Scrapy 爬虫完整案例-进阶篇
转自作者:听海8 -点击可查看原文
1.1 进阶篇案例一
案例:爬取豆瓣电影 top250( movie.douban.com/top250 )的电影数据,并保存在 MongoDB 中。

案例步骤:
第一步:明确爬虫需要爬取的内容。
我们做爬虫的时候,需要明确需要爬取的内容,豆瓣电影 TOP 250,我们需要抓取每一部电影的名字,电影的描述信息(包括导演、主演、电影类型等等),电影的评分,以及电影中最经典或者脍炙人口的一句话。
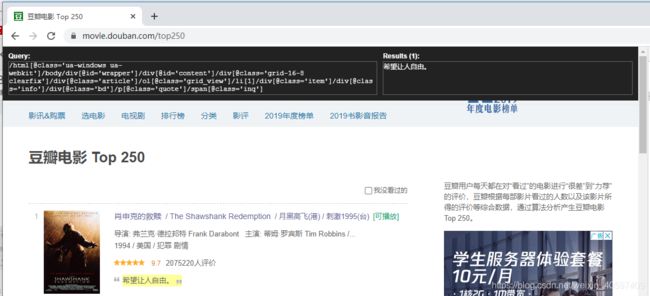
例如:肖申克的救赎

电影的名字:肖申克的救赎。
电影信息(导演:弗兰克·德拉邦特;主演:蒂姆·罗宾斯 / 摩根·弗里曼 / 鲍勃·冈顿 / 威廉姆·赛德勒 / 克兰西·布朗 / 更多…;电影类型:剧情 / 犯罪。)
豆瓣电影评分:9.6。
脍炙人口的一句话:希望让人自由。
第二步:创建爬虫项目。
在 dos下切换到目录
D:\scrapyStudy
新建一个新的爬虫项目:scrapy startproject douban
第三步:创建爬虫。
在 dos下切换到目录。
D:\scrapyStudy\douban\douban\spiders
用命令 scrapy genspider doubanmovie “movie.douban.com” 创建爬虫。 第四步: 开始前的准备工作。
第四步: 开始前的准备工作。
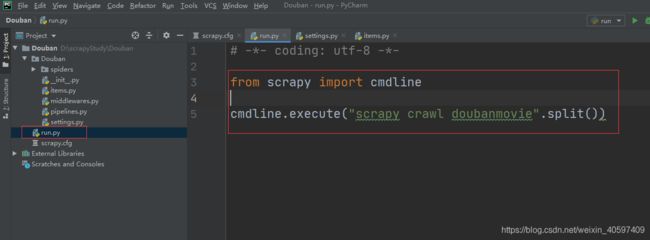
(一)、在 scrapy.cfg 同级目录下创建 pycharm 调试脚本 run.py,内容如下:
# -*- coding: utf-8 -*-
from scrapy import cmdline
cmdline.execute("scrapy crawl doubanmovie".split())
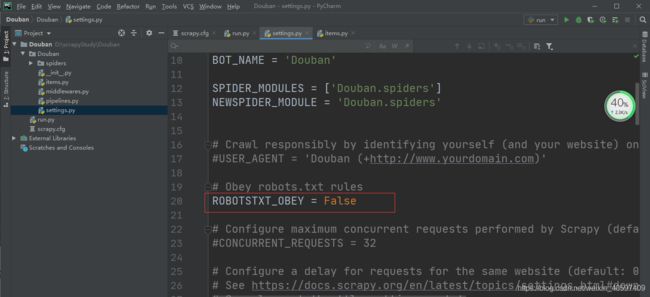
 (二)、修改 settings 中的 ROBOTSTXT_OBEY = True 参数为 False,因为默认为 True,就是要遵守 robots.txt 的规则, robots.txt 是遵循 Robot协议 的一个文件,它保存在网站的服务器中,它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望你进行爬取收录。在 Scrapy 启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。查看 robots.txt 可以直接网址后接 robots.txt 即可。
(二)、修改 settings 中的 ROBOTSTXT_OBEY = True 参数为 False,因为默认为 True,就是要遵守 robots.txt 的规则, robots.txt 是遵循 Robot协议 的一个文件,它保存在网站的服务器中,它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望你进行爬取收录。在 Scrapy 启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。查看 robots.txt 可以直接网址后接 robots.txt 即可。
例如百度:https://www.baidu.com/robots.txt
修改 settings 文件。
 (三)、settings.py 里添加 USER_AGENT。
(三)、settings.py 里添加 USER_AGENT。
 第五步: 定义 Item,编写 items.py 文件。
第五步: 定义 Item,编写 items.py 文件。
import scrapy
class DoubanItem(scrapy.Item):
# 电影标题
title = scrapy.Field()
# 电影信息
bd = scrapy.Field()
# 豆瓣评分
star = scrapy.Field()
# 脍炙人口的一句话
quote = scrapy.Field()

