如何选择爬虫代理?
1. 什么是代理服务器?
- 摘自百度百科:https://baike.baidu.com/item/http%E4%BB%A3%E7%90%86/7689519?fr=aladdin
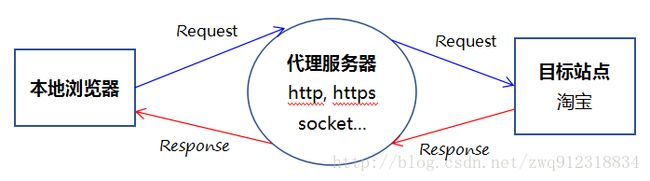
- 代理服务器英文全称是Proxy Server,其功能就是代理网络用户去取得网络信息。形象的说:它是网络信息的中转站。在一般情况下,我们使用网络浏览器直接去连接其他Internet站点取得网络信息时,须送出Request信号来得到回答,然后对方再把信息以bit方式传送回来。
- 代理服务器是介于浏览器和Web服务器之间的一台服务器,有了它之后,浏览器不是直接到Web服务器去取回网页而是向代理服务器发出请求,Request信号会先送到代理服务器,由代理服务器来取回浏览器所需要的信息并传送给你的浏览器。而且,大部分代理服务器都具有缓冲的功能,就好象一个大的Cache,它有很大的存储空间,它不断将新取得数据储存到它本机的存储器上,如果浏览器所请求的数据在它本机的存储器上已经存在而且是最新的,那么它就不重新从Web服务器取数据,而直接将存储器上的数据传送给用户的浏览器,这样就能显著提高浏览速度和效率。
- 更重要的是:Proxy Server(代理服务器)是Internet链路级网关所提供的一种重要的安全功能,它的工作主要在开放系统互联( OSI )模型的会话层。
- 主要的功能有:
- 1.突破自身IP访问限制,访问国外站点()。如:教育网、169网等网络用户可以通过代理访问国外网站。
- 2.访问一些单位或团体内部资源。如某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址段免费代理服务器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。
- 3.突破中国电信的IP封锁。中国电信用户有很多网站是被限制访问的,这种限制是人为的,不同Serve对地址的封锁是不同的。所以不能访问时可以换一个国外的代理服务器试试。
- 4.提高访问速度。通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度。
- 5.隐藏真实IP。上网者也可以通过这种方法隐藏自己的IP,免受攻击。
2. 代理的类型?
- 参考:http://www.360doc.com/content/13/1217/10/14919052_337800783.shtml
2.1. 按照协议分类
- 常用的代理类型有:ftp、http、https、socks、RTSP、POP3等代理类型。其中:
- HTTP代理和HTTPS代理: 能够代理客户机的HTTP访问,主要是代理浏览器访问网页,它的端口一般为80、8080、3128等。http访问http网站,https代理访问https网站:


- FTP代理: 能够代理客户机上的FTP软件访问FTP服务器,它的端口一般为21、2121。
- RTSP代理: 代理客户机上的Realplayer访问Real流媒体服务器的代理,其端口一般为554。
- POP3代理: 代理客户机上的邮件软件用POP3方式收发邮件,端口一般为110。使用方法参考文章:http://blog.csdn.net/zwq912318834/article/details/78014762
- SOCKS代理: SOCKS代理与其他类型的代理不同,它只是简单地传递数据包,而并不关心是何种应用协议,既可以是HTTP请求,也可以是HTTPS请求等,所以SOCKS代理服务器比其他类型的代理服务器速度要快得多。SOCKS代理又分为SOCKS4和SOCKS5,二者不同的是SOCKS4代理只支持TCP协议(即传输控制协议),而SOCKS5代理则既支持TCP协议又支持UDP协议(即用户数据包协议),还支持各种身份验证机制、服务器端域名解析等。SOCK4能做到的SOCKS5都可得到,但SOCKS5能够做到的SOCK4则不一定能做到,比如我们常用的聊天工具QQ在使用代理时就要求用SOCKS5代理,因为它需要使用UDP协议来传输数据。
- HTTP代理和HTTPS代理: 能够代理客户机的HTTP访问,主要是代理浏览器访问网页,它的端口一般为80、8080、3128等。http访问http网站,https代理访问https网站:
注意:代理必须( IP + Port + http/https(socks4/5) )协议,三个字段一起配合使用,不能只用( IP + Port )两个字段。2.2. 按照匿名度分类
- 从另一个角度来说,代理又可以分为三种,即高度匿名代理、普通匿名代理和透明代理。
- 高度匿名代理不改变客户机的请求,这样在服务器看来就像有个真正的客户浏览器在访问它,这时客户的真实IP是隐藏的,服务器端不会认为我们使用了代理。
- 普通匿名代理能隐藏客户机的真实IP,但会改编我们的请求信息,服务器端有可能会认为我们使用了代理(仅仅是可能而已,一般说来是没问题的),但其实这种代理的安全性可能比高度匿名代理更高,有的代理甚至会剥离客户机发送信息中的一部分,这样服务器端就根本探测不到我们所用的操作系统版本和浏览器版本。
- 第三种就是透明代理,它不但改编我们的请求信息,还会传送真实的IP地址。
2.3. 爬虫应该选择什么样的代理?
