B站(哔哩哔哩)漫画爬虫实战
最近在B站漫画发现好多白嫖资源,但是只能在线看或者用手机app看,眼睛很累,所以想着怎么把资源传到kindle上,所以准备写个爬虫。
转自:http://hentaix.cn/B%E7%AB%99%E6%BC%AB%E7%94%BB%E7%88%AC%E8%99%AB%E5%AE%9E%E6%88%98/
源码:https://github.com/xuruoyu/bilibili_manga_downloader
0x01 背景
先访问链接https://manga.bilibili.com/mc25966/376715?from=manga_detail
先看看网站请求吧
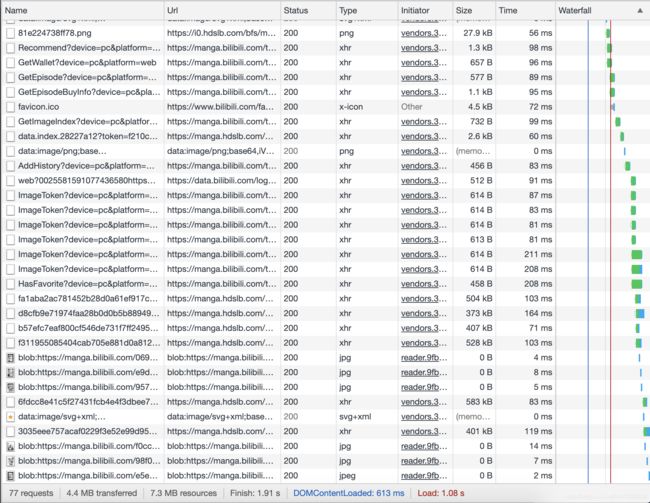
嗯,果然一堆请求,可以看出图片都是存放在cdn中的,但是每张图片都有token,如下图

这就简单了,只要能把图片是怎么请求的搞清楚就行了,嗯。。。果真这么简单么,果然我想多了。。。。
然后请求中包含一个data.index的请求,这个请求也是从cdn来的,目测这个文件就是包含所有图片的索引,来看看这个请求。

果然这个请求是个加密的文件。。。
0x02 加密的索引文件分析
我们用16进制文件查看器看看这个文件
这个文件看样子并不大,推测如果js要能够解析该数据的话,最终这个请求应该为json,或者文本(可能性不大,js处理起来太麻烦),但是从图片链接来看每张图片至少应该是个40 bytes的hash值,这个网页总共有60多张图片,那么应该大小为40*60>2400字节,但是这个请求只有1512字节,猜测是压缩过的
整理以下目前的猜测:
- 该请求最终目标为json,或者ascii文本,大概率是json。
- 这个请求应该是压缩过的,压缩算法未知。
从请求来看,目前只能获取到这些信息,那么开始分析代码吧~~~
0x03 初步窥探代码
webpack!!!哎。。。。还带了4层混淆,果然现在前端代码也不如从前容易分析了。
没办法,一点点解析吧~~~
果断先把代码dump下来,由于没有map文件,只能从混淆的代码中来分析了。
由于目标是如何解析那个data.index请求,那我们就从请求下手,看看能不能窥探到什么。
先全局搜一下字符串,看看能不能搜到data.index,嗯。。。果然啥也没有。。。
然后在看看请求,看来data.index文件也是通过请求获得的。

换个关键字再试试,GetImageIndex,看来有发现

从这个代码结构来看,应该是个post请求的promise对象,反向在搜索以下谁调用了这个代码,没办法,还是只能通过关键字getIndexFileUrl搜索一下

看来有新的发现,从这个对象名可以看出这应该是加载章节图片,其中有个调用引起了注意tn.decodeIndexFile,从文件名来看这个就应该是解码索引文件的函数了,从参数看应该传入了三个值作为输入:
- seasonId
- episodeId
- indexData
这几个参数中,episodeId容易理解即为章节id,seasonId应该也是个数值,data应该就是那个buffer
再尝试看看这个函数是怎么实现的,函数如下图:

果然webpack打包的代码真的恶心。。。
刚才猜测的有三个参数,这里派上了用场,Object(Jt.a)(t.seasonId, t.episodeId, o);应该就是解码索引文件的函数了,其中o应该就是那个buffer,从上面来看代码中强制转换为了Uint8Array,现在就要一层一层拨开webpack的封装了。。。
先看看那个Jt是啥,向上检索发现调用的是只一段
}(), Jt = a("J3ON"), Xt = a("vDqi"), Kt = a.n(Xt).a.create();
好嘛。。。又是这种,那再看看J3ON是啥,这次换了个js文件,跳转到了bili.xxxx.js

看到了一个"a",这就是刚才那个Object(Jt.a)调用的函数,从这里看应该是混淆到r了,在检索一下,看看这个r是啥玩意

有点意思了,看到上面有一数组定义var u = [66, 73, 76, 73, 67, 79, 77, 73, 67]刚好就是那个BILICOMIC的magic,看来这就是解码函数了,然后再看看下面的代码,一堆位操作符,一定是这里了~~~先把代码粘出来
var u = [66, 73, 76, 73, 67, 79, 77, 73, 67]
, l = u.length;
function r (r, i, o) {
return s(this, void 0, void 0, function () {
var e, n;
return c(this, function (t) {
switch (t.label) {
case 0:
if (!f(r) || !f(i))
throw new TypeError("[Indexer] Both seasonId and episodeId should be number.");
if (null,
"string" == typeof o && (o = function (t) {
for (var e = atob(t.split(",")[1] || t), n = new ArrayBuffer(e.length), r = new Uint8Array(n), i = 0; i < e.length; i++)
r[i] = e.charCodeAt(i);
return r
}(o)),
e = null,
!o.length || !function (n) {
var r = !0;
return u.some(function (t, e) {
if (n[e] !== u[e])
return !(r = !1)
}),
r
}(o))
throw new TypeError("[Indexer] Invalid index data.");
return e = o.slice(l),
n = function (t, e) {
var n = new Uint8Array(new ArrayBuffer(8));
return n[0] = e,
n[1] = e >> 8,
n[2] = e >> 16,
n[3] = e >> 24,
n[4] = t,
n[5] = t >> 8,
n[6] = t >> 16,
n[7] = t >> 24,
n
}(r, i),
function (t, e) {
for (var n = 0, r = t.length; n < r; n++)
t[n] = t[n] ^ e[n % 8]
}(e, n),
[4, function (o) {
return s(this, void 0, void 0, function () {
var e, n, r, i;
return c(this, function (t) {
switch (t.label) {
case 0:
e = "index.dat",
r = n = null,
t.label = 1;
case 1:
return t.trys.push([1, 3, , 4]),
[4, Object(a.loadAsync)(o)];
case 2:
return n = t.sent(),
[3, 4];
case 3:
throw t.sent();
case 4:
if (!(i = n.files[e]))
throw new Error('[Indexer] Can not find file "' + e + '".');
t.label = 5;
case 5:
return t.trys.push([5, 7, , 8]),
[4, i.async("text")];
case 6:
return r = t.sent(),
[3, 8];
case 7:
throw t.sent();
case 8:
return [2, r]
}
})
})
}(e)];
case 1:
return [2, t.sent()]
}
})
})
}
没办法,接着手动剥离,function r (r, i, o)有三个参数,按照顺序解释应该是seasonId、episodeId、indexData,然后再看看这里返回值里面e = o.slice(l),l应该是前面BILICOMIC的长度,应该是先删除这部分数据构成新的buffer,再往下看,代码构建了一个新的数组n,n长度为8,其中的值是通过seasonId和episodeId通过位运算的到的。
再往下看,终于看到了对buffer下刀的位置了
function (t, e) {
for (var n = 0, r = t.length; n < r; n++)
t[n] = t[n] ^ e[n % 8]
}(e, n)
看来这个n数组是一个mask,剩下的就简单了,用python实现以下上面两步:
- 构建mask数组n
- 对buffer进行异或
python实现如下
def decode_index_data(season_id: int, episode_id: int, buf):
u = [66, 73, 76, 73, 67, 79, 77, 73, 67]
l = len(u)
e = buf[l:]
print(buf)
_e = []
for i in range(len(e)):
_e.append(e[i])
e = np.uint8(_e)
print(e)
n = [0, 0, 0, 0, 0, 0, 0, 0]
n = np.array(n, dtype='uint8')
n[0] = episode_id
n[1] = episode_id >> 8
n[2] = episode_id >> 16
n[3] = episode_id >> 24
n[4] = season_id
n[5] = season_id >> 8
n[6] = season_id >> 16
n[7] = season_id >> 24
print(n)
_n = 0
r = len(e)
while _n < r:
e[_n] = e[_n] ^ n[_n % 8]
_n = _n + 1
pass
print("解密后:")
print(e)
ret = bytes(e)
输出以下结果
![]()
果然看到了PK 有木有!!!!确认是个zip文件,里面包含了一个index.dat的文件,解压出来果然是个json
0x04 下载这些图片~~~
剩下就简单了,这个json包含了所有图片的hash值,其中有个pics的数组,按照顺序存储就好啦~~
0x05 代码
https://github.com/xuruoyu/bilibili_manga_downloader