(二)数据采集——Flume
文章目录
- 一、Flume概述
- 1. 引言
- 2. 数据源
- 二、Flume架构
- 1. 架构图
- 2. 组件及其功能
- 3. Flume运行流程
- 4. Flume核心组件
- Source
- Channel
- Sink
- 三、Flume安装
- 1. 运行环境
- 2. 安装步骤
- 四、Flume使用入门
- 1. 配置文件
- 2. 启动Flume
- 五、Flume和log4j集成
- 1. 依赖
- 2. 配置日志文件
- 3. 配置flume配置文件
- 4. 启动运行
- 5. 查看结果
- 六、多级数据采集结构
- 1. 多级串联
- 2. 多级数据采集结构
一、Flume概述
1. 引言
Flume是一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,可用于从不同来源的系统中采集、汇总和传输大容量的日志数据到指定的数据存储中。
2. 数据源
Flume的采集源包括:console、avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy等。
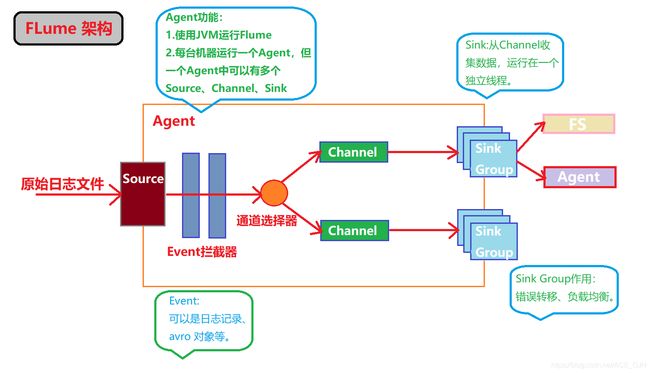
二、Flume架构
1. 架构图
2. 组件及其功能
| 组件 | 功能 |
|---|---|
| Source | 从Client收集数据,传递给Channel。不同的Source可以接受不同的数据格式 |
| Channel | 是一个存储池,连接 sources 和 sinks ,直到有Sink消费掉Channel中的数据或进入到下一个Channel中才会被删除,Sink写入失败会自动重启,很像消息队列 |
| Sink | 消费Channel中的数据,然后送给外部Source |
| Agent | 使用JVM运行FLume,每台机器运行一个Agent,但可以在一个Agent中包含多个Source和Sinks |
| Events | Flume传输数据的基本单位,如果是文本文件,通常是一行记录,这也是事务的基本单位 |
3. Flume运行流程
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带头信息,这些Event由Agent外部的Source生成。当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中,可以把Channel看作一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。Flume支持用户建立多级流。
4. Flume核心组件
Source
从数据发生器接受数据,并将接受的数据以Flume的event格式传递一个或者多个通道Channel,Flume提供多种数据接受方式,比如avro,log4j等。
对现有程序改动最小的使用方式是直接读取程序原来记录的日志文件,基本可以实现无缝接入,对于直接读取文件Source,有两种方式:
- ExecSource:以运行Linux命令的方式,持续的输出最新的数据,如 tail -f 文件名 指令,这种方式文件名必须是指定的,ExecSource可以实现对日志的实时收集,但是Flume不运行或者指令执行出错时,将无法收集到日志数据,无法保证日志数据的完整性。
- SpoolSource:监测配置目录下新增的文件,并将文件中的数据读取出来,需要注意两点:复制到spool目录下的文件不可以再打开编辑,spool目录下不可包含相应的子目录。SpoolSource虽然无法实现实时收集数据,但是可以以分钟分割日志文件,在实际使用过程中,可以结合log4j使用,将log4j的文件分割机制设置为1分钟1次,将文件复制到spool的监控目录,基本实现了实时监控,Flume在传完文件后,会修改文件的后缀。
Channel
Chanel是一个短暂的存储容器,它将从Source处接受到的event合适的数据存储起来,直到他们被Sinks消费掉,它在Source和Sink间起着一共桥梁的作用,Channel是一个完整的事务,这一点保证了数据在收发的时候一致性,并且它可以和任意数量的Source和Sink连接。
Channel支持的类型有:JDBC Channel, File Channel , Memory Channel和Psuedo Transaction Channel等,目前比较流行前三种。
- Memory Channel可以实现高速的吞吐,但是无法保证数据的完整性。
- FIle Channel保证数据的完整性和一致性。在具体配置File Channel时,建议FIle Channel的目录和程序日志文件保存的目录设置成不同的磁盘,以便提高效率。
Sink
Sink将数据存到集中存储的容器中比如文件系统、数据库、Hadoop,它从chanel消费数据(events)并将其传递的目标地,目标地可能是另一个Sink,也可能是HDFS、HBase。
三、Flume安装
1. 运行环境
- JDK 1.8以上
# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
2. 安装步骤
- 解压flume安装包
# tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /usr/flume/
- 验证是否安装成功
# ./bin/flume-ng version
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
四、Flume使用入门
官方手册参考: Flume 1.9.0用户指南
1. 配置文件
# example.conf:单节点Flume配置
# 命名此代理上的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述/配置源
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述接收器
a1.sinks.k1.type = logger
# 使用一个通道来缓冲事件到内存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将源和接收器绑定到通道
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2. 启动Flume
- 安装telnet
yum install -y telnet
- 启动flume
