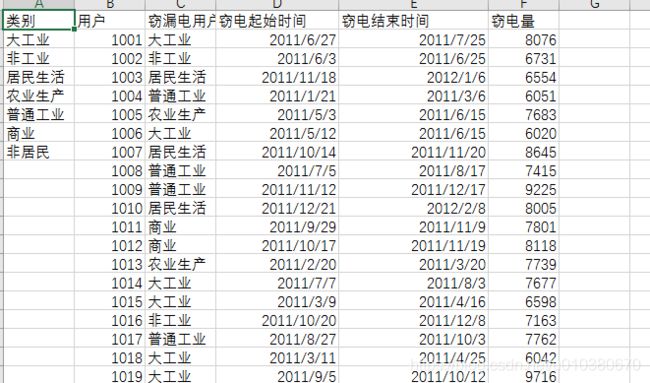
# 计算每类用户类别及用户数
Type <- table(data_FB[, 3])
# 方法1:基础绘图
p <- barplot(Type, space = 0, ylim = c(0, 30), col = rainbow(7), xaxt = "n",
ylab = "计数", main = "窃电用户用电类别分布分析")
df <- data.frame(Type)
axis(1, p, df$Var1, las = 2)
text(p, Type, labels = Type,pos = 3) # 添加数值标签
# xaxt="n"设置是否显示x轴信息,axes=F不显示坐标轴
# 颜色可以用heat.colors,terrain.colors,cm.colors等
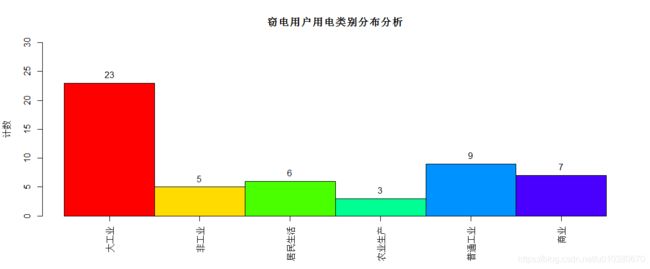
# 方法2:饼图
Type <- data.frame(Type)
pct <- round(Type$Freq / sum(Type$Freq) * 100, 1)
lbls <- paste0(Type$Var1, pct, "%")
pie(Type$Freq, labels = lbls) # 普通饼图
library(plotrix) # 3D饼图
pie3D(Type$Freq, labels = lbls, main = "窃电用户用电类别分布",
labelrad = 1.4, start = 3)
pie3D(Type$Freq, labels = lbls, explode = 0.1, radius = 1)
# radius半径,explode分离度
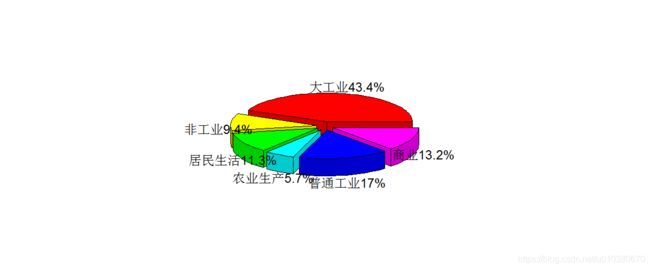
# ----------------------------正常用户用电量趋势分析---------------------------
Regular <- read.csv("正常用电量数据.csv",header=T)
# 基础绘图
plot(1:59, Regular[, 2], type = "l", col = "blue",
main = "正常用户的用电量趋势") # 主标题,x,y轴标题
# ---------------------------窃漏电用户用电量趋势分析--------------------------
Unusual <- read.csv("窃电用电量数据.csv", header = T)
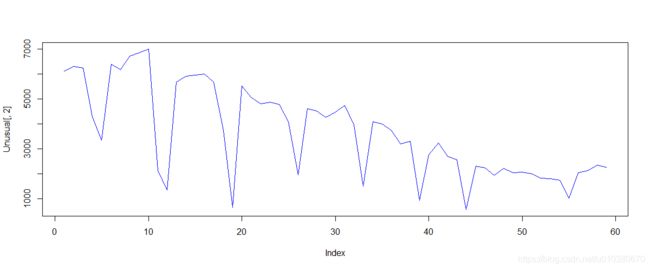
# 方法1:基础绘图
plot(Unusual[, 2], type = "l", col = "blue") # 设置主标题,x,y轴标题
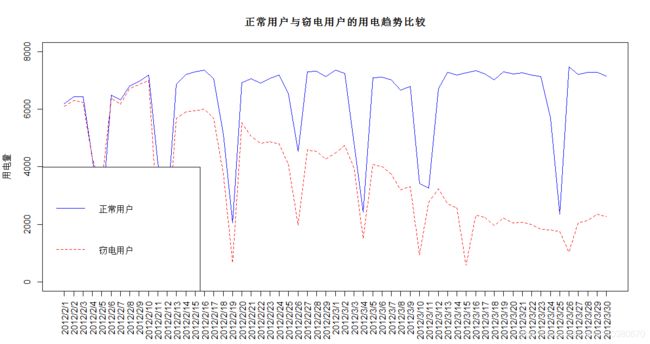
# 方法2:在一张图上对比
plot(Regular[,2], col = "blue", lty = 1, type = "l",
main = "正常用户与窃电用户的用电趋势比较", ylim = c(0,8000),
ylab = "用电量", xlab = "", xaxt = "n") # axes = F
axis(1, at = 1:59, Regular[, 1], las = 2) # 设置x轴
lines(Unusual[,2], col = "red", lty = 2, type = "l") # 添加窃电数据
legend("bottomleft", legend = c("正常用户","窃电用户"),
lty = 1:2, col = c("blue", "red")) # 添加图例
# ---------------------------------求斜率--------------------------------------
# 读取数据
Power <- read.csv("用户日用电量.csv")
# 设置一个向量k存放求出的每天的斜率值
k <- rep(0, nrow(Power))
Down <- Power$日电量
for (i in 1:nrow(Power)) { # 循环所有天,求出每天的前后5天共计11天的平均斜率k
if (i <= 5) {
l <- 1:(i + 5) # 前面不足5天时求平均斜率用到的天数
}
if (i >5 & i < (nrow(Power) - 5)) {
l <- (i - 5):(i + 5) # 前后均满足5天时的求平均斜率用到的天数
}
if (i >= (nrow(Power) - 5)) {
l <- (i-5):nrow(Power) # 后面不足5天时求平均斜率用到的天数
}
k[i] <- cov(Down[l], l) / var(l) # 计算第i天的斜率,公式类似求协方差除方差
}
# -----------------------------标记用电量趋势----------------------------------
Decrease <- rep(0, nrow(Power)) # 设置变量D,用于存放电量趋势标记1或0
for (i in 2:nrow(Power)) { # 从第二天开始循环,求出所有天的电量趋势标记
if (k[i] < k[i - 1]) {
Decrease[i] <- 1 # 当天比前一天斜率低,标记为1
}
if (k[i] >= k[i - 1]) {
Decrease[i] <- 0 # 当天高于或等于前一天斜率,标记为0
}
}
