我们该用什么去存储数据?(mysql+hbase+es+时序数据库)
在2019年里,有幸跟着项目组接触到了hbase和es,更有幸的是我将这些技术应用到项目中,对这些技术也有了一些了解,结合之前用过的mysql和最近在学习的时序数据库,想聊聊关于存储的一些问题。
数据库技术的发展,大多数是针对于某个场景,优化了该场景需要的一些特性,牺牲了对于该场景不太需要的特性,从而在该场景发挥的更好(我自己瞎总结的)。
下面我会从大家最熟悉的mysql开始,逐渐引出现在很厉害的分布式数据库 es、hbase以及时序数据库的一些查询写入原理,揭开这些数据库的神秘面纱。
我们主要会从这几个方面聊一下:
-
mysql的瓶颈以及解决方案
-
hbase为什么写入比mysql快好几个量级?
-
为什么说es一切都为了搜索?
-
hbase和es的分布式都做得很厉害,它们分别是怎么做的,为什么这么做?
-
**
时序数据库为什么比较适合存储时序数据?**
1.mysql的瓶颈以及解决方案?
我们先来聊聊mysql吧。
这是一个很长很长的故事,在很久之前,我们的互联网还不是很发达,需要处理的数据量也不多,我们服务器上有很多关系型的数据需要存储起来(比如用户、角色、资源、 订单、支付等数据),并且需要提供灵活的结构化查询(包括多条件查询以及多表联查),这时候传统的关系型数据库就出现了,其中代表就是mysql。
为了更好的支撑业务,我们在这个数据库上做了很多功能,比如为了保证业务数据的ACID特性,我们增加了事务(通过共享锁和排他锁实现),为了更加快速的查询。我们增加了索引(通过B+树实现),为了更加快速的写入,我们采用了日志先行(WAL,先将数据写入到redo日志中,返回成功,再异步写到磁盘中(innodb))的策略,就这样,mysql可以很好的支持一般的应用系统。
后来我们发现,随着业务的发展,我们的单机mysql是有局限的。
第一个问题,如何保证数据库的高可用,万一数据库挂掉了我们怎么办?
主备,这是我们保证高可用的基本,好吧,我们在一个mysql(master)的基础上增加一台备用的mysql(slave),一般正常情况下,我们只有一个master进行工作,当这个master挂掉之后,我们需要将slave顶上去,继续进行工作。
那么slave怎么知道master挂掉了呢?我们还需要一个zookeeper这样的协调服务告知slave master的状态,或者说我们也可以通过slave去监控master,这样,master挂掉了slave也知道。
还有,既然slave要能顶替master,那么slave就要和master的数据保证一致,这样就不至于slave顶上去出岔子,那么我们就需要在数据更新的同时,数据通过binlog同步完slave之后才能返回成功(当然这样做的话牺牲了写入的性能(主从复制网络耗时),我们也可以在更新到master后就返回成功,再异步同步slave,但是这样的话也有个问题就是说在master挂掉之后,slave的数据不一定完整,只能选取数据最多的slave进代替master,这样可以提高写入性能,但是如果是要保证数据准确性的场景下,是不适合的。别担心,这些应该都是可以配置的)。
另外,为了减少master的压力,我们可以做读写分离,在slave上读取数据,在master上写入数据。
第二个问题,如果数据量大了,或者ops高了,我们如何做水平扩容(如何保证高扩展)?