./bin/flume-ng agent -c conf -n a1 -f conf/demo1.conf -Dflume.root.logger=INFO,console
- 产生数据
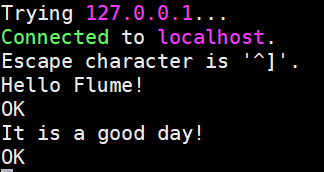
- 采集数据

五、Flume和log4j集成
1. 依赖
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.25version>
dependency>
<dependency>
<groupId>org.apache.flumegroupId>
<artifactId>flume-ng-sdkartifactId>
<version>1.9.0version>
dependency>
<dependency>
<groupId>org.apache.flume.flume-ng-clientsgroupId>
<artifactId>flume-ng-log4jappenderartifactId>
<version>1.9.0version>
dependency>
2. 配置日志文件
log4j.rootLogger=info,stdout,FLUME
#console
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%p %d{yyyy-MM-dd HH:mm:ss} %c %m%n
flume.log.dir=./logs
flume.log.file=flume.log
log4j.appender.LOGFILE=org.apache.log4j.RollingFileAppender
log4j.appender.LOGFILE.MaxFileSize=100MB
log4j.appender.LOGFILE.MaxBackupIndex=10
log4j.appender.LOGFILE.File=${flume.log.dir}/${flume.log.file}
log4j.appender.LOGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.LOGFILE.layout.ConversionPattern=%d{dd MMM yyyy HH:mm:ss,SSS} %-5p [%t] (%C.%M:%L) %x - %m%n
#flume
log4j.appender.FLUME=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.FLUME.Hostname = 198.166.121.111
log4j.appender.FLUME.Port = 6666
log4j.appender.FLUME.UnsafeMode = true
log4j.appender.FLUME.layout=org.apache.log4j.PatternLayout
log4j.appender.FLUME.layout.ConversionPattern=%p %d{yyyy-MM-dd HH:mm:ss} %c %m%n
将上面的log4j.properties配置文件放在src/main/java/resources目录下
3. 配置flume配置文件
a1.channels = c1
a1.sources = s1
a1.sinks = k1
a1.sources.s1.type = avro
a1.sources.s1.bind = SparkOnYarn
a1.sources.s1.port = 6666
a1.sources.s1.channels = c1
a1.channels.c1.type = memory
a1.sinks.k1.type = file_roll
a1.sinks.k1.sink.directory = /root/logs
a1.sinks.k1.sink.rollInterval=86400
a1.sinks.k1.sink.batchSize=100
a1.sinks.k1.sink.serializer=text
a1.sinks.k1.sink.serializer.appendNewline = false
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
4. 启动运行
# ./bin/flume-ng agent -c conf/ -n a1 -f conf/demo2.conf -Dflume.root.logger=INFO,console
5. 查看结果
# cat logs/*
INFO 2019-12-22 16:43:28 org.apache.flume.api.NettyAvroRpcClient Using default maxIOWorkers
INFO 2019-12-22 16:43:28 ace.gjh.TestFlumeLog4j time:1577004208711
INFO 2019-12-22 16:43:30 ace.gjh.TestFlumeLog4j time:1577004208711
INFO 2019-12-22 16:43:32 ace.gjh.TestFlumeLog4j time:1577004208711
INFO 2019-12-22 16:43:34 ace.gjh.TestFlumeLog4j time:1577004208711
INFO 2019-12-22 16:43:36 ace.gjh.TestFlumeLog4j time:1577004208711
INFO 2019-12-22 16:43:38 ace.gjh.TestFlumeLog4j time:1577004208711
INFO 2019-12-22 16:43:40 ace.gjh.TestFlumeLog4j time:1577004208711
INFO 2019-12-22 16:43:42 ace.gjh.TestFlumeLog4j time:1577004208711
INFO 2019-12-22 16:43:44 ace.gjh.TestFlumeLog4j time:1577004208711
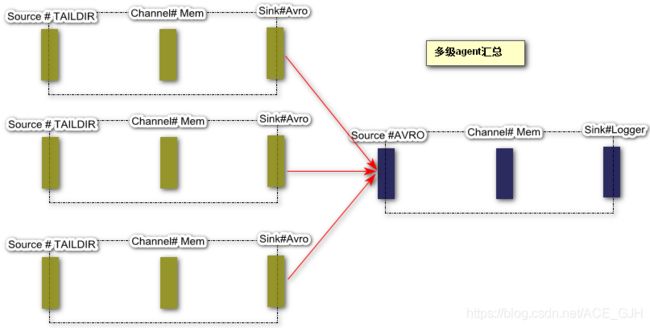
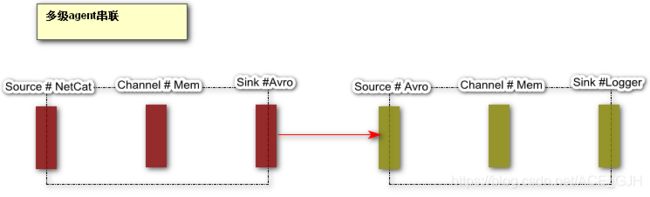
六、多级数据采集结构
1. 多级串联
2. 多级数据采集结构