线很接近,都了一近似的代表分类误差率。
算法的python实现
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 14 17:36:57 2019
@author: Auser
"""
from numpy import *
import numpy as np
import pandas as pd
from math import log
import operator
#计算数据集的基尼指数
def calcGini(dataSet_train):
labelCounts={}
#给所有可能分类创建字典
for featVec in dataSet_train:
currentLabel=featVec[-1]#训练数据的类别列
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
Gini=1.0
#以2为底数计算香农熵
for key in labelCounts:
prob = float(labelCounts[key])/len(dataSet_train)
Gini-=prob*prob
return Gini
def split_data(dataSet_train,feature_index,value):#按照选出的最优的特征的特征值将训练集进行分裂,并将使用过的特征进行删除
'''
划分数据集,特征为离散的
feature_index:用于划分特征的列数,例如“年龄”
value:划分后的属性值:例如“青少年”
'''
data_split=[]#划分后的数据集
for feature in dataSet_train:#遍历训练集
if feature[feature_index]==value:#如果训练集的特征索引的值等于划分后的属性值
reFeature=feature[:feature_index]#删除使用过的特征
reFeature=list(reFeature)
reFeature.extend(feature[feature_index+1:])
data_split.append(reFeature)
return data_split
'''
def split_countinue_data(dataSet_train,feature_index,value,direction):
data_split=[]
for feature in dataSet_train:
if feature[feature_index]>value:
reFeature=feature[:feature_index]
reFeature=list(reFeature)
reFeature.extend(feature[feature_index+1:])
data_split.append(reFeature)
else:
if feature[feature_index]<=value:
reFeature=feature[:feature_index]
reFeature=list(reFeature)
reFeature.extend(feature[feature_index+1:])
data_split.append(reFeature)
return data_split
'''
#选择最好的数据集划分方式
def choose_best_to_split(dataSet_train,featname):
min_Gini_index=10000#初始化最小的基尼指数
Gini_index=0
best_feature_index=-1
feature=len(dataSet_train[0])-1
for i in range(feature):#遍历特征
feature_list=[extend[i] for extend in dataSet_train]
unique=set(feature_list)#对每个特征值列去重
for value in unique:
sub_data=split_data(dataSet_train,i,value)
prob=len(sub_data)/float(len(dataSet_train))
Gini_index+=prob*calcGini(sub_data)
if(Gini_index<min_Gini_index):
min_Gini_index=Gini_index
best_feature_index=i
return best_feature_index
'''
feature=len(dataSet_train[0])-1#特征数量
min_Gini_index=10000#初始化最小基尼指数
new_gini_index=0
best_feature_index=-1
best_split_dict={}
for i in range(feature):#
feature_list=[extend[i] for extend in dataSet_train]
#当特征是连续的,将数据集按照特征的划分点分为左右两部分
if isinstance(feature_list[0],int) or isinstance(feature_list[0],float):
sort_feature_list=sorted(feature_list)#对特征列进行排序
split_point_list=[]
for j in range(len(sort_feature_list)-1):#遍历排序后的特征列
split_point_list.append((sort_feature_list[j]+sort_feature_list[j+1])/2.0)
#slen=len(split_point_list)
for j in range(len(split_point_list)):#遍历排序后的划分点列表
#遍历划分点
new_Gini_index_0=0
new_Gini_index_1=0
#左子集
sub_data_0=split_countinue_data(dataSet_train,i,split_point_list[j],0)
#右子集
sub_data_1=split_countinue_data(dataSet_train,i,split_point_list[j],1)
prob_0=len(sub_data_0)/float(len(dataSet_train))
prob_1=len(sub_data_1)/float(len(dataSet_train))
new_Gini_index_0+=prob_0*calcGini(sub_data_0)
new_Gini_index_1+=prob_1*calcGini(sub_data_1)
new_Gini_index=new_Gini_index_0+new_Gini_index_1
if(min_Gini_index>new_Gini_index):
min_Gini_index=new_Gini_index
best_feature_index=i
best_split_dict[featname[i]]=split_point_list[best_feature_index]
GiniIndex=min_Gini_index
#当特征是离散的
else:
unique=set(feature_list)
#new_gini_indx=0#初始化基尼指数
for value in unique:
#遍历每个特征的取值
sub_data=split_data(dataSet_train,i,value)
prob=len(sub_data)/float(len(dataSet_train))
new_gini_index+=prob*calcGini(sub_data)
GiniIndex=new_gini_index
if(min_Gini_index>GiniIndex):
min_Gini_index=GiniIndex
best_feature_index=i
#如果当前的最佳划分特征为连续特征,将其以之前记录的划分点位界进行二值化处理
#判断是否小于等于best_split_point
if isinstance(dataSet_train[0][best_feature_index],int) or isinstance(dataSet_train[0][best_feature_index],float):
best_split_value=best_split_dict[featname[best_feature_index]]
featname[best_feature_index]=featname[best_feature_index]+'<='+str(best_split_value)
for i in range(np.shape(dataSet_train)[0]):#遍历特征维数