首先,解决存储数据量的问题
随着数据量越来越大,我们的单库单表产生了瓶颈,单表产生瓶颈是因为我们的数据量大了,查找一条数据需要扫描的条数越来越多,导致查询越来越慢,超过了用户等待的极限时间或者数据库连接的极限时间,单库产生瓶颈是因为数据量大小达到了我们的操作系统的文件系统ext2 ext3的存储容量极限(当然在现在微服务化和单元化的潮流中,由于一个微服务对应一个数据库,分库的需求实际在慢慢的变少)。这时候,我们采用了惯用的伎俩–拆分。
先说分表吧,分表有两种,垂直分和水平分。
垂直分就是将一些占用空间比较大的字段分出去来保证主表的查询效率,这样的缺点就是有可能有些业务需要join联查才能查询出来。
水平分就是将数据行通过一定的规则分开,每个表里存储着部分数据。
水平分的最大的难点就是拆分规则,拆分规则是要根据业务来的,一般拆分规则有hash、顺序、路由表等等(这三种规则详见最后的附1),根据不同的业务选用不同的规则很重要。
再说说分库吧,大概就是说,将两个关系不大的业务分到两个库中,减少单库的数据量。问题也是有的:
如果这两个业务存在某些关联,那我们不能join联查,只能在应用侧查询两次,自己进行聚合,比较复杂。
如果这两个业务需要使用到同一个事务,那我们只能引入其他组件去解决分布式事务的问题,这也是一个很复杂的事情。
总之,分库分表都会对业务产生一定的限制,并且需要应用测配置很多东西,比较复杂。
再来简单说说ops(每秒可以处理的操作数)的极限问题吧,如果读写需要的频率很高,我们的单机往往是承受不了的,如果说读的频率很高,那我们可以增加很多slave来解决(通过读写分离,可能会影响写入效率),如果说写的频率很高,我们也可以采用MMM架构,利用多个master进行接收数据,并进行相互的复制(但是不能无限制增加,相互复制也相当的消耗资源)。
上面说的这些其实也说明了一个问题,就是大多数问题,我们的mysql都是可以解决的,只是复杂度比较高,性能不理想而已,在很多系统中,我们只用mysql就可以做到所有的事(mysql后来甚至支持了全文搜索)。
虽然说mysql很厉害,它可以做几乎所有的事情,但是它的缺陷也是很明显的,分布式的复杂度太高了,并且在兼顾了写入和查询性能后,写入和查询的性能反倒是没有那么优秀了。
我们发现很多情况下,其实不用兼顾写入和查询,比如有些业务数据,写入100w次才会查询一次,或者有些业务数据,写入100条数据,就会查询100w次,我们是不是可以根据特定的场景,牺牲查询的性能,极致化写入性能,或者牺牲写入性能,极致化查询性能?在这条路上,我们探究了很久,最终广为人知的hbase和es就诞生了,当然这些后来的技术在吸取了前人的经验之后,在分布式水平扩容方面都做的很优秀。
2.hbase为什么写入比mysql快好几个量级?
我们说说hbase吧。看看它是怎么牺牲查询性能,极致化写入性能的。
首先如果不考虑查询灵活性或者联合查询的话,我们其实就不需要考虑结构化数据,不考虑结构化数据我们就不需要使用行式存储(空字段太浪费空间了),我们可以选用文档型存储,或者列式存储,其中,hbase采用了列式存储(好处:如果字段比较多,只查询相关的少部分字段,性能比文档型存储要高很多;相同列采用相同的数据类型,压缩率比较高);
第二点,如果要极致化插入的话,我们就不能维护索引,这就决定了hbase只支持一些简单的查询,不支持二级索引。
第三点,要更加极致的话,那就要所有数据都进行顺序追加,不进行更新、删除和随机插入。这样的话,操作的复杂度就是O(1)。
那问题就来了,如果不进行随机插入的话,那数据怎么排序(如果有查询范围数据的需求那存储的数据一定是要有序的)?如果不进行更新删除的话,那我有相关的需求怎么办?
我们先看看hbase怎么做的吧。
hbase采用了LSM树(简单来说就是,内存中局部乱序,异步排序数据并刷磁盘):
LSM树:将对数据的修改增量保存在内存中,达到指定大小限制之后批量把数据flush到磁盘中,磁盘中树定期可以做merge操作,合并成一棵大树,以优化读性能。不过读取的时候稍微麻烦一些,读取时看这些数据是否在内存中,如果未能命中内存,则需要访问较多的磁盘文件。极端的说,基于LSM树实现的hbase写性能比mysql高了一个数量级,读性能却低了一个数量级。
上面也许说的比较官方,也看不太懂,我们在结合hbase的存储结构应该就容易理解多了,下图展示了hbase的LSM树
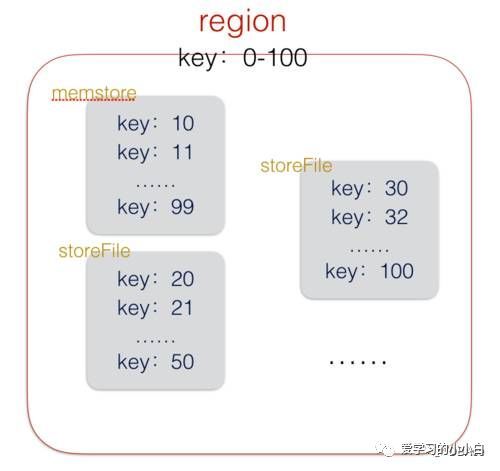
上图粗略的展示了HBase的region(相当于一个数据库)的结构,region不单单是一个文件,它是由一个memstore和多个storeFile组成(storeFile上的上限可以配置)。插入数据时首先将数据写入memstore(顺序写入内存),当memstore大小达到一定阈值,将memstore flush到硬盘,变成一个新的storeFile。flush的时候会对memstore中的数据进行排序,压缩(会对删除操作进行执行,更新操作增加版本号)等操作。可以看到单个storeFile中的数据是有序的,但是region中的storeFile间的数据不是全局有序的。
举个例子吧:
mem: 插入1 插入6 插入5 --> store:存储 1 5 6
mem: 插入4 插入2 删除5 删除2 --> store:存储 4 删除5
store+store–>Hfile:存储 1 4 6
这样的好处就是:不管主键是否连续,所有的插入一律变成顺序写,大大提高了写入性能。但是查询呢?
