电力窃漏电用户自动识别
电力窃漏电用户自动识别
1 数据预处理
1.1 数据清洗
主要目的是筛选出需要的数据,将多余的数据过滤
(1) 将初始数据进行分布可视化分析后发展非居民用电类别不存在漏电窃电的行为,故将这一部分数据过滤;
(2) 结合实际情况,节假日用电比工作日用电明显偏低,为了避免将其认为是漏电现象,将此部分数据过滤。
1.2 缺失值处理
经观察原始数据发展存在数据缺失现象,若将此部分数据删除则将放弃很多有价值的信息,甚至影响计算结果,故本案例采用拉格朗日插值法对缺失值进行差补。
此处赘述一下拉格朗日插值法:
首先从原始数据集中确定因变量和自变量,取出缺失值前后五个数据,根据取出来的10个数据组成一组,采用拉格朗日插值公式:
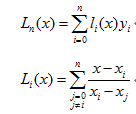
为缺失值对应的下标号,为缺失值的插值结果,为非缺失值的下标序号。对全部缺失数据进行插补。代码如下:
importpandas aspd
from scipy.interpolateimport lagrange
import warnings
inputfile=r'demo\data\missing_data.xls'
outputfile=r'demo\tmp\missing_data_processed.xls'
data=pd.read_excel(inputfile,header=None)
#自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s,n,k=5):
y=s[list(range(n-k,n))+list(range(n+1,n+1+k))]#取数
y=y[y.notnull()]#剔除空值
return lagrange(y.index,list(y))(n)
#逐个判断元素是否需要插值
for iin data.columns:
for jin range(len(data)):
if (data[i].isnull())[j]:
data[i][j]=ployinterp_column(data[i],j)
data.to_excel(outputfile,header=None,index=False)
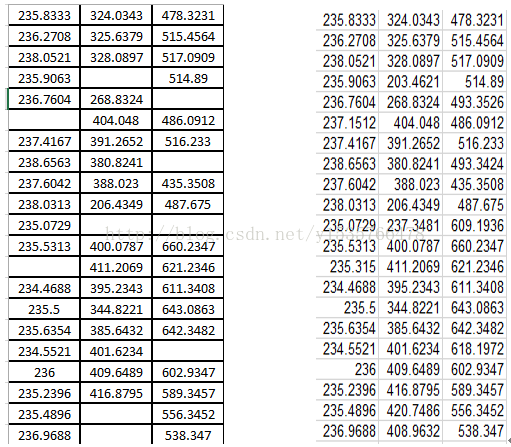
原始数据与处理后的数据如下:(用户数据)
2 模型构建
2.1 构建窃漏电用户识别模型
本案例主要使用神经网络模型和决策树模型,经过模型的训练对数据进行预测,来判断哪些是窃漏电行为
(1) 数据划分
将专家样本数据随机选取80%为训练样本,20%为测试样本,代码如下:
import pandas as pd from random import shuffle#引入随机函数,打散数据 datafile='model/data/model.xls' data =pd.read_excel(datafile) data=data.as_matrix()#将表格转化为矩阵 shuffle(data) p=0.8#设置训练数据比 train=data[:int(len(data)*p),:] test=data[int(len(data)*p):,:]
(2) 神经网络训练
#构建神经网络模型 from keras.models import Sequential from keras.layers.core import Dense,Activation#导入神经网络的层数和激活函数 netfile='demo/tmp/net.model'#神经网络模型的存储路径 net=Sequential() net.add(Dense(input_dim=3,output_dim=10)) net.add(Activation('relu'))#隐藏层使用的激活函数 net.add(Dense(input_dim=10,output_dim=1)) net.add(Activation('sigmoid'))#输出层使用的激活函数 net.compile(loss='binary_crossentropy',optimizer='adam') net.fit(train[:,:3],train[:,3],nb_epoch=1000,batch_size=1)#batch_size每次只训练一个样本在线学习 net.save_weights(netfile) predict_result=net.predict_classes(train[:,:3]).reshape(len(train))#给出预测并将其变形 def cm_plot(y, yp): from sklearn.metrics import confusion_matrix cm = confusion_matrix(y, yp) import matplotlib.pyplot as plt plt.matshow(cm, cmap=plt.cm.Greens) plt.colorbar() for x in range(len(cm)): for y in range(len(cm)): plt.annotate(cm[x, y], xy=(x, y), horizontalalignment='center', verticalalignment='center') plt.ylabel('True label') plt.xlabel('Predicted label') return plt cm_plot(train[:,3],predict_result).show()#显示混淆矩阵可视化结果
使用Keras库建立神经网络模型,输入层节点数为3,隐藏层节点数为10,输出层节点数为1,使用Adam方法求解,该模型中使用的激活函数能够大幅度提高模型的准确性,训练结果的混淆矩阵如下图:
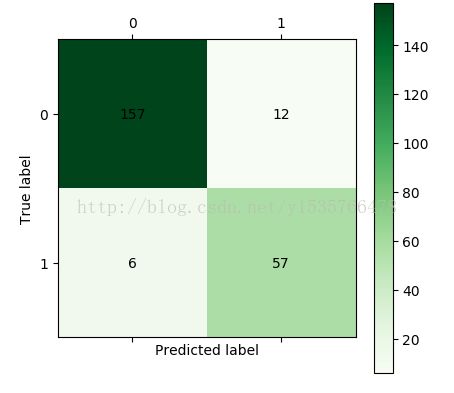
通过该混淆矩阵我们可得知:
分类的正确率为(157+57)/(157+12+6+57)=92.241%,可见模型的准确率已经很不错了,哈哈~~~(一些用户就比较倒霉了)正常用户被判为窃漏电用户的概率为7/(157+12)=4.1%,其实概率还是蛮高的~~~,窃漏电用户的概率被判为正常用户的概率为6/(6+57)=9.5%.这样看来模型还有待改进。此时该一些参数,模型的精确度就会有所提高,将训练集增加为85%,但是训练集的占比不能太高,否则会产生过拟合现象。
(3) CART决策树
除了用神经网络预测外还可以使用CART决策树模型进行预测判断。
代码如下:
#构建CART决策树模型 from sklearn.tree import DecisionTreeClassifier treefile=r'demo/tmp/tree.pkl' tree=DecisionTreeClassifier() tree.fit(train[:,:3],train[:,3]) from sklearn.externals import joblib joblib.dump(tree,treefile)#将模型保存至硬盘 def cm_plot(y, yp): from sklearn.metrics import confusion_matrix cm = confusion_matrix(y, yp) import matplotlib.pyplot as plt plt.matshow(cm, cmap=plt.cm.Greens) plt.colorbar() for x in range(len(cm)): for y in range(len(cm)): plt.annotate(cm[x, y], xy=(x, y), horizontalalignment='center', verticalalignment='center') plt.ylabel('True label') plt.xlabel('Predicted label') return plt cm_plot(train[:,3],tree.predict(train[:,:3])).show()#显示混淆矩阵可视化结果
结果如图:
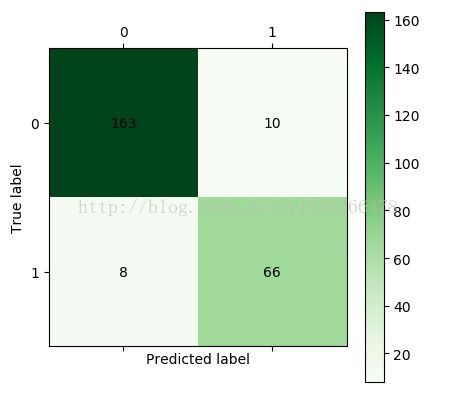
跟神经网络模型类似,经过计算之后发现两个模型的准确率差不多,此时我们该如何判断模型的好坏呢?接下来要进行模型的评价
2.2 模型的评价
对于模型的评价我们通常采用受试者工作特征曲线评价的方法进行评估,一个比较优秀的分类器所对应的ROC曲线应该是尽量靠左上角的,下面分别画出神经网络和决策树的受试者工作特征曲线,话不多说,直撸代码:
#绘制神经网络的ROC曲线 from sklearn.metrics import roc_curve import matplotlib.pyplot as plt predict_result=net.predict(test[:,:3]).reshape(len(test)) fpr,tpr,thresholds=roc_curve(test[:,3],predict_result,pos_label=1) plt.plot(fpr,tpr,linewidth=2,label='ROC of LM') plt.xlabel('False Postive Rate') plt.ylabel('True Postive Rate') plt.ylim(0,1.05) plt.xlim(0,1.05) plt.legend(loc=4) plt.show()
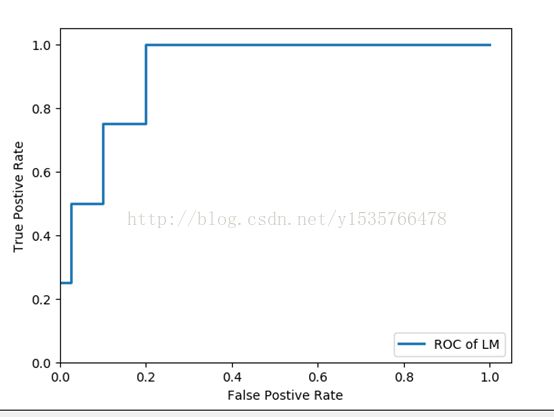
from sklearn.metrics import roc_curve import matplotlib.pyplot as plt fpr,tpr,thresholds=roc_curve(test[:,3],tree.predict_proba(test[:,:3])[:,1],pos_label=1) plt.plot(fpr,tpr,linewidth=2,label='ROC of CART') plt.xlabel('False Postive Rate') plt.ylabel('True Postive Rate') plt.ylim(0,1.05) plt.xlim(0,1.05) plt.legend(loc=4) plt.show()
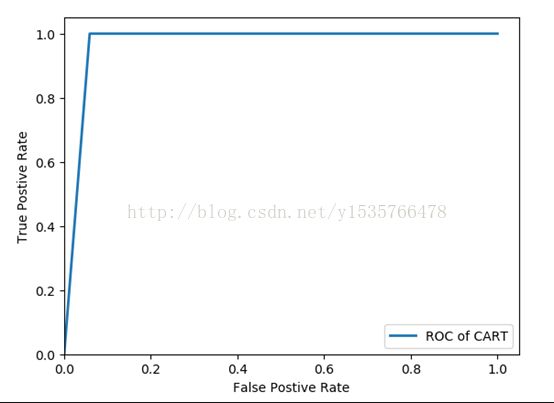
比较发现CART决策树模型ROC曲线比神经网络模型ROC曲线下的面积更大,说明CART决策树模型的分类性能较好,能用于窃漏电用户的识别。
备注:有的数据在帖子中没有显示,需要的可以留言~·