# --------------------------统计11天内的趋势下降次数---------------------------
Total <- rep(0, nrow(Power)) #设置变量T,存放对第i天前4后5共计10天的电量趋势汇总值
for (i in 1:nrow(Power)) { # 循环所有天,求出每天前4后5共计10天的趋势汇总
if (i < 5) {
m <- 1:(i + 5) # 前面不足5天要汇总的天数
}
if (i >= 5 & i <= nrow(Power) - 5) {
m <- (i - 4):(i + 5) # 满足前后5天时研汇总的天数
}
if (i > nrow(Power) - 5) {
m <- (i - 4):nrow(Power) # 后面不足5天时用到的天数
}
Total[i] <- sum(Decrease[m])
}
# 读取数据
data_alarm <- read.csv("告警.csv")
data <- read.csv("用户.csv")
# 构造ID&date属性
data_alarm$ID_date <- paste(data_alarm[, 1], data_alarm[, 2])
data$ID_date <- paste(data[, 1], data[, 2])
# 统计用户每天的告警次数
D <- data.frame(matrix(0, nrow(data), nrow(data_alarm)))
for (i in (1:nrow(data))) {
for (k in (1:nrow(data_alarm))) {
if (data$ID_date[i] == data_alarm$ID_date[k]) {
D[i, k] <- 1
} else {
D[i, k] <- 0}
}
}
D$sum <- apply(D, 1, sum) # 按行计算总和
data$alarm_ind <- D$sum
data <- data[, c(1, 2, 6)] # 去除不需要的ID,日期和告警次数
library(XLConnect)
missing_data <- XLConnect::readWorksheetFromFile(file = "missing_data.xls",
sheet = 1, header = FALSE)
lagrange <- function(x, xi, yi) {
n <- length(xi)
lage <- 0
for (i in 1:n) {
li <- 1
for (j in 1:n) {
if (i != j) {
li <- li * (x - xi[j]) / (xi[i] - xi[j])
}
}
lage <- li * yi[i] + lage
}
return(lage)
}
missdata <- missing_data
for (k in 1:3) {
x <- which(is.na(missing_data[, k]))
x1 <- c(0, x)
x2 <- c(x, nrow(missing_data))
x12 <- x2 - x1 - 1
xx1 <- x12[1:(length(x12) - 1)] # 缺失值前面的行数
xx2 <- x12[2:(length(x12))] # 缺失值后面的行数
j <- 1
for (m in x) {
if (xx1[j] >= 5) { # 空值前的判断
xi <- (m - 5):(m - 1)
} else {
xi <- (m - xx1[j]):(m - 1)
}
if (xx2[j] >= 5) { # 空值后的判断
xi <- c(xi, (m + 1):(m + 5))
} else {
xi <- c(xi, (m + 1):(m + xx2[j]))
}
yi <- missing_data[xi, k]
missdata[m, k] <- lagrange(m, xi, yi)
print(c(m, missdata[m, k]))
j <- j + 1
}
}
# 读取数据
data_loss <- read.csv("线损.csv")
# 构造线损
data_loss$日线损率 <- (data_loss[, 3] - data_loss[, 4]) / data_loss[, 3]
# 便于代码调用,将日线损率数据赋予变量v
V <- data_loss$日线损率
# Vb为当天与后5天共6天的线损率平均值
# Vf为当天与前5天共6天的线损率平均值
n <- nrow(data_loss)
Vb <- rep(0, n)
Vf <- rep(0, n)
E <- rep(0, n) # 设置变量E,存放线损指标
for (i in 1:n) { # 循环所有天,求出每天的线损指标
if (i <= 5) { # 前面不足5天的情况
Vb[i] <- mean(V[i:(i + 5)])
Vf[i] <- mean(V[1:i])
}
if (i > 5 & i < n - 5) { # 前后均满足5天的情况
Vb[i] <- mean(V[i:(i + 5)])
Vf[i] <- mean(V[(i - 5):i])
}
if (i >= n - 5) { # 后面不足5天的情况
Vb[i] <- mean(V[i:n])
Vf[i] <- mean(V[(i - 5):i])
}
if ((Vb[i] - Vf[i]) / Vf[i] > 0.01) {
E[i] <- 1 # Vb比Vf的增长率判断,并标记
}
if ((Vb[i]-Vf[i]) / Vf[i] <= 0.01) {
E[i] <- 0
}
}