假如我现在要查询一个数据5,我们先去memstore中查询,我们需要将memstore中所有5相关的操作数据(删除更新)都拿出来进行聚合,如果在memstore中没有查到,我们在storeFile中查询,由于我并不知道要查询的这些数据在哪个storeFile里面,所以,必须将所有的storeFile都拿出来查询聚合。(当然,后续如果storeFile多了,还会有一次合并操作,将storeFile合并成一个大的HFile,也会进行所有storeFile的排序压缩),这样的查询操作还是很费精力的。
所以HBase的拥有很好的写入性能,但是读性能较差。
hbase也使用WAL策略,先将数据写到HLog和内存中就返回成功。
3.为什么说es一切都为了搜索?
我们再说说es吧。
之前我看过一句话:“es一切为了搜索”,后来深入研究了一下,才慢慢的理解这里面的深层含义。
我们这里不去讨论Lucene(es的底层搜索引擎)的全文搜索怎么怎么牛逼,也不去讨论es的分析聚合功能有多么多么的强大,我们这里主要探索一下,为什么es查询可以那么快?
查询要快,那就需要索引,es为每个字段默认都增加了索引(当然我们为了性能可以将一些不会当做条件查询的字段指定为text类型,这样es就不会为这些字段建立索引了)
都有索引,为什么es要比mysql快?我们都知道,b+树最耗时的就是缺页从磁盘进行多次IO加载(内存装不下),那么怎么能让查询一条数据的时候访问磁盘的次数减少呢?
有个做法就是,我们将之前mysql的一个字段的大索引分成若干个索引,然后通过一个内存中的一个单独索引(term index)帮助我们快速定位到我们要查找的数据是在哪个索引中,再在对应的索引(Term dictionary)中进行查找,这样需要查找的索引就小了,查找的速度就快了(在内存中几乎不耗费时间)。
那什么样的单独索引的大小能够存储在内存?这里我们就用到了另一个数据结构-字典树了(如下图所示)。

这个数据结构有点像我们的字典,他会指定类似这样的数据:
A开头的term索引 ------ 1索引
ca-cf开头的term索引 — 2索引
cg-d开头的term索引 — 3索引
和其他索引的对应关系类似下面这种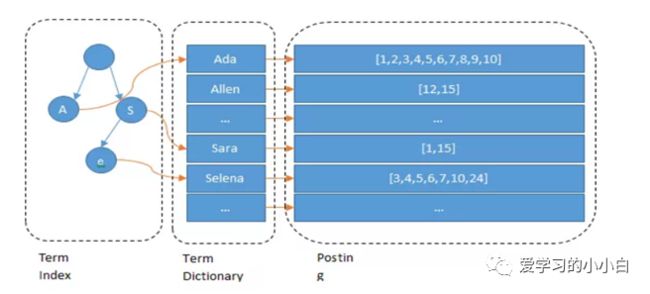 字典树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
字典树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
为什么字典树可以存储在内存中?
term index在内存中是以FST(finite state transducers)的形式保存的,其特点是非常节省内存。
再者,Term dictionary在磁盘上是以分block的方式保存的,一个block内部利用公共前缀压缩,比如都是Ab开头的单词就可以把Ab省去。这样term dictionary也可以更节约磁盘空间,查询也就更快了。
也许有人问,字典树那么小,为什么不都使用字典树?