- 针对不需要用户登录,cookie验证的网站,一般选择动态高匿代理。
- 对于需要用户登录,身份认证的。一般选择静态IP
3. 代理资源从哪里来?
4. 购买的代理如何使用?
- 网上有很多方法告诉我们如何获取免费代理,但事实上免费代理的可用率非常低。如果是大型的爬虫项目,还是比较推荐使用收费的代理。而目前收费代理的提供方式一般是两种:
- 第一种:通过API链接的方式获取。
- 第二种:通过用户名,密码(隧道)+ 服务器地址,直接使用。
4.1. API接口模式
- 以讯代理为例:http://www.xdaili.cn/
- 使用定时器,每个一段时间就往List中填充相关的代理IP。其实从服务器拿到的动态高匿IP都是有时效性的,一般在1~3分钟不等。
- 嵌入在scrapy框架的middleware.py中
# 文件 middlewares.py
# -*- coding: utf-8 -*-
from scrapy import signals
import random
from myClawer.dictionary import useragent
import datetime
from scrapy import log
import threading
import requests
# 统计参数,用于分析代理IP的有效率
statisticProxyInfo = {
'getProxiesTime': 0, # 统计从API获取代理所花费的总时间,以秒为单位
'getProxiesSuccess': 0, # 统计从API获取代理成功的总次数
'getProxiesFail': 0, # 统计从API获取代理失败的总次数
'requestTotalCount': 0, # 统计总共发出了多少个url请求
'requestproxyCount': 0, # 统计使用代理的url请求总个数
'requestNoProxyCount': 0 # 统计不使用代理的url请求总个数
}
proxies_Lst = [] # 本地 IP 池
TIMERPER = 5 # 设置定时调用API连接获取代理的时间间隔 5s
proxies_repeat = {} # 用于记录重复IP的重复度
timerLst = [] # 用于存储定时器,用于获取代理
# 讯代理 http://www.xdaili.cn/
def getProxiesFromXunAPI():
global proxies_repeat
xunProxyLst = []
APIUrl = "http://www.xdaili.cn/ipagent//privateProxy/applyStaticProxy?spiderId=f16617004ca945d19ae3ff8aff0a6b97&returnType=2&count=11"
head = {"User-Agent": random.choice(useragent)}
try:
s = requests.session()
resp = s.get(url=APIUrl, headers=head)
statisticProxyInfo['getProxiesTime'] += 1
htmlJson = resp.json()
ERRORCODE = htmlJson['ERRORCODE']
RESULT = htmlJson['RESULT']
# print(f"\n###### getProxiesFromXunAPI Timer log start")
# print(htmlJson)
# print(f"######## getProxiesFromXunAPI Timer log end\n")
if (ERRORCODE == '0'):
statisticProxyInfo['getProxiesSuccess'] += 1
xunProxyLst.extend([f"{item['ip']}:{item['port']}" for item in RESULT])
# print(f"len:{len(xunProxyLst)}, xunProxyLst:{xunProxyLst}")
for item in xunProxyLst:
if item in proxies_repeat:
proxies_repeat[item] += 1
else:
proxies_repeat[item] = 1
return xunProxyLst
else:
statisticProxyInfo['getProxiesFail'] += 1
print(f"getProxiesFromXunAPI ERRORCODE:{ERRORCODE}")
return None
except Exception as e:
statisticProxyInfo['getProxiesFail'] += 1
print(f"getProxiesFromXunAPI exception:{e}")
return None
# 启动定时器:定时获取代理IP, 存在于爬虫的生命周期
def timerUpdateProxies():
from myClawer.pipelines import runTimer
global proxies_Lst
global timerLst
tmp_lst = getProxiesFromXunAPI() # 修改成想测试的那个代理
if tmp_lst:
proxies_Lst = tmp_lst[:]
if runTimer and not timerLst:
t = threading.Timer(TIMERPER, timerUpdateProxies)
t.start()
timerLst.append(t)
else:
# 爬虫结束,定时器停止
if runTimer == False:
for everyTimer in timerLst:
everyTimer.cancel()
print(f"Clawer is closed at time:{datetime.datetime.now()}, cancel all timer.")
