TensorFlow2.0入门到进阶系列——5.1_TensorFlow进阶篇
5.1_TensorFlow进阶篇
- 0、estimator简介
- 1、Tf.estimator使用
- 1.1、Dataset和Estimator的完整使用流程
- 2.1、API列表
- 2、Estimator实战
- 2.1、feature_column使用
- 2.2、keras_to_estimator 自定义estimator
- 2.3、预定义estimator使用
- 3、tensorflow1.0回顾
- 3.1、API列表
- 3.2、tf1.0和tf2.0区别
- 4、总结
使用TensorFlow的底层API开发机器学习模型时,需要显式地定义模型中的变量和输入数据、以及对会话进行显式的声明和管理,这需要不小的编码量。而使用更高层的Dataset工具类可以很轻松、高效地处理大量的输入数据以及不同的数据格式,相比基于feed_dict的数据输入方式更加高效和规整。并且使用Estimator工具类可以简化机器学习模型的构建过程,Estimator可以自动管理图的构建、变量初始化、模型保存及恢复过程。对一般机器学习pipeline中的训练、评估、预测三个过程进行统一管理。
0、estimator简介
Estimator封装了模型的构建、训练、评估、预估以及保存过程,将数据的输入从模型中分离出来。数据输入需要编写单独的函数。
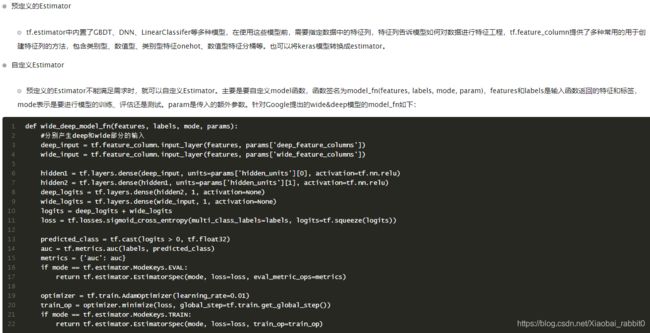
1、Tf.estimator使用
- keras转estimator
- 使用预定义的estimator
- BaseLineClassifier
- LinearClassifier
- DNNClassifier
- Tf.feature_column做特征工程
1.1、Dataset和Estimator的完整使用流程
- 定义用于训练和评估的输入函数input_fn;
- 根据数据集的特点,定义好feature_column;
- 使用预定义的Estimator或者自定义模型函数;
- 调用Estimator的train、eval和predict方法产生结果。
2.1、API列表
- Tf.keras.estimator.to_estimator
- Train,evaluate
- Tf.estimator.BaselineClassifier
- Tf.estimator.LinearClassifier
- Tf.estimator.DNNClassifier
- Tf.feature_column
- categorical_column_with_vocabulary_list
- numweric_column
- indicator_column
- cross_column
- keras.layers.DenseFeatures
2、Estimator实战
2.1、feature_column使用
加载库
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
#import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__,module.__version__)
数据加载及处理
# 数据地址
# https://storage.googleapis.com/tf-datasets/titanic/train.csv
# https://storage.googleapis.com/tf-datasets/titanic/eval.csv
train_file = "./data/titanic/train.csv"
eval_file = "./data/titanic/eval.csv"
train_df = pd.read_csv(train_file)
eval_df = pd.read_csv(eval_file)
print(train_df.head())
print(eval_df.head())
#survived是要预测的值,不能在特征值中,所以要选出来。
y_train = train_df.pop('survived')
y_eval = eval_df.pop('survived')
#pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
print(train_df.head())
print(eval_df.head())
print(y_train.head())
print(y_eval.head())
#查看统计量
train_df.describe() #pandas数据很方便