字典树不像是b树一样可以自我平衡,很有可能造成一只腿的坡子,会影响查询。
mysql为什么不使用字典树?
如果用了字典树,插入的时候,之前维护一个索引,现在变成维护两个索引,当然写入性能慢了…这也就牺牲了写入性能,提高了查询性能。
这就是es的做法,利用双重索引加快查询。
其实在深入es的过程中,还发现了es的一些很聪明的地方,比如使用增量编码压缩的方式对posting list进行存储,大家有兴趣可以去查查看看。
4.hbase和es的分布式都做得很厉害,它们分别是怎么做的,为什么这么做?
说完hbase和es后,在这里我还想聊聊分布式,因为es和hbase都是分布式技术的佼佼者,这也是在大数据场景下将mysql甩好几条街的原因。
在我看来,分布式最重要的就是各个节点的协调工作,而hbase和es正好代表了分布式协调的两种方式,一种是内部自我通信协调,一种是通过外部的三方协调服务进行协调。
首先既然是分布式,那cap肯定要看一下的,现在大多数的分布式系统都保留AP,也就是说,要高可用,那要保证高可用的话,首先得有备份,并且master挂掉了备份要及时顶替。再者,既然是分布式,那肯定要随便扩展,那么数据就得动态的分布到多个节点上。
我们先看看hbase的分布式架构吧。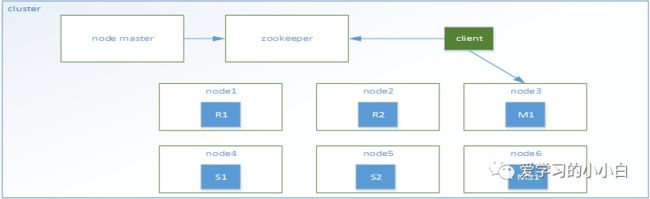
有n个主节点(R1,R2,R3)存储数据,每个主节点都有从节点(s1,s2,s3),数据的存储信息(路由信息)保存在一个meta(node master)节点上,通过zk可以找到这个meta节点,通过mate节点就可以找到数据在哪个节点上。
同时通过zk保证各个region的高可用(master-slave选举)
查找数据流程:client通过zookeeper找到meta节点,在mate表中获取数据所在的region信息,连接对应的region,查找数据。
es的分布式架构相对来说更简单一些:

每个索引(相当于mysql中的表)对应多个主分片(P);每个主分片对应多个从分片(R);主分片和从分片均匀分布在多个服务节点上(主从分片不在同一个节点),从节点监控着主节点,主节点挂了从节点顶上。
查找数据流程:
1.client访问任一节点(假设node1),该节点维护了所有节点以及对应的索引分片信息。
2.接收到请求的节点(node1)找到该索引对应的多个分片(主或者从分片,比如P0,R1,P2),将请求分发到分片对应的节点上(node1,node3)。
3.每个节点执行请求,然后将结果返回给最初的节点(node1),这个节点做完整理排序等操作后最终返回。
那么,问题来了,上面的哪个分布式结构更有优势呢?
分布式系统首先要解决的是通信调度问题,一种方案是通过自身保存集群中所有节点的信息去调度,一种是通过zk等中心去调度。前者广播消息gossip具有一定的开销,并且Failover 节点的检测过慢,并且每个节点要把所有服务器的信息都保存一份;后者部署架构复杂度高。
第一种方式其实有一点小缺陷的,如果更加严谨一点,我们要保证调度中心zookeeper的高可用怎么办?如果在zookeeper使用了三方调度保证高可用,那这个三方的高可用怎么保证?所以,分布式最终的通信还是要使用第一种集群内部自我通信的方式(一般zk的集群都是通过集群内部进行通信来保证高可用的)。
hbase分布式那样做主要是因为zookeeper挂掉一段短时间对系统没有太大影响(client通过zk找到mate节点,会把mate节点的数据缓存一份,可以直接访问其他region)。
5.时序数据库为什么比较适合存储时序数据?