# 添加 user-agent头
class HeadersMiddleware:
def process_request(self, request, spider):
# print('Using HeadersMiddleware!')
request.headers['User-Agent'] = random.choice(useragent)
# 添加 代理头
class ProxiesMiddleware(object):
def __init__(self):
runTime = datetime.datetime.now()
print(f"Instance ProxiesMiddleware, startProxyTimer at runTime:{runTime}.")
timerUpdateProxies()
def process_request(self, request, spider):
# print('Using ProxiesMiddleware!')
statisticProxyInfo['requestTotalCount'] += 1
# 在这里识别 request.url是不是指列表页,列表页不使用代理。
# 或者在发送列表页request时,将某个栏位(flags可用,类型是列表)置上标记,在这个地方检察这个标记,从而决定要不要启动代理。
# flags[0] 如果为1表示这条request并不需要添加代理
if request.flags and request.flags[0] == 1:
statisticProxyInfo['requestNoProxyCount'] += 1
print(f"No need proxy, requestTotalCount:{statisticProxyInfo['requestTotalCount']}, "
f"requestNoProxyCount:{statisticProxyInfo['requestNoProxyCount']}, url={request._get_url()}")
else:
if not request.meta.get('proxyFlag'):
if proxies_Lst:
proxy = random.choice(proxies_Lst)
statisticProxyInfo['requestproxyCount'] += 1
request.meta['proxy'] = proxy
print(f"Set proxy to: {proxy}, requestTotalCount:{statisticProxyInfo['requestTotalCount']}, "
f"requestproxyCount:{statisticProxyInfo['requestproxyCount']}")
else:
statisticProxyInfo['requestNoProxyCount'] += 1
print(f"Can't set proxy, proxies_Lst is empty.")
@staticmethod
def statisticProxyInfo():
# 在pipelines.py的close_spider中调用
global proxies_repeat
print(f"statisticProxyInfo as below:")
print(f"getProxiesTime:{statisticProxyInfo['getProxiesTime']}, \n"
f"getProxiesSuccess:{statisticProxyInfo['getProxiesSuccess']}, \n"
f"getProxiesFail:{statisticProxyInfo['getProxiesFail']}, \n"
f"requestTotalCount:{statisticProxyInfo['requestTotalCount']}, \n"
f"requestproxyCount:{statisticProxyInfo['requestproxyCount']}, \n"
f"requestNoProxyCount:{statisticProxyInfo['requestNoProxyCount']}, \n")
print(f"\nstatisticProxyRepeat as below:")
for key,value in proxies_repeat.items():
print(f"####ProxyLog100 proxy:{key} count:{value}")# 文件 pipelines.py
runTimer = True # 用来控制middlewares中的定时器
class MongoPipeline:
def open_spider(self, spider):
pass
def process_item(self, item, spider):
pass
def close_spider(self, spider):
global runTimer
runTimer = False # 爬虫结束,关闭定时器- 这种API模式有两个很大的弊端:
- 第一:实践发现,scrapy请求Request的方式是间歇性 + 批量模式。Request是一批一批发出去的。而这种IP的有效时间只有1~3分钟,Request首先加上代理头,然后等待调度,这段时间代理IP有可能会失效。
- 第二:本地代理池的储备目前是5个(根据套餐而定),如果一次加代理头的ur过多,算100个吧,那么100个url从5个IP中选择,那么平均下来,会有20 url选到同一个代理IP,重复率过高,会被反爬网站抓到。当然这个可以通过修改代理池的算法来实现。
- 上述弊端出现的原因主要是因为添加代理IP和正式将Request发出去请求网页之间存在一个时差。
4.2. 隧道模式
- 以阿布云为例:http://www.abuyun.com.cn/
# 文件 middlewares.py
# -*- coding: utf-8 -*-
from scrapy import signals
class ProxiesMiddleware:
def process_request(self, request, spider):