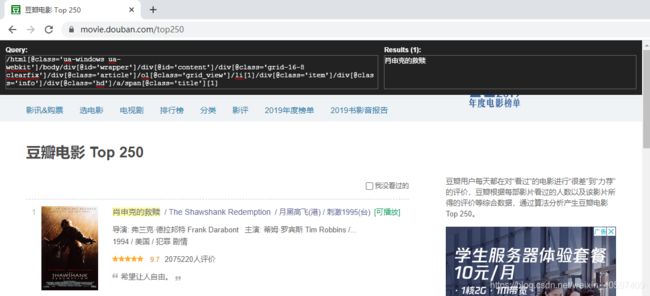
第六步: 查看HTML源码,使用XPath helper爬虫插件一起查看需要爬取的字段的 xpath 路径。
# 电影标题
item['title'] = each.xpath(".//span[@class='title'][1]/text()").extract()[0]

# 电影信息
item['bd'] = each.xpath(".//div[@class='bd']/p/text()").extract()[0]

# 豆瓣评分
item['star'] = each.xpath(".//div[@class='star']/span[@class='rating_num']/text()").extract()[0]

# 脍炙人口的一句话
quote = each.xpath(".//p[@class='quote']/span/text()").extract()
 备注:extract()返回的是一个列表,列表里的每个元素是一个对象,extract()把这些对象转换成 Unicode 字符串。
备注:extract()返回的是一个列表,列表里的每个元素是一个对象,extract()把这些对象转换成 Unicode 字符串。
第七步: 分析网站分页的 URL 规律。


第一页的链接地址:
https://movie.douban.com/top250?start=0
第二页的链接地址:
https://movie.douban.com/top250?start=25
最十页的链接地址:
https://movie.douban.com/top250?start=225
通过分析我们得知,每一页的的链接地址 start 的值递增 25,就是下一页的地址。
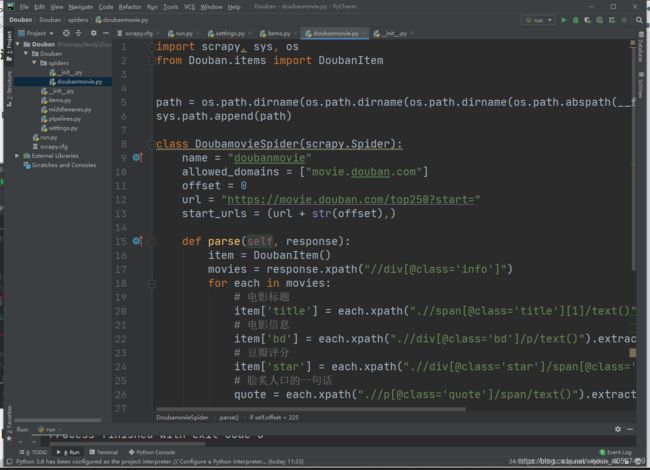
第八步: 编写爬虫文件。
import scrapy,sys,os
from douban.items import DoubanItem
path = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
sys.path.append(path)
class DoubamovieSpider(scrapy.Spider):
name = "doubanmovie"
allowed_domains = ["movie.douban.com"]
offset = 0
url = "https://movie.douban.com/top250?start="
start_urls = (url + str(offset),)
def parse(self, response):
item = DoubanItem()
movies = response.xpath("//div[@class='info']")
for each in movies:
# 电影标题
item['title'] = each.xpath(".//span[@class='title'][1]/text()").extract()[0]
# 电影信息
item['bd'] = each.xpath(".//div[@class='bd']/p/text()").extract()[0]
# 豆瓣评分
item['star'] = each.xpath(".//div[@class='star']/span[@class='rating_num']/text()").extract()[0]
# 脍炙人口的一句话
quote = each.xpath(".//p[@class='quote']/span/text()").extract()
if len(quote) != 0:
item['quote'] = quote[0]
yield item
if self.offset < 225:
self.offset += 25
yield scrapy.Request(self.url + str(self.offset), callback = self.parse)
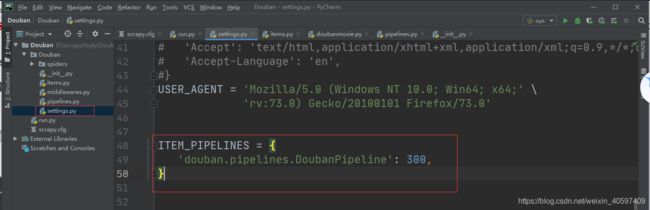
 第九步:在settings.py文件里设置管道文件。
第九步:在settings.py文件里设置管道文件。
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
 第十步:创建 MongoDB 数据库"Douban"和存放爬虫数据的表"doubanmovies"。
第十步:创建 MongoDB 数据库"Douban"和存放爬虫数据的表"doubanmovies"。
在MongoDB中创建一个叫"Douban"的库。