(这块是我在学习时序数据库之初写的,所以有些东西理解的比较片面,不建议深读,浅谈时序数据库 这篇文章是后期写的,自己的理解会更准确一些,建议深读)
好了,hbase和es差不多说完了,查询快的有了,写入快的有了,查询写入折中的也有了,那时序数据库是什么呢?
首先,听这个名字,那就一定是专门存储时序数据的。
那么,什么是时序数据呢?
按时间维度索引的数据,为时序数据。
既然是专门存储时序数据的,那一定根据时序数据的特点优化了很多东西,那首先,我们要知道时序数据的特点。
时序数据特点(联想车辆轨迹数据):
1.数据特点:数据量大,数据随着时间增长,相同维度重复取值,指标平滑变化(某辆车的某个设备上传上来平滑变化的轨迹坐标)。
2.写入特点:高并发写入,且不会更新(轨迹不会更新)。
3.查询特点:按不同维度对指标进行统计分析,存在明显的冷热数据,一般只会查询近期数据(一般我们只会关心近期的轨迹数据)。
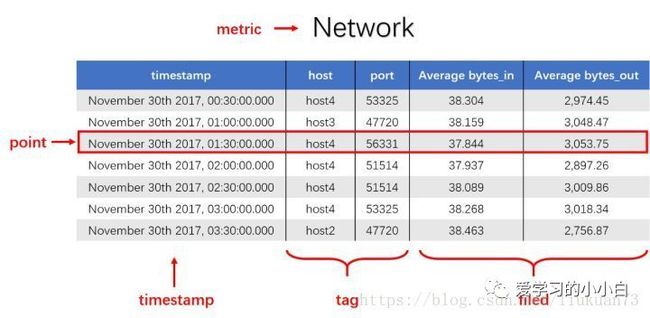
一般的时序数据都会有这几个属性(如下图(统计端口的出入流量)所示):
measurement:度量的数据集,类似于关系型数据库中的 table;
point:一个数据点,类似于关系型数据库中的 row;
timestamp:时间戳,表征采集到数据的时间点;
tag:维度列,代表数据的归属、属性,表明是哪个设备/模块产生的,一般不随着时间变化,供查询使用;
field:指标列,代表数据的测量值,随时间平滑波动,不需要查询。
所以,我们能做哪些改进?
首先第一个特点,数据量大,相同维度重复取值,我们可以将这些相同的维度压缩存储(因为是重复的),减少存储成本。
第二个特点,高并发写入,和hbase一样,我们可以采用LSM代替B树
第三个特点,聚合以及冷热数据,我们可以对于冷数据降低精度存储,也就是对历史数据做聚合,节省存储空间。
所以,一般时序数据库都有上述这几个功能。
并且时序数据库,设计一般也是天生的分布式,通过三方协调或者自身集群协调。
opentsdb就是基于hbase一个时序数据库,也说明了高并发写入才是时序数据库的重点,我还没有深入研究某个时序数据库,但是我认为我们应该先了解产品需求,然后再看具体的产品理解会更深刻一点(好吧,主要是因为我没有用到所以没研究那么细,以后会找个机会深究一下的)。
说到这里就结束了,文中有几张图我忘记从哪里引用的了,如果重复了,见谅…
谢谢大家,如有问题,欢迎探讨~
附件
附1:分表拆分规则
hash拆分就是说,根据某一个主要字段的hash值进行分表,比如根据车辆轨迹信息中的车牌号进行hash,通过hash值和表的数量取余,落在对应的表中,这样的缺陷就是如果想要查询某条数据,那么这个主要字段是必须指定的,否则就要所有的表都查询一遍,并且如果后续分的表不够用了,那么要是水平扩容的话,需要迁移的数据量那就很大了,是个很麻烦的工作。
顺序拆分是说,根据id或者时间顺序进行拆分,比如id为1-1000w的数据存放到1表中,1000w-1999w的数据存放到2表中,这样后续的数据不会影响前面的数据,扩展性比较好,但是问题也很明显,我们不能使用除id之外的其他条件进行查询,否则就要查询所有的表了(这个方式在一些子表中可以使用,拆分键为关联键id)。
路由表拆分的意思是,我们可以再维护一张表,维护着哪些范围的数据在哪个表中,这种方式比较复杂,需要新建一张表,并且需要维护它,没有特殊要求我们一般不使用(hbase用了类似的方式,因为hbase的id是全局有序的,并且需要动态分片)