# print('Using ProxiesMiddleware!')
if not request.meta.get('proxyFlag'):
request.meta['proxy']='http://AFJK46J10HG8F89G:[email protected]:9020'- 有效解决上述API链接的弊端。
4.3. 固定IP模式
- 以讯代理为例,直接在代码中加上 IP:Port

- 适合对IP重复度不敏感的站点。
5. python使用单线程测试代理的成功率和平均时间。
5.1. 测试代码
# python 3.6.1
import time
import datetime
import functools
import requests
import random
import threading
# 定义配置信息
domains = ["www.amazon.com"] # 待测试的域名
ids_req = ["B018A2RRG4", "B002GCJOC0", "0071386211", "B00MHIKRIS",
"B00JRYV860", "B00JQUNC1E", "B06XXNMSQ2", "B00PVRHYDI",
"B01LVV0SW7", "B01LR8PG6Q", "B003DQSMGC", "B00853CKZC",
"B00IYOQOI6", "013418548X", "B017RZ45F6", "B00V27VX7E",
"B01I6RD5I2", "B000BYA52S", "B01MXBR9I6", "B073Y7BM3N",
"B01JRUU3P0", "B01N21UQHN", "B00394HMS2", "B001RCUNJ8",
"B006LXOJC0", "B06XSC2B4Z", "B01N6DC2ZE", "B01HI1W1V4",
"B0179JX8GC", "B00LZ5NA1U", "B004L5JCZ4", "B001B16VT6",
"B01NAJGGA2", "B06ZYX6Y1T", "B00PGJWYJ0", "B0179JX8GC",
"B01L9WSTEG", "B00LZS5EEI", "B01EFG8AHO", "B018YLFDY4",
"B00UY1YTGG", "B004B8AZH0", "B0194WDVHI", "B01K7OHDKS",
"B00339C3P0", "B06XBY86BR", "B00DFFT9SQ", "B06XVXRYTM",
"B003EM8008", "B00JRGOKQ8", "B00PDN097S", "B01GIVWTAI",
"B009OVU93E", "B017HME9AU", "B008AGQMQC", "B010S9N6OO",
"B0123MKO7G", "B01DDPUQTS", "B00NUS53CY", "B01I1430WQ",
"B00ECHYTBI", "B01EM9OHC6", "B0159TXEKY", "B071ZGBN2C",
"B00DDMITLO", "B01M0TJBA7", "B01M0FE59Y", "B01N0VNIA9",
"B018YLFDY4", "B010S5VXKC", "B01KV4FIOC", "B010S9N6OO",
"B009ZVL7N4", "B0194WDVHI", "B00LOXURO6", "B00SXRXUFE",
"B003UH9I2G", "B01NAJGGA2", "B06Y28Y4L7", "B0711V1B3S",
"B0187DR12G", "B011KPRE1G", "B013DG2FNW", "B00FZYT278",
"B073P7VWFK", "B010OYASRG", "B01K9S260E", "B01A6TW31S",
"B0046VGPHQ", "B01H3MTVE8", "B00DUJEWDE", "B01GDR3HHG",
"B005CWK0FG", "B0728GP9XH", "B00NJGAJNU", "B003YT6RNS",
"B073TQJQPL", "B00G7UY3EG", "B00MNV8E0C", "B017RCO1JY"] # 100个
useragent = [
'Mozilla/5.0 (compatible; Googlebot/2.1; http://www.google.com/bot.html)',
'Googlebot/2.1 ( http://www.googlebot.com/bot.html)',
'DoCoMo/2.0 N905i(c100;TB;W24H16) (compatible; Googlebot-Mobile/2.1; http://www.google.com/bot.html)',
'Mozilla/5.0 (iPhone; U; CPU iPhone OS) (compatible; Googlebot-Mobile/2.1; http://www.google.com/bot.html)',
'SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatible; Googlebot-Mobile/2.1)'
]
proxies_Lst = [] # 本地 IP 池
timerLst = [] # 存储定时器
runTimer = True
proxies_count = {} # 记录每个代理被使用的频率
# 装饰器
def timeDecorator(func):
'''
装饰器,记录函数的执行时间
:param func:
:return:
'''
@functools.wraps(func) # 方便调试,堆栈能显示真实的func name,而不是wrapper
def wrapper(*args, **kwargs):
startTime = datetime.datetime.now()
print(f"Enter func:{func.__name__} at {startTime}")
res = func(*args, **kwargs)
endTime = datetime.datetime.now()
print(f"Leave func:{func.__name__} at {endTime}, usedTime: {endTime-startTime}")
return res
return wrapper
# 讯代理
def getProxiesFromXunAPI():
xunProxyLst = []
APIUrl = "http://www.xdaili.cn/ipagent//privateProxy/applyStaticProxy?spiderId=f16617004ca945d19ae3ff8aff0a6b97&returnType=2&count=1"
head = {"User-Agent": random.choice(useragent)}
try:
s = requests.session()
resp = s.get(url=APIUrl, headers=head)
htmlJson = resp.json()
ERRORCODE = htmlJson['ERRORCODE']
RESULT = htmlJson['RESULT']
if (ERRORCODE == '0'):
xunProxyLst.extend([f"{item['ip']}:{item['port']}" for item in RESULT])
return xunProxyLst
else:
return None
except Exception as e:
print(f"getProxiesFromXunAPI exception:{e}")
return None
# 定时根据
def timerUpdateProxies():
global proxies_Lst
global timerLst
tmp_lst = getProxiesFromXunAPI()
if tmp_lst:
proxies_Lst = tmp_lst[:]
if runTimer and not timerLst:
t = threading.Timer(5, timerUpdateProxies)
t.start()
timerLst.append(t)
else:
# 测试结束,定时器停止
if runTimer == False:
for everyTimer in timerLst:
everyTimer.cancel()
print(f"Clawer is closed at time:{datetime.datetime.now()}, cancel all timer.")
# 统计代理IP的重复率
def statisticProxyCount(proxy):
if proxy in proxies_count:
proxies_count[proxy] += 1
else:
proxies_count[proxy] = 1
# 构造Url请求
def getUrlsFromIds(domain, ids_lst):
'''
构造url,amazon商品详情页url格式:www.amazon.com/dp/ANSI_ID
:param domain: domain of amazon
:param ids_lst: batch operator
:return:
'''
urls_lst = [f"http://{domain}/dp/{ID}" for ID in ids_lst]
return urls_lst
# 根据abuyun提供的隧道号,密钥,生成动态代理。 需要购买
def getProxyFromAbuyun(tunnel, secret):
# proxy = f'http://AFJK46J10HG8F89G:[email protected]:9020'
proxy = f'http://{tunnel}:{secret}@proxy.abuyun.com:9020'
return proxy
# 测量使用讯代理访问目标urls需要消耗的时间
@timeDecorator
def statisticSpeedOfProxy(urls):
'''
主要是统计使用代理时,访问成功,失败数,以及成功的情况下,访问每条url的平均时间
:param proxy: 使用的代理
:return: 详细的日志信息
'''
print(f"The result of use proxy to request url.\n")
header = {"User-Agent": random.choice(useragent)}
success_count = 0 # statusCode == 200
connectFail_count = 0 # statusCode != 200 or timeout
proxyFail_count = 0 # requests Exception
totalSuccessTime = 0
for url in urls:
tmpProxy = random.choice(proxies_Lst)
statisticProxyCount(tmpProxy)
proxies = {"http": tmpProxy,
"https": tmpProxy}
startTime = datetime.datetime.now()
try:
s = requests.session()
response = s.get(url=url, proxies=proxies, headers=header, timeout=30)
endTime = datetime.datetime.now()
usedTime = endTime - startTime
print(f"use proxy:{tmpProxy}, request url:{url}, statusCode:{response.status_code}, usedTime:{usedTime}")
if response.status_code == 200:
success_count += 1
totalSuccessTime += usedTime.total_seconds()
else:
connectFail_count += 1
except Exception as e:
proxyFail_count += 1
print(f"Exception: proxy:{tmpProxy}, url={url}, e:{e}")
# time.sleep(1) # 控制好时间间隔
avgTime = "100000"
if success_count != 0:
avgTime = totalSuccessTime / success_count
print(f"Statistic_proxy, total:{len(urls)}: success:{success_count}, "
f"totalSuccessTime:{totalSuccessTime}, avgTime:{avgTime}, "
f"connectFail_count:{connectFail_count}, proxyFail_count:{proxyFail_count}")
return ( len(urls), success_count, totalSuccessTime, avgTime, connectFail_count,
proxyFail_count)
# 测量不使用代理访问目标urls需要消耗的时间
@timeDecorator
def statisticSpeedWithoutProxy(urls):
'''
主要是统计不使用代理时,访问成功,失败数,以及成功的情况下,访问每条url的平均时间
尤其需要主要好时间间隔,以防网站反扒,IP被封
:param urls: 用来测试速度的url集合
:return: 详细的日志信息
'''
print(f"The result of not use proxy:\n")
header = {"User-Agent": random.choice(useragent)}
success_count = 0 # statusCode == 200
connectFail_count = 0 # statusCode != 200 or timeout
unknowFail_count = 0 # requests Exception
totalSuccessTime = 0
i = 0
for url in urls:
if i == 10: break # 本地网络抓取10个指标就好
i += 1
startTime = datetime.datetime.now()
try:
s = requests.session()
response = s.get(url=url, headers=header, timeout=30)
endTime = datetime.datetime.now()
usedTime = endTime - startTime
print(f"request url:{url}, statusCode:"
f"{response.status_code}, usedTime:{usedTime}")
if response.status_code == 200:
success_count += 1
totalSuccessTime += usedTime.total_seconds()
else:
connectFail_count += 1
except Exception as e:
unknowFail_count += 1
print(f"Exception: url={url}, e:{e}")
time.sleep(20) # 控制好时间间隔
avgTime = "100000"
if success_count != 0:
avgTime = totalSuccessTime / success_count
print(f"Statistic_No_proxy, total:{len(urls)}: "
f"success:{success_count}, totalSuccessTime:{totalSuccessTime}, "
f"avgTime:{avgTime}, connectFail_count:{connectFail_count}, proxyFail_count:{unknowFail_count}")
return ( len(urls), success_count, totalSuccessTime, avgTime, connectFail_count, unknowFail_count )
if __name__ == '__main__':
MainRunTime = datetime.datetime.now()
