用python爬取qq好友的头像并都下载到本地
正常步骤先上爬取效果图:
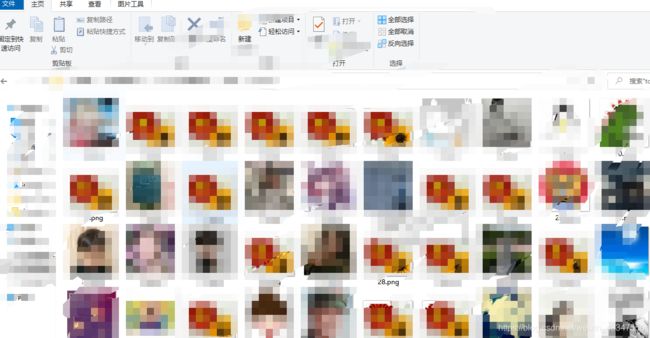
原理:从邮箱开始半自动爬取qq好友头像。
首先我们先打开网页版qq邮箱,并登陆上你的qq账户,通过qq邮箱来获取所有人的qq号。
接下来我用Google Chrome 浏览器来演示:
- 在qq邮箱网页界面 摁 F12 键 ,然后在弹出的界面 点击 Network 选项。
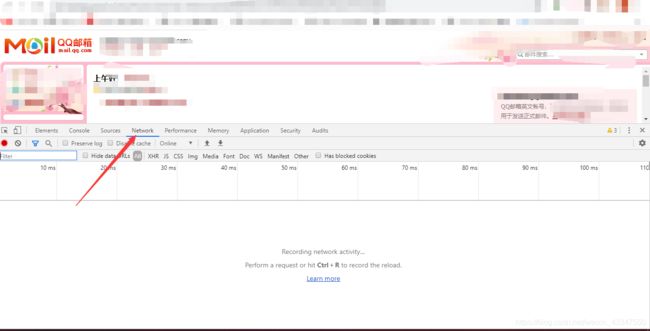
- 然后刷新一下网页,并在在红色箭头的地方输入laddr_lastlist
,然后回车
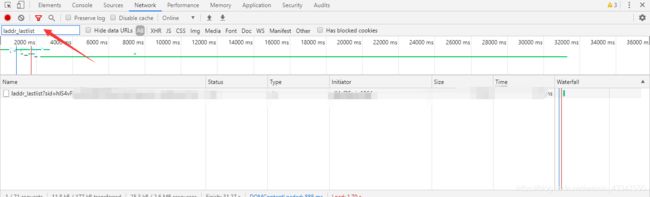
- 然后单击下面搜索到的选项,右边会弹出一个界面,然后单击Response(响应),然后下边就是我们所需要的内容,我也没有什么办法,毕竟是半自动的,所以,就需要Ctrl+c Ctrl+v,来将内容粘贴复制到一个txt文本上。
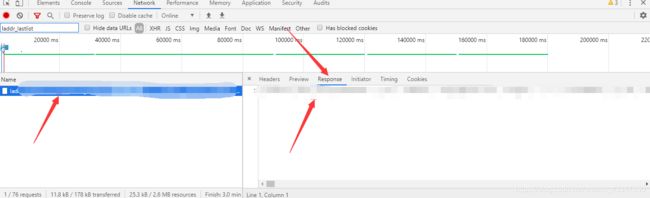
然后我们发现qq头像框保存在这么个地址上
http://qlogo.store.qq.com/qzone/88888888/88888888/100
即:
http://qlogo.store.qq.com/qzone/qq号/qq号/100
示例:
好了得到这些后,我们就开始码代码了。
直接上代码,基本上注释都给解释完了,这里我就不再过多介绍了。:
import re
import codecs
import time
import requests
txtpath = 'E:/大二下半学期资料/头像/qqfriends.txt' # 你从QQ邮箱中粘贴的txt文件
savepath = 'E:/大二下半学期资料/头像/touxiang/' # 头像存储位置
friends_count = 0 # 初始化好友数量
def gettouxiang(txtpath): # 输入你的txt文件存储位置
file = codecs.open(txtpath, 'rb', 'utf-8')
s = file.read()
pattern = re.compile(r'\[email protected]')
all_mail = pattern.findall(s) # 正则表达式匹配所有的qq号
all_link = [] # 用于存储需要访问的链接
url = 'http://qlogo.store.qq.com/qzone/'
for mail in all_mail:
qq = mail.replace('@qq.com', '')
l = url + qq + '/' + qq + '/100'
all_link.append(l)
i = 0 #初始化下载图片数量
friends_count = len(all_link) # 获取朋友头像数量
print('共{}个头像'.format(friends_count))
for link in all_link: # 遍历链接,下载头像
i += 1
saveurl = savepath + str(i) + '.png'
print('第 %d 个' % i, end=' ')
savaImg(link, saveurl)
return True
def savaImg(picurl, saveurl): # 存储图片函数,picurl是图片的URL,saveurl是本地存储位置
try:
start = time.time()
response = requests.get(picurl, stream=True)
with open(saveurl,'wb') as file: # 下载图片到本地
file.write(response.content)
print('【下载完成】:', end=' ')
end = time.time()
time_ = end-start
print('用时: %.2f秒' % (time_))
return True
except:
print('worry')
#savaImg(picurl, saveurl)
def main():
gettouxiang(txtpath) #获取头像
if __name__ == '__main__':
main()
运行实例: