新闻文本分类之旅 机器学习
天池-零基础入门NLP
- 新闻文本分类
- 导入相关库
- 读入数据
- 文本表示
- 训练模型
- 输出上传文件
- 存在问题
新闻文本分类
比赛地址
文本分类的任务是将给定的文本划分到事先规定的文本类别。
- 赛题难度:
- 匿名数据 + 长文本 + 类别不均衡。
- 解题思路:
- 思路1:TF-IDF提取特征 + SVM分类;
- 思路2:训练FastText词向量并分类;
- 思路3:训练Word2Vec词向量 + TextCNN模型分类;
- 思路4:训练Bert词向量并分类;
- 思路5:Bert分类 + 统计特征的树模型;
- 思路6:……
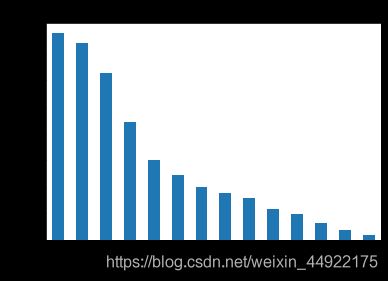
- 赛题中每个新闻包含的字符个数平均为1000个,还有一些新闻字符较长;
- 赛题中新闻类别分布不均衡,科技类新闻样本量接近4万,星座类新闻(13)样本量不到1千;
- 赛题总共包括7000-8000个字符。
导入相关库
import numpy as np
import pandas as pd
from sklearn.model_selection import KFold
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import LinearSVC # 可以使用其它机器学习模型
from sklearn.metrics import f1_score
读入数据
train_df = pd.read_csv('../data/train_set.csv', sep='\t')
test_df = pd.read_csv('../data/test_a.csv', sep='\t')
文本表示
向量空间模型
tfidf = TfidfVectorizer(
sublinear_tf=True,
strip_accents='unicode',
analyzer='word',
token_pattern=r'\w{1,}',
stop_words='english',
ngram_range=(1,3),
max_features=10000)
tfidf.fit(pd.concat([train_df['text'], test_df['text']]))
train_word_features = tfidf.transform(train_df['text'])
test_word_features = tfidf.transform(test_df['text'])
训练模型
k折交叉验证
LinearSVC模型
X_train = train_word_features
y_train = train_df['label']
X_test = test_word_features
KF = KFold(n_splits=5, random_state=7)
clf = LinearSVC()
# 存储测试集预测结果 行数:len(X_test) ,列数:1列
test_pred = np.zeros((X_test.shape[0], 1), int)
for KF_index, (train_index,valid_index) in enumerate(KF.split(X_train)):
print('第', KF_index+1, '折交叉验证开始...')
# 训练集划分
x_train_, x_valid_ = X_train[train_index], X_train[valid_index]
y_train_, y_valid_ = y_train[train_index], y_train[valid_index]
# 模型构建
clf.fit(x_train_, y_train_)
# 模型预测
val_pred = clf.predict(x_valid_)
print("LinearSVC准确率为:",f1_score(y_valid_, val_pred, average='macro'))
# 保存测试集预测结果
test_pred = np.column_stack((test_pred, clf.predict(X_test))) # 将矩阵按列合并
# 多数投票
preds = []
for i, test_list in enumerate(test_pred):
preds.append(np.argmax(np.bincount(test_list)))
preds = np.array(preds)
注 意 : \color{#FF7D00}{注意:} 注意:此处留出法和k折交叉验证效果相差无几。
输出上传文件
submission = pd.read_csv('../data/test_a_sample_submit.csv')
submission['label'] = preds
submission.to_csv('../output/LinearSVC_submission.csv', index=False)
存在问题
- 虽然n元语法能够体现邻接词组的关系,但是它难以捕捉句子中距离较远的词和词之间的关系。
- 每个新闻平均字符个数较多,可能需要截断。
- 由于类别不均衡,会严重影响模型的精度。