amazonDeatilUrls = getUrlsFromIds(domain=domains[0], ids_lst=ids_req)
amazonPageUrls = []
timerUpdateProxies()
# 测试使用讯代理爬取amazon商品详情网页的速度
print("\n##### The speed result of use xun proxy for amazon detail page. ")
res = statisticSpeedOfProxy(amazonDeatilUrls)
print(f"use_proxy Totalurls:{res[0]}, successCount:{res[1]}, totalSuccessTime:{res[2]}, "
f"avgTime:{res[3]}, connectFailCount:{res[4]}, proxyFailCount:{res[5]}\n")
# 测试不使用代理爬取amazon商品详情网页的速度
print("The speed result of not use proxy for amazon detail page. ")
res = statisticSpeedWithoutProxy(urls=amazonDeatilUrls)
# res: [len(urls), success_count, totalSuccessTime, avgTime, connectFail_count, proxyFail_count, detail_log]
print(f"No_proxy Totalurls:{res[0]}, successCount:{res[1]}, totalSuccessTime:{res[2]}, "
f"avgTime:{res[3]}, connectFailCount:{res[4]}, proxyFailCount:{res[5]}\n")
print("\n##### The statistic of proxy used. ")
for key,value in proxies_count.items():
print(f"proxy: {key}, count:{value}")
runTimer = False # 关闭定时器
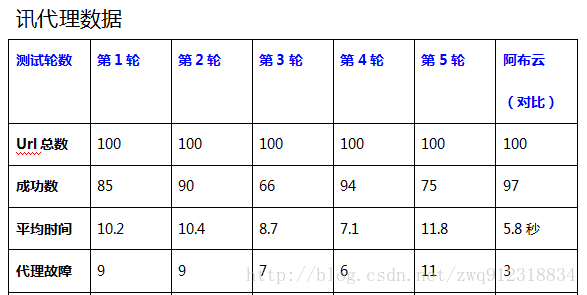
5.2. 测试结果对比
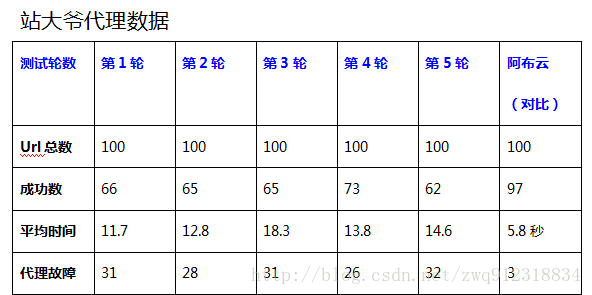
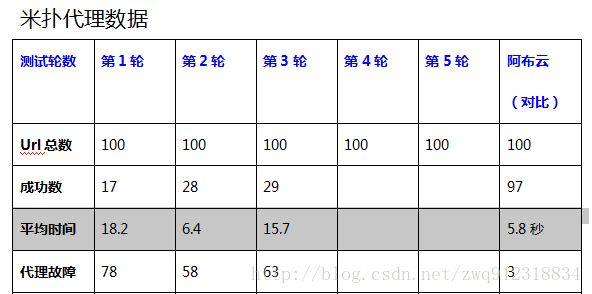
6. 代理使用注意事项。
- 代理必须 IP + Port + http/https(socks4/5)协议 三个字段一起配合使用,不能只用IP + Port两个字段。
- 使用的代理协议与访问网页协议是否一致,如http不能请求https网址,只能https抓取https网址。
- 设置的超时时间是否太短,推荐超时设置为20-30秒,太短了请求没完成就返回,导致失败。
- 爬取的网页是否有反爬取策略,是否设置了Headers的User-Agent、Cookie、Referer等。
- 提取的是否是最新检测可用的代理,提取过滤条件越少越好,提取后及时使用,注意代理的时效性,也就是存活时间。
- 您是否设置了重试次数,推荐设置重试4次,提高爬取的成功率。
为了提高代理提取和使用效率,推荐在您的本地数据库存储代理,并把您可用的代理标记为可用,这样您直接在您本地获取可用的代理进行使用;每次从API提取的代理如果可用,则更新到本地数据库里,这样日积月累本地的代理库的可用代理将会越来越多,可满足您的个性化需求,详细的设计方案如下(当然这个对代理IP的来源是有要求的,如果存活时间只有1-3分钟,这种策略无效…):
- 从API提取代理,爬取您的目标网页,可用则存入您的数据库,标记为1,成功次数也记为1
- 每次使用,直接从您的本地数据库里,提取标记为1的代理使用
- 爬取使用时,若成功则继续标记为1,并把成功次数加1;若失败则标记为0,成功次数不变
- 下次爬取时,优先提取标记为1的代理,其次提取成功次数大于1的代理,并按成功次数由多到少排序,重复步骤3
- 下次再爬取时,继续从API提取代理,重复步骤1、步骤3
- 上述设计的优点,既积累了大量可用代理,又可通过成功次数获取稳定代理IP,一举两得。
浏览器设置的代理为什么无法使用呢?
- 很多代理对浏览器的header信息(如User-Agent)有限制,导致无法直接通过浏览器设置代理进行访问,解决办法,可以通过firefox或chrome浏览器插件设置代理,参考https://blog.mimvp.com/article/21108.html,浏览器大都只支持http代理,不支持https和socks代理,并且http代理一般无法访问https网站,设置时需注意。不推荐通过浏览器设置代理访问(除非你已非常精通代理),强烈推荐编程使用代理。
7. 需要登录的网站下使用代理的注意事项
- 使用代理就是为了突破单个IP频率的限制,但是,在需要登录的网站上爬取,尤其需要注意。当登录之后,你的IP不断变化,或者说经常用不同的IP去登录网站,对于一些比较严格的网站来说,你的帐号很快就会被封掉了(尤其是国外的一些社交网站,涉及到个人隐私的,facebook等)。
- 正确的办法是,将一个IP对应一个账号,并发抓取(注意频率,间隔时间设置大一些)。
参考文章:
http://blog.csdn.net/ithomer/article/details/74034673
https://proxy.mimvp.com/question.php