建模部分
#feature_column使用(连续特征、离散特征)
#特征分类:离散特征、连续特征
categorical_columns = ['sex','n_siblings_spouses','parch','class','deck','embark_town','alone']
numeric_columns = ['age','fare']
feature_columns = []
#对每个离散特征进行处理
for categorical_column in categorical_columns:
vocab = train_df[categorical_column].unique() #特征所在列,所有可能的值
print(categorical_column,vocab)
feature_columns.append( #3、将编码好的离散特征加到feature_columns里面
tf.feature_column.indicator_column( #2、对离散特征进行one-hot编码
tf.feature_column.categorical_column_with_vocabulary_list( #1、对于离散函数,定义feature_column
categorical_column,vocab)))
#对于连续特征的处理
for categorical_column in numeric_columns:
feature_columns.append(
tf.feature_column.numeric_column( #连续特征,直接用numeric_column封装即可
categorical_column,dtype = tf.float32))
#定义一个函数,构建dataset
def make_dataset(data_df,label_df,epochs = 10,shuffle = True,batch_size = 32): #(x,y,运行10次,混排,一次32)
#tf.data.Dataset.from_tensor_slices()函数,切分传入Tensor的第一个维度,生成相应的dataset
dataset = tf.data.Dataset.from_tensor_slices((dict(data_df),label_df)) #构建数据集
if shuffle:
dataset = dataset.shuffle(10000)
dataset = dataset.repeat(epochs).batch(batch_size)
return dataset
#查看dict(train_df)
dict(train_df)
train_dataset = make_dataset(train_df,y_train,batch_size = 5)
for x,y in train_dataset.take(1): #zhi执行一次
print(x,y)
#keras.layers.DenseFeature
for x,y in train_dataset.take(1):
age_column = feature_columns[7]
gender_column = feature_columns[0]
print(keras.layers.DenseFeatures(age_column)(x).numpy())
print(keras.layers.DenseFeatures(gender_column)(x).numpy())
#keras.layers.DenseFeature
for x,y in train_dataset.take(1):
print(keras.layers.DenseFeatures(feature_columns)(x).numpy())
model = keras.models.Sequential([
keras.layers.DenseFeatures(feature_columns),
keras.layers.Dense(100,activation='relu'),
keras.layers.Dense(100,activation='relu'),
keras.layers.Dense(2,activation='softmax')
])
model.compile(loss = 'spare_categorical_crossentropy',optimizer = keras.optimizers.SGD(lr=0.01),
metrics = ['accuracy'])
# 1. model.fit
# 2.model -> estimator -> train
train_dataset = make_dataset(train_dataset,y_train,epochs=100)
eval_dataset = make_dataset(eval_df,y_eval,epochs=1,shuffle=False)
history = model.fit(train_dataset,
validation_data= eval_dataset,
steps_per_epoch=20,
validation_steps=8,
epochs = 100)
estimator = keras.estimator.model_to_estimator(model)
#1.function
#2.return a.(features,labels) b.dataset -> (feature,label)
estimator.train(input_fn = lambda : make_dataset(
train_df,y_train,epochs = 100))
2.2、keras_to_estimator 自定义estimator
2.3、预定义estimator使用

- linear
'''linear'''
linear_output_dir = 'linear_model'
if not os.path.exists(linear_output_dir):
os.mkdir(linear_output_dir)
linear_estimator = tf.estimator.LinearClassifier(
model_dir = linear_output_dir,
n_classes=2,
feature_columns=feature_columns)
linear_estimator.train(input_fn= lambda : make_dataset(train_df,y_train,epochs=100))
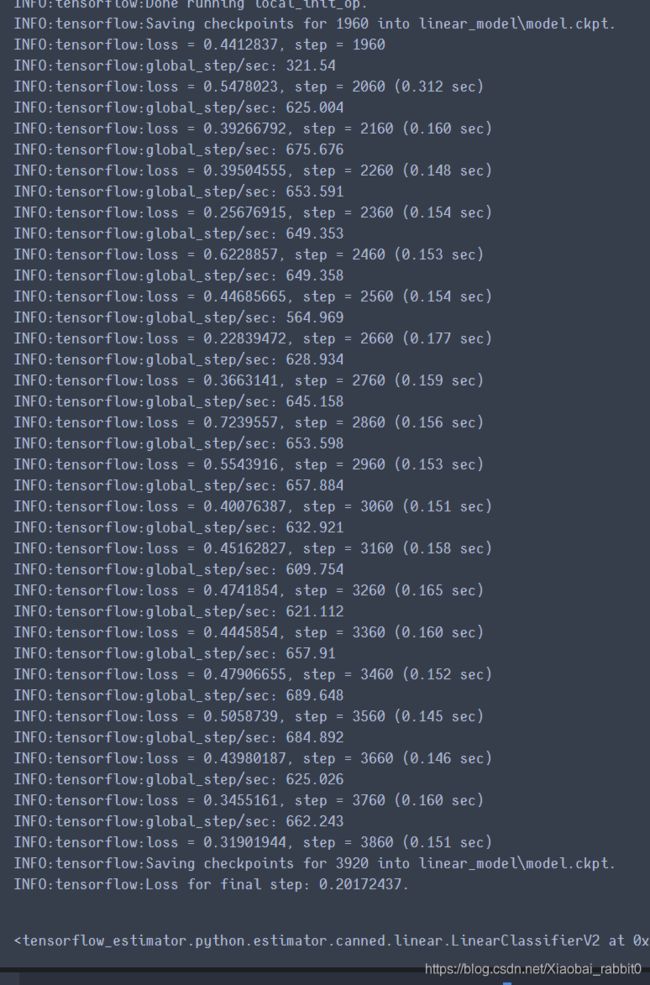
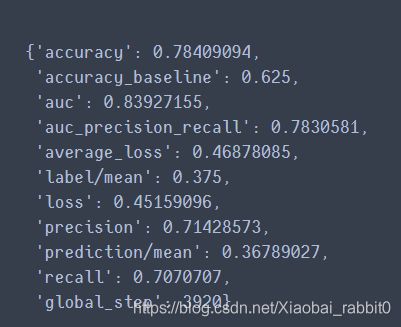
linear_estimator.evaluate(input_fn= lambda : make_dataset(
eval_df,y_eval,epochs = 1,shuffle = False))
- dnn
'''dnn'''
dnn_output_dir = './dnn_model'
if not os.path.exists(dnn_output_dir):
os.mkdir(dnn_output_dir)
dnn_estimator = tf.estimator.DNNClassifier(
model_dir=dnn_output_dir,
n_classes=2,
feature_columns=feature_columns,
hidden_units=[128,128],
activation_fn=tf.nn.relu,
optimizer='Adam')
dnn_estimator.train(input_fn = lambda : make_dataset(train_df,y_train,epochs = 100))
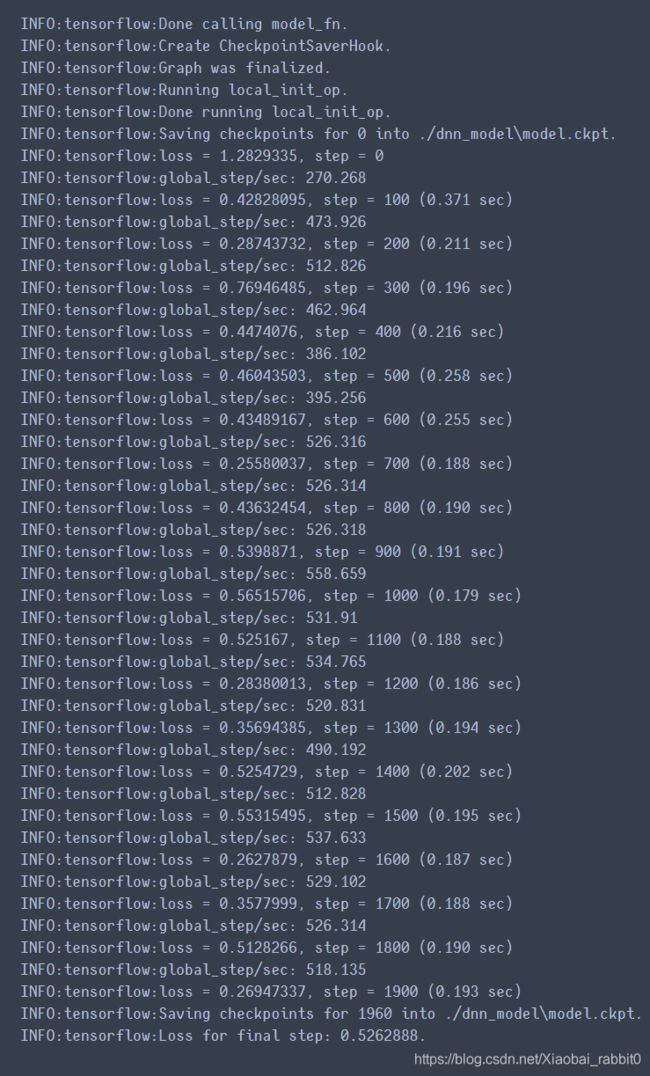
dnn_estimator.evaluate(input_fn=lambda:make_dataset(eval_df,y_eval,epochs=1,shuffle=False))

总结:用交叉特征,linear结果变好,但是dnn结果反而变差了。
说明:特征提取方法,对不同模型的效果是不一样的。不但要考虑不同特征之间的互补性,还要考虑和模型之间的适配能力。
3、tensorflow1.0回顾
- tf1.0实现全连接网络
- placeholder,sess,feed_dict
- Dataset使用
- 自定义estimator
- 实战
- 总结tf2.0与tf1.0的区别
3.1、API列表
- tf1.0实现全连接网络
- placeholder,tf.layers.dense,tf.train.AdamOptimizer
- tf.losses.sparse_softmax_cross_entropy
- tf.global_variables_initializer,feed_dict
- Dataset(tf2.0已经去掉了)
- Dataset.make_one_shot_iterator
- Dataset.make_initializable_iterator
- 自定义estimator
- tf.feature_column.input_layer
- tf.estimator.EstimatorSpec
- tf.metrics.accuracy
3.2、tf1.0和tf2.0区别
- 静态图与动态图
- tf1.0:Sess\feed_dict\placeholder被移除
- tf1.0:make_one_shot_iterator\make_initializable_iterator被移除
- tf2.0:eager [email protected]\AutoGraph

其中,f()就是图,也可以理解成一个函数

其中,tf.function、AutoGraph把普通的python代码,转成tensorflow的图结构。
这种转换的好处
- tf.function、AutoGraph
- 性能好(经过优化的,尤其是在GPU)
- 可以导入导出为SavedModel
- eg:
- for/while -> tf.while_loop
- if -> tf.cond
- for_in dataset -> dataset.reduce
API变动
- tensorflow现在有2000个API,500在根空间下
- 一些空间被建立了但是没有包含所有相关API
- tf.round没有在tf.math下
- 有些在根空间下,但是很少被使用tf.zeta
- 有些经常使用,不在根空间下tf.manip
- 有些空间层次太深
- tf.saved_model.signature_constants.CLASSIFY_INPUTS
- tf.saved_model.CLASSIFY_INPUTS
- 重复API
- tf.layers -> tf.keras.layers
- tf.losses -> tf.keras.losses
- tf.metrics -> tf.keras.metrics
- 有些API有前缀所以应该建立子空间
- tf.string_strip -> tf.string.strip
- 重新组织
- tf.debugging、tf.dtypes、tf.io、tf.quantization等
如何将tf1.0代码升级为tf2.0代码
- 替换session.run
- feed_dict、tf.placeholder变成函数调用
- 替换API
- tf.get_variable替换为tf.variable
- variable_scope被替换为以下东西的一个:
- tf.keras.layers.Layer
- tf.keras.Model
- tf.Module
- 升级训练流程
- 使用tf.keras.Model.fit
- 升级数据输入
- Iterator变成直接输入
tf1.0代码:

升级为tf2.0代码:

4、总结
- tf.estimator的使用
- 预定义estimator、自定义estimator
- feature_column组织数据
- tf1.0基础使用
- tf1.0与tf2.0的区别
- API变动,如何升级