if(dataSet_train[i][best_feature_index]<=best_split_value):#当样本i的最优特征值小于分裂特征值
dataSet_train[i][best_feature_index]=1#将样本i的最优特征值赋1
else:
dataSet_train[i][best_feature_index]=0#否则,赋0
return best_feature_index
'''
def most_occur_label(classList):
#sorted_label_count[0][0] 次数最多的类标签
label_count={}#创建类别标签字典,key为类别,item为每个类别的样本数
for label in classList:#遍历类列表
if label not in label_count.keys():#如果类标签不在类别标签的字典中
label_count[label]=0#将该类别标签置为零
else:
label_count[label]+=1#否则,给对应的类别标签+1
#按照类别字典的值排序
sorted_label_count = sorted(label_count.items(),key = operator.itemgetter(1),reverse = True)
return sorted_label_count[0][0]#返回样本量最多的类别标签
def build_decesion_tree(dataSet_train,featnames):#建立决策树
'''
字典的键存放节点信息,分支及叶子节点存放值
'''
featname = featnames[:] ################特证名
classlist = [featvec[-1] for featvec in dataSet_train] #此节点的分类情况
if classlist.count(classlist[0]) == len(classlist): #全部属于一类
return classlist[0]
if len(dataSet_train[0]) == 1: #分完了,没有属性了
return most_occur_label(classlist) #少数服从多数,返回训练样本数最多的类别作为叶节点
# 选择一个最优特征的最优特征值进行划分
bestFeat = choose_best_to_split(dataSet_train,featname)#选取特征下标
bestFeatname = featname[bestFeat]
del(featname[bestFeat]) #防止下标不准
DecisionTree = {bestFeatname:{}}
#print(DecisionTree)
# 创建分支,先找出所有属性值,即分支数
allvalue = [vec[bestFeat] for vec in dataSet_train]#将每个训练样本的最优特征值作为分裂时的特征值
specvalue = sorted(list(set(allvalue))) #对分支使有一定顺序
'''
if isinstance(dataSet_train[0][bestFeat],str):#当特征之是字符型
currentfeature=featname.index(featname[bestFeat])
feat_value=[example[currentfeature] for example in dataSet_train]
unique=set(feat_value)
del(featname[bestFeat])
#对于bestFeat的每个取值,划分出一个子树
for value in specvalue:
copyfeatname=featname[:]
if isinstance(dataSet_train[0][bestFeat],str):
unique.remove(value)
DecisionTree[bestFeatname][value]=build_decesion_tree(split_data(dataSet_train,bestFeat,value),copyfeatname)
if isinstance(dataSet_train[0][bestFeat],str):
for value in unique:
DecisionTree[bestFeatname][value]=most_occur_label(classlist)
return DecisionTree
'''
for v in specvalue:#遍历选中的最优特征的每个特征取值
copyfeatname = featname[:]#复制特证名,在下一轮建造子树时使用
# print(copyfeatname)
#递归建造决策树,split——data()对源数据集进行分裂,
DecisionTree[bestFeatname][v] = build_decesion_tree(split_data(dataSet_train,bestFeat,v),copyfeatname)
return DecisionTree
def classify(Tree, featnames, X):#对测试集使用训练好的决策树进行分类
#classLabel=' '
global classLabel
root = list(Tree.keys())[0]#构建树的根
firstDict = Tree[root]#树的根给第一个字典
featindex = featnames.index(root) #根节点的属性下标
#classLabel='0'
for key in firstDict.keys(): #根属性的取值,取哪个就走往哪颗子树
if X[featindex] == key:#如果测试样本的特征索引等于key
if type(firstDict[key]) == type({}):#如果第一个字典的关键字中的内容等于type
classLabel = classify(firstDict[key],featnames,X)#递归调用分类
else:
classLabel = firstDict[key]
return classLabel
'''
import re#生成二叉树的分类
def classify(Tree,featnames,X):
classLabel=''#类别标签
firstStr=list(Tree.keys())[0]
if '<=' in firstStr:
featvalue=float(re.compile("(<=.+)").search(firstStr).group()[2:])
featKey=re.compile("(.+<=)").search(firstStr).group()[:-2]
secondDict=Tree[firstStr]
featIndex=featnames.index(featKey)
if X[featIndex]<=featvalue:
judge=1
else:
judge=0
for key in secondDict.keys():
if judge==int(key):
if isinstance(secondDict[key],dict):
classLabel=classify(secondDict[key],featnames,X)
else:
classLabel=secondDict[key]
else:
secondDict=Tree[firstStr]
featIndex=featnames.index(firstStr)
for key in secondDict.keys():
if X[featIndex]==key:
if isinstance(secondDict[key],dict):
classLabel=classify(secondDict[key],featnames,X)
else:
classLabel=secondDict[key]
return classLabel
'''
#计算叶结点数
def getNumLeafs(Tree):
numLeafs = 0
firstStr = list(Tree.keys())[0]
secondDict = Tree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':# 测试结点的数据类型是否为字典
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
# 计算树的深度
def getTreeDepth(Tree):
maxDepth = 0
firstStr = list(Tree.keys())[0]
secondDict = Tree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':# 测试结点的数据类型是否为字典
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth