MHA+keepalive高可用环境搭建
MHA(Master HighAvailability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。
MHA Node运行在每台MySQL服务器上,MHAManager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
实验环境

10.192.203.201, 10.192.203.101上面安装了keepalive,vip是108
实验步骤
1 修改/etc/hosts
在mha管理节点和数据节点所在服务器上添加这些服务器ip和主机名对应关系。
如:
cat /etc/hosts
10.192.203.201 pc2
10.192.203.101 slave1
10.192.203.102 PC
2 Mysql主从复制环境搭建
搭建过程略,可以参考参考:http://blog.csdn.net/yabingshi_tech/article/details/45192599。
要确保两个从库设置read_only。
要确保master和备选master为主主互备模式,否则后面配置过程有可能会发生错误。
3 配置主机信任关系
在所有节点生成密码文件,然后将其拷贝到本机及其他服务器上,这里以10.192.203.201为例:
# ssh-keygen
# ssh-copy-id [email protected]
# ssh-copy-id [email protected]
# ssh-copy-id [email protected]
然后ssh验证下,是否可以免密码登录。
4 安装MHA
点击这里进行下载:
http://download.csdn.net/download/yabignshi/8974251
http://download.csdn.net/detail/yabignshi/8974265
在所有数据节点上安装:
yum install perl-DBD-MySQL -y
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
安装完成后会在/usr/bin目录下生成以下脚本文件(这些工具通常由MHAManager的脚本触发,无需人为操作):
save_binary_logs //保存和复制master的二进制日志
apply_diff_relay_logs //识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog //去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs //清除中继日志(不会阻塞SQL线程)
在管理节点上安装:
yum install perl-DBD-MySQL -y(由于本实验环境管理节点和数据节点部署在了同一台服务器上,所以这里不用重复安装)
yum install perl-Config-Tiny -y
yum install epel-release -y
yum install perl-Log-Dispatch -y
yum install perl-Parallel-ForkManager -y
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm(由于本实验环境管理节点和数据节点部署在了同一台服务器上,所以这里不用重复安装)
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
安装完成后会在/usr/bin目录下生成以下脚本文件:
-rwxr-xr-x. 1 root root 1995 Apr 1 2014 masterha_check_repl
-rwxr-xr-x. 1 root root 1779 Apr 1 2014 masterha_check_ssh
-rwxr-xr-x. 1 root root 1865 Apr 1 2014 masterha_check_status
-rwxr-xr-x. 1 root root 3201 Apr 1 2014 masterha_conf_host
-rwxr-xr-x. 1 root root 2517 Apr 1 2014 masterha_manager
-rwxr-xr-x. 1 root root 2165 Apr 1 2014 masterha_master_monitor
-rwxr-xr-x. 1 root root 2373 Apr 1 2014 masterha_master_switch
-rwxr-xr-x. 1 root root 5171 Apr 1 2014 masterha_secondary_check
-rwxr-xr-x. 1 root root 1739 Apr 1 2014 masterha_stop
-rwxr-xr-x. 1 root root 4807 Apr 1 2014 filter_mysqlbinlog
-rwxr-xr-x. 1 root root 7525 Apr 1 2014 save_binary_logs
-rwxr-xr-x. 1 root root 8261 Apr 1 2014 purge_relay_logs
-rwxr-xr-x. 1 root root 16367 Apr 1 2014 apply_diff_relay_logs
5 安装配置keepalive
5.1 安装keepalive
在master和备选master上安装keepalive:
yum install -y popt-devel
cd /usr/local/src
wget http://www.keepalived.org/software/keepalived-1.2.2.tar.gz
tar zxvf keepalived-1.2.2.tar.gz
cd keepalived-1.2.2
./configure --prefix=/
make
make install
5.2 修改配置文件
vi/etc/keepalived/keepalived.conf
master和备选master配置文件内容相同。
#ConfigurationFile for keepalived
global_defs {
notification_email { ######定义接受邮件的邮箱
[email protected]
}
notification_email_from [email protected] ######定义发送邮件的邮箱
smtp_server mail.tuge.com
smtp_connect_timeout 10
}
vrrp_instance vrrptest { ######定义vrrptest实例
state BACKUP ######服务器状态
interface eth0 ######使用的接口
virtual_router_id 51 ######虚拟路由的标志,一组lvs的虚拟路由标识必须相同,这样才能切换
priority 150 ######服务启动优先级,值越大,优先级越高,BACKUP 不能大于MASTER
advert_int 1 ######服务器之间的存活检查时间
authentication {
auth_type PASS ######认证类型
auth_pass ufsoft ######认证密码,一组lvs 服务器的认证密码必须一致
}
virtual_ipaddress { ######虚拟IP地址
10.192.203.108
}
}
这里master服务器的state不配置成MASTER,且配置的优先级一样,是期望在master宕机后再恢复时,不主动将MASTER状态抢过来,避免MySQL服务的波动。
这里没有配置vrrp_script,在后面会让mha实现vip的自动漂移。
5.3 vi /etc/sysconfig/iptables
#注意,在两台机器上都要修改。
添加:
-A INPUT-d 10.192.203.108/32 -j ACCEPT
-A INPUT-d 224.0.0.18 -j ACCEPT #添加VRRP通讯支持
注意:第一行中的10.192.203.108需要改成你自己的vip。
serviceiptables restart
5.4 启动keepalive
service keepalived start
分别执行ip addr命令,可以在其中一台机器上看到虚拟IP
5.5 测试
停止master服务器keepalived,检查VIP是否切换到备选master服务器(用ip addr命令验证即可);
6 配置Mha
6.1 添加管理账号
#在数据节点上执行以下操作
grant all privileges on *.* TO mha@'10.192.%' IDENTIFIED BY 'test';
flush privileges;
6.2 配置/etc/mha/app1.cnf
#只在管理端做
mkdir /etc/mha
mkdir -p /var/log/mha/app1
vi /etc/mha/app1.cnf
添加:
[server default]
manager_log=/var/log/mha/app1/manager.log
manager_workdir=/var/log/mha/app1.log
master_binlog_dir=/data/mysql/data
master_ip_failover_script= /usr/bin/master_ip_failover
master_ip_online_change_script=/usr/bin/master_ip_online_change
report_script=/usr/bin/send_report
user=mha
password=test
ping_interval=2
repl_password=beijing
repl_user=rep_user
ssh_user=root
[server1]
hostname=10.192.203.201
port=3306
[server2]
candidate_master=1
check_repl_delay=0
hostname=10.192.203.101
port=3306
[server3]
hostname=10.192.203.102
port=3306
在server default中的配置,是三台数据节点共同的配置,也可以放到具体的server中进行定制。/*参数概念解释:master_binlog_dir=/data/mysql/data #设置master 保存binlog的位置,以便MHA可以找到master的日志
master_ip_failover_script=/usr/bin/master_ip_failover #设置自动failover时候的切换脚本
master_ip_online_change_script=/usr/bin/master_ip_online_change #设置手动切换时候的切换脚本
report_script=/usr/bin/send_report //设置发生切换后发送的报警的脚本
ping_interval=2 #设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行failover
candidate_master=1 #设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
check_repl_delay=0 #默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
*/ 6.3 master_ip_failover脚本代码
要想把keepalived服务引入MHA,我们只需要修改切换是触发的脚本文件master_ip_failover即可,在该脚本中添加在master发生宕机时对keepalived的处理。
在管理节点编辑脚本/usr/bin/master_ip_failover,修改后如下:
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '10.192.203.108';
my $ssh_start_vip ="/etc/init.d/keepalived start";
my $ssh_stop_vip ="/etc/init.d/keepalived stop";
GetOptions(
'command=s' =>\$command,
'ssh_user=s' =>\$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' =>\$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' =>\$new_master_host,
'new_master_ip=s' =>\$new_master_ip,
'new_master_port=i' =>\$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPTTEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host\n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIPon the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status--orig_master_host=host --orig_master_ip=ip --orig_master_port=port--new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
注意:my $vip = '10.192.203.108';这一行中的vip请根据情况改成自己的虚拟IP。
chmod +x /usr/bin/master_ip_failover
6.4 master_ip_online_change脚本代码
在管理节点编辑脚本/usr/bin/master_ip_online_change
#!/usr/bin/env perl
# Copyright (C) 2011 DeNA Co.,Ltd.
#
# This program is free software; you can redistribute it and/or modify
# itunder the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is notcomplete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
use MHA::NodeUtil;
use Time::HiRes qw( sleep gettimeofdaytv_interval );
use Data::Dumper;
my $_tstart;
my $_running_interval = 0.1;
my (
$command, $orig_master_is_new_slave, $orig_master_host,
$orig_master_ip, $orig_master_port, $orig_master_user,
$orig_master_password, $orig_master_ssh_user, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password, $new_master_ssh_user
);
my $vip = '10.192.203.108/32';
my $key = '1';
my $ssh_start_vip = "/etc/init.d/keepalivedstart";
my $ssh_stop_vip = "/etc/init.d/keepalivedstop";
my $orig_master_ssh_port = 22;
my $new_master_ssh_port = 22;
GetOptions(
'command=s' =>\$command,
'orig_master_is_new_slave' => \$orig_master_is_new_slave,
'orig_master_host=s' =>\$orig_master_host,
'orig_master_ip=s' =>\$orig_master_ip,
'orig_master_port=i' =>\$orig_master_port,
'orig_master_user=s' =>\$orig_master_user,
'orig_master_password=s' =>\$orig_master_password,
'orig_master_ssh_user=s' =>\$orig_master_ssh_user,
'new_master_host=s' =>\$new_master_host,
'new_master_ip=s' =>\$new_master_ip,
'new_master_port=i' =>\$new_master_port,
'new_master_user=s' =>\$new_master_user,
'new_master_password=s' =>\$new_master_password,
'new_master_ssh_user=s' =>\$new_master_ssh_user,
'orig_master_ssh_port=i' =>\$orig_master_ssh_port,
'new_master_ssh_port=i' =>\$new_master_ssh_port,
);
exit &main();
sub current_time_us {
my( $sec, $microsec ) = gettimeofday();
my$curdate = localtime($sec);
return $curdate . " " . sprintf( "%06d", $microsec);
}
sub sleep_until {
my$elapsed = tv_interval($_tstart);
if( $_running_interval > $elapsed ) {
sleep( $_running_interval - $elapsed );
}
}
sub get_threads_util {
my$dbh = shift;
my$my_connection_id = shift;
my$running_time_threshold = shift;
my$type = shift;
$running_time_threshold = 0 unless ($running_time_threshold);
$type = 0 unless($type);
my@threads;
my$sth = $dbh->prepare("SHOW PROCESSLIST");
$sth->execute();
while ( my $ref = $sth->fetchrow_hashref() ) {
my $id = $ref->{Id};
my $user = $ref->{User};
my $host = $ref->{Host};
my $command =$ref->{Command};
my $state = $ref->{State};
my $query_time = $ref->{Time};
my $info = $ref->{Info};
$info =~ s/^\s*(.*?)\s*$/$1/ if defined($info);
next if ( $my_connection_id == $id );
next if ( defined($query_time) && $query_time <$running_time_threshold );
next if ( defined($command) && $command eq "Binlog Dump" );
next if ( defined($user) && $user eq "system user" );
next
if ( defined($command)
&& $command eq "Sleep"
&& defined($query_time)
&& $query_time >= 1 );
if ( $type >= 1 ) {
next if ( defined($command) && $command eq "Sleep" );
next if ( defined($command) && $command eq "Connect");
}
if ( $type >= 2 ) {
next if ( defined($info) && $info =~ m/^select/i );
next if ( defined($info) && $info =~ m/^show/i );
}
push @threads, $ref;
}
return @threads;
}
sub main {
if( $command eq "stop" ) {
## Gracefully killing connections on the current master
#1. Set read_only= 1 on the new master
#2. DROP USER so that no app user can establish new connections
#3. Set read_only= 1 on the current master
#4. Kill current queries
#* Any database access failure will result in script die.
my $exit_code = 1;
eval {
## Setting read_only=1 on the new master (to avoid accident)
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error(die_on_error)_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
print current_time_us() . " Set read_only on the new master..";
$new_master_handler->enable_read_only();
if ( $new_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
$new_master_handler->disconnect();
# Connecting to the orig master, die if any database error happens
my $orig_master_handler = new MHA::DBHelper();
$orig_master_handler->connect( $orig_master_ip, $orig_master_port,
$orig_master_user, $orig_master_password, 1 );
## Drop application user so that nobody can connect. Disablingper-session binlog beforehand
$orig_master_handler->disable_log_bin_local();
print current_time_us() . " Drpping appuser on the orig master..\n";
#FIXME_xxx_drop_app_user($orig_master_handler);
## Waiting for N * 100 milliseconds so that current connections can exit
my $time_until_read_only = 15;
$_tstart = [gettimeofday];
my @threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_read_only > 0 && $#threads >= 0 ) {
if ( $time_until_read_only % 5 == 0 ) {
printf
"%s Waiting all running %d threads aredisconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_read_only * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump ."\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_read_only--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Setting read_only=1 on the current master so that nobody(exceptSUPER) can write
print current_time_us() . " Set read_only=1 on the orig master..";
$orig_master_handler->enable_read_only();
if ( $orig_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
## Waiting for M * 100 milliseconds so that current update queries cancomplete
my $time_until_kill_threads = 5;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_kill_threads > 0 && $#threads >= 0 ) {
if ( $time_until_kill_threads % 5 == 0 ) {
printf
"%s Waiting all running %d queries aredisconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_kill_threads * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump ."\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_kill_threads--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Terminating all threads
print current_time_us() . " Killing all applicationthreads..\n";
$orig_master_handler->kill_threads(@threads) if ( $#threads >= 0);
print current_time_us() . " done.\n";
$orig_master_handler->enable_log_bin_local();
$orig_master_handler->disconnect();
## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK
eval {
`ssh -p$orig_master_ssh_port $orig_master_ssh_user\@$orig_master_host\" $ssh_stop_vip \"`;
};
if ($@) {
warn $@;
}
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
## Activating master ip on the new master
#1. Create app user with write privileges
#2. Moving backup script if needed
#3. Register new master's ip to the catalog database
# We don't return error even thoughactivating updatable accounts/ip failed so that we don't interrupt slaves'recovery.
# If exit code is 0 or 10, MHA does notabort
my $exit_code = 10;
eval {
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
## Set read_only=0 on the new master
$new_master_handler->disable_log_bin_local();
print current_time_us() . " Setread_only=0 on the new master.\n";
$new_master_handler->disable_read_only();
## Creating an app user on the new master
print current_time_us() . " Creating app user on the newmaster..\n";
#FIXME_xxx_create_app_user($new_master_handler);
$new_master_handler->enable_log_bin_local();
$new_master_handler->disconnect();
## Update master ip on the catalog database, etc
`ssh -p$new_master_ssh_port $new_master_ssh_user\@$new_master_host\" $ssh_start_vip \"`;
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
#do nothing
exit 0;
}
else {
&usage();
exit 1;
}
}
sub usage {
print
"Usage: master_ip_online_change--command=start|stop|status --orig_master_host=host --orig_master_ip=ip--orig_master_port=port --new_master_host=host --new_master_ip=ip--new_master_port=port\n";
die;
}
注意:需要把my $vip = '10.192.203.108/32';改成自己的vip即可。
chmod +x /usr/bin/master_ip_online_change
6.5 send_report脚本代码
在管理节点编辑脚本/usr/bin/send_report
#!/usr/bin/perl
# Copyright (C) 2011 DeNA Co.,Ltd.
#
# This program is free software; you can redistribute it and/or modify
# itunder the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is notcomplete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Mail::Sender;
use Getopt::Long;
#new_master_host and new_slave_hosts areset only when recovering master succeeded
my ( $dead_master_host, $new_master_host, $new_slave_hosts,$subject, $body );
my $smtp='smtp.163.com';
my $mail_from='[email protected]';
my $mail_user='[email protected]';
my $mail_pass='Password';
my$mail_to=['[email protected]','[email protected]'];
GetOptions(
'orig_master_host=s' => \$dead_master_host,
'new_master_host=s' =>\$new_master_host,
'new_slave_hosts=s' =>\$new_slave_hosts,
'subject=s' =>\$subject,
'body=s' => \$body,
);
mailToContacts($smtp,$mail_from,$mail_user,$mail_pass,$mail_to,$subject,$body);
sub mailToContacts {
my ( $smtp, $mail_from, $user, $passwd, $mail_to, $subject, $msg ) = @_;
open my $DEBUG, "> /tmp/monitormail.log"
or die "Can't open the debug file:$!\n";
my $sender = new Mail::Sender {
ctype => 'text/plain;charset=utf-8',
encoding => 'utf-8',
smtp => $smtp,
from => $mail_from,
auth => 'LOGIN',
TLS_allowed => '0',
authid => $user,
authpwd => $passwd,
to => $mail_to,
subject => $subject,
debug => $DEBUG
};
$sender->MailMsg(
{ msg => $msg,
debug => $DEBUG
}
)or print $Mail::Sender::Error;
return 1;
}
# Do whatever you want here
exit 0;
注意:需要修改下以下几行内容:
my $smtp='smtp.163.com';
my $mail_from='[email protected]';
my $mail_user='[email protected]';
my $mail_pass='Password';
my$mail_to=['[email protected]','[email protected]'];
#f赋予执行权限
chmod +x /usr/bin/send_report
注意:需要确保管理节点服务器可以正常发送邮件。可以先用sendEmail命令试下。
6.6 设置relay log的清除方式(在每个slave节点上)
从服务器配置文件要确保relay_log_purge=0,否则在masterha_check_repl时会报错warning,relay_log_purge=0 is not set on slave
主库将来发生切换变成一个从库后,记得在原先的主库上也执行该操作。
MHA在发生切换的过程中,从库的恢复过程中依赖于relay log的相关信息,所以这里要将relay log的自动清除设置为OFF,采用手动清除relay log的方式。
在默认情况下,从服务器上的中继日志会在SQL线程执行完毕后被自动删除。
但是在MHA环境中,这些中继日志在恢复其他从服务器时可能会被用到,因此需要禁用中继日志的自动删除功能。
定期清除中继日志需要考虑到复制延时的问题。在ext3的文件系统下,删除大的文件需要一定的时间,会导致严重的复制延时。
为了避免复制延时,需要暂时为中继日志创建硬链接,因为在linux系统中通过硬链接删除大文件速度会很快。
(在mysql数据库中,删除大表时,通常也采用建立硬链接的方式)
7 检查mha manage是不是配置成功
7.1 检查ssh登录
[[email protected]]# masterha_check_ssh--conf=/etc/mha/app1.cnf
Mon Feb 13 15:35:25 2017 - [warning] Globalconfiguration file /etc/masterha_default.cnf not found. Skipping.
Mon Feb 13 15:35:25 2017 - [info] Readingapplication default configuration from /etc/mha/app1.cnf..
Mon Feb 13 15:35:25 2017 - [info] Readingserver configuration from /etc/mha/app1.cnf..
Mon Feb 13 15:35:25 2017 - [info] StartingSSH connection tests..
Mon Feb 13 15:35:26 2017 - [debug]
Mon Feb 13 15:35:25 2017 - [debug] Connecting via SSH [email protected](10.192.203.201:22) [email protected](10.192.203.101:22)..
Mon Feb 13 15:35:25 2017 - [debug] ok.
Mon Feb 13 15:35:25 2017 - [debug] Connecting via SSH [email protected](10.192.203.201:22) [email protected](10.192.203.102:22)..
Mon Feb 13 15:35:26 2017 - [debug] ok.
Mon Feb 13 15:35:26 2017 - [debug]
Mon Feb 13 15:35:25 2017 - [debug] Connecting via SSH [email protected](10.192.203.101:22) [email protected](10.192.203.201:22)..
Mon Feb 13 15:35:25 2017 - [debug] ok.
Mon Feb 13 15:35:25 2017 - [debug] Connecting via SSH [email protected](10.192.203.101:22) [email protected](10.192.203.102:22)..
Mon Feb 13 15:35:26 2017 - [debug] ok.
Mon Feb 13 15:35:27 2017 - [debug]
Mon Feb 13 15:35:26 2017 - [debug] Connecting via SSH [email protected](10.192.203.102:22) [email protected](10.192.203.201:22)..
Mon Feb 13 15:35:26 2017 - [debug] ok.
Mon Feb 13 15:35:26 2017 - [debug] Connecting via SSH [email protected](10.192.203.102:22) [email protected](10.192.203.101:22)..
Mon Feb 13 15:35:27 2017 - [debug] ok.
Mon Feb 13 15:35:27 2017 - [info] All SSHconnection tests passed successfully.
假如ssh可以免密码登录其他几台服务器,但检查ssh时却报错:
[root@PC .ssh]# masterha_check_ssh--conf=/etc/mha/app1.cnf
Fri Feb 10 10:04:35 2017 - [warning] Globalconfiguration file /etc/masterha_default.cnf not found. Skipping.
Fri Feb 10 10:04:35 2017 - [info] Readingapplication default configuration from /etc/mha/app1.cnf..
Fri Feb 10 10:04:35 2017 - [info] Readingserver configuration from /etc/mha/app1.cnf..
Fri Feb 10 10:04:35 2017 - [info] StartingSSH connection tests..
Fri Feb 10 10:04:36 2017 -[error][/usr/share/perl5/vendor_perl/MHA/SSHCheck.pm, ln63]
Fri Feb 10 10:04:35 2017 - [debug] Connecting via SSH [email protected](10.192.203.201:22) [email protected](10.192.203.101:22)..
Warning: Permanently added '10.192.203.201'(RSA) to the list of known hosts.
Permission denied(publickey,gssapi-keyex,gssapi-with-mic,password).
Fri Feb 10 10:04:35 2017 -[error][/usr/share/perl5/vendor_perl/MHA/SSHCheck.pm, ln111] SSH connectionfrom [email protected](10.192.203.201:22) [email protected](10.192.203.101:22) failed!
Fri Feb 10 10:04:37 2017 - [debug]
Fri Feb 10 10:04:36 2017 - [debug] Connecting via SSH [email protected](10.192.203.101:22) [email protected](10.192.203.201:22)..
Fri Feb 10 10:04:36 2017 - [debug] ok.
Fri Feb 10 10:04:36 2017 - [debug] Connecting via SSH [email protected](10.192.203.101:22) [email protected](10.192.203.102:22)..
Fri Feb 10 10:04:37 2017 - [debug] ok.
Fri Feb 10 10:04:38 2017 - [debug]
Fri Feb 10 10:04:36 2017 - [debug] Connecting via SSH [email protected](10.192.203.102:22) [email protected](10.192.203.201:22)..
Fri Feb 10 10:04:37 2017 - [debug] ok.
Fri Feb 10 10:04:37 2017 - [debug] Connecting via SSH [email protected](10.192.203.102:22) to [email protected](10.192.203.101:22)..
Fri Feb 10 10:04:38 2017 - [debug] ok.
SSH Configuration Check Failed!
at/usr/bin/masterha_check_ssh line 44
需要检查下:
① /etc/hosts文件是否配置正确;
② 密码文件是否ssh-copy-id到了自身服务器。
假如遇到这个错误,修正后,将.ssh下的内容全部清空,然后重新认证即可。
7.2 检查mysql replication是否配置成功
[root@pc2 app1]# masterha_check_repl--conf=/etc/mha/app1.cnf
Fri Feb 10 11:25:05 2017 - [warning] Globalconfiguration file /etc/masterha_default.cnf not found. Skipping.
Fri Feb 10 11:25:05 2017 - [info] Readingapplication default configuration from /etc/mha/app1.cnf..
Fri Feb 10 11:25:05 2017 - [info] Readingserver configuration from /etc/mha/app1.cnf..
Fri Feb 10 11:25:05 2017 - [info]MHA::MasterMonitor version 0.56.
Fri Feb 10 11:25:06 2017 -[error][/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln193] There is noalive slave. We can't do failover
Fri Feb 10 11:25:06 2017 -[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln424] Errorhappened on checking configurations. at/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm line 326
Fri Feb 10 11:25:06 2017 -[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln523] Errorhappened on monitoring servers.
Fri Feb 10 11:25:06 2017 - [info] Got exitcode 1 (Not master dead).
MySQL Replication Health is NOT OK!
明明我检查了复制状态都是正常的,为什么通不过呢?
解决办法:
需要确保master和备选master设置为双主复制。即让master也指向备选master。
再次验证,假如报错:
[root@pc2 mysql]# masterha_check_repl --conf=/etc/mha/app1.cnf
Mon Feb 13 17:21:52 2017 - [info] Connecting [email protected](10.192.203.101:22)..
Checking slave recovery environment settings..
Opening /data/mysql/relay-log.info ... ok.
Relay log found at /data/mysql, up to slave1-relay-bin.000011
Temporary relay log file is /data/mysql/slave1-relay-bin.000011
Testing mysql connection and privileges..ERROR 1045 (28000): Accessdenied for user 'mha'@'slave1' (using password: YES)
mysql command failed with rc 1:0!
at/usr/bin/apply_diff_relay_logs line 375
main::check()called at /usr/bin/apply_diff_relay_logs line 497
eval{...} called at /usr/bin/apply_diff_relay_logs line 475
main::main()called at /usr/bin/apply_diff_relay_logs line 120
Mon Feb 13 17:21:53 2017 -[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln205] Slavessettings check failed!
Mon Feb 13 17:21:53 2017 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm,ln413] Slave configuration failed.
Mon Feb 13 17:21:53 2017 -[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln424] Errorhappened on checking configurations. at/usr/bin/masterha_check_repl line 48
Mon Feb 13 17:21:53 2017 -[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln523] Errorhappened on monitoring servers.
Mon Feb 13 17:21:53 2017 - [info] Got exitcode 1 (Not master dead).
MySQL Replication Health is NOT OK!
解决办法:
在slave1上创建用户:
mysql> grant ALL PRIVILEGES ON *.* TO 'mha'@'slave1'identified by 'test';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
同理,在PC上创建用户:
mysql> grant ALL PRIVILEGES ON *.* TO 'mha'@'PC' identifiedby 'test';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
再次验证时,假如报错:
Can't exec "mysqlbinlog": No suchfile or directory at /usr/share/perl5/vendor_perl/MHA/BinlogManager.pm line106.
mysqlbinlog version command failed with rc1:0, please verify PATH, LD_LIBRARY_PATH, and client options
解决办法:
在所有数据节点上都创建一下软连接:
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
再次验证,报错:
Testing mysql connection andprivileges..sh: mysql: command not found
mysql command failed with rc 127:0!
解决办法:
在所有数据节点上建立软连接:
ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
最后,一切正常:
[root@pc2 mysql]# masterha_check_repl --conf=/etc/mha/app1.cnf
Mon Feb 13 17:32:49 2017 - [warning] Globalconfiguration file /etc/masterha_default.cnf not found. Skipping.
Mon Feb 13 17:32:49 2017 - [info] Readingapplication default configuration from /etc/mha/app1.cnf..
Mon Feb 13 17:32:49 2017 - [info] Readingserver configuration from /etc/mha/app1.cnf..
Mon Feb 13 17:32:49 2017 - [info]MHA::MasterMonitor version 0.56.
Mon Feb 13 17:32:49 2017 - [info]Multi-master configuration is detected. Current primary(writable) master is10.192.203.201(10.192.203.201:3306)
Mon Feb 13 17:32:49 2017 - [info] Masterconfigurations are as below:
Master 10.192.203.101(10.192.203.101:3306),replicating from 10.192.203.201(10.192.203.201:3306), read-only
Master 10.192.203.201(10.192.203.201:3306),replicating from 10.192.203.101(10.192.203.101:3306)
Mon Feb 13 17:32:49 2017 - [info] GTID failovermode = 0
Mon Feb 13 17:32:49 2017 - [info] DeadServers:
Mon Feb 13 17:32:49 2017 - [info] AliveServers:
Mon Feb 13 17:32:49 2017 - [info] 10.192.203.201(10.192.203.201:3306)
Mon Feb 13 17:32:49 2017 - [info] 10.192.203.101(10.192.203.101:3306)
Mon Feb 13 17:32:49 2017 - [info] 10.192.203.102(10.192.203.102:3306)
Mon Feb 13 17:32:49 2017 - [info] AliveSlaves:
Mon Feb 13 17:32:49 2017 - [info] 10.192.203.101(10.192.203.101:3306) Version=5.5.19-log (oldest major versionbetween slaves) log-bin:enabled
Mon Feb 13 17:32:49 2017 - [info] Replicating from10.192.203.201(10.192.203.201:3306)
Mon Feb 13 17:32:49 2017 - [info] Primary candidate for the new Master(candidate_master is set)
Mon Feb 13 17:32:49 2017 - [info] 10.192.203.102(10.192.203.102:3306) Version=5.5.19-log (oldest major versionbetween slaves) log-bin:enabled
Mon Feb 13 17:32:49 2017 - [info] Replicating from10.192.203.201(10.192.203.201:3306)
Mon Feb 13 17:32:49 2017 - [info] CurrentAlive Master: 10.192.203.201(10.192.203.201:3306)
Mon Feb 13 17:32:49 2017 - [info] Checkingslave configurations..
Mon Feb 13 17:32:49 2017 - [info] Checkingreplication filtering settings..
Mon Feb 13 17:32:49 2017 - [info] binlog_do_db= , binlog_ignore_db=
Mon Feb 13 17:32:49 2017 - [info] Replication filtering check ok.
Mon Feb 13 17:32:49 2017 - [info] GTID(with auto-pos) is not supported
Mon Feb 13 17:32:49 2017 - [info] StartingSSH connection tests..
Mon Feb 13 17:32:51 2017 - [info] All SSHconnection tests passed successfully.
Mon Feb 13 17:32:51 2017 - [info] CheckingMHA Node version..
Mon Feb 13 17:32:52 2017 - [info] Version check ok.
Mon Feb 13 17:32:52 2017 - [info] CheckingSSH publickey authentication settings on the current master..
Mon Feb 13 17:32:52 2017 - [info]HealthCheck: SSH to 10.192.203.201 is reachable.
Mon Feb 13 17:32:52 2017 - [info] MasterMHA Node version is 0.56.
Mon Feb 13 17:32:52 2017 - [info] Checkingrecovery script configurations on 10.192.203.201(10.192.203.201:3306)..
Mon Feb 13 17:32:52 2017 - [info] Executing command: save_binary_logs--command=test --start_pos=4 --binlog_dir=/data/mysql--output_file=/var/tmp/save_binary_logs_test --manager_version=0.56--start_file=single-mysql-bin.000018
Mon Feb 13 17:32:52 2017 - [info] Connecting [email protected](10.192.203.201:22)..
Creating /var/tmp if not exists.. ok.
Checking output directory is accessible or not..
ok.
Binlog found at /data/mysql, up to single-mysql-bin.000018
Mon Feb 13 17:32:52 2017 - [info] Binlogsetting check done.
Mon Feb 13 17:32:52 2017 - [info] CheckingSSH publickey authentication and checking recovery script configurations on allalive slave servers..
Mon Feb 13 17:32:52 2017 - [info] Executing command : apply_diff_relay_logs--command=test --slave_user='mha' --slave_host=10.192.203.101--slave_ip=10.192.203.101 --slave_port=3306 --workdir=/var/tmp--target_version=5.5.19-log --manager_version=0.56--relay_log_info=/data/mysql/relay-log.info --relay_dir=/data/mysql/ --slave_pass=xxx
Mon Feb 13 17:32:52 2017 - [info] Connecting [email protected](10.192.203.101:22)..
Checking slave recovery environment settings..
Opening /data/mysql/relay-log.info ... ok.
Relay log found at /data/mysql, up to slave1-relay-bin.000011
Temporaryrelay log file is /data/mysql/slave1-relay-bin.000011
Testing mysql connection and privileges.. done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Mon Feb 13 17:32:52 2017 - [info] Executing command : apply_diff_relay_logs--command=test --slave_user='mha' --slave_host=10.192.203.102--slave_ip=10.192.203.102 --slave_port=3306 --workdir=/var/tmp--target_version=5.5.19-log --manager_version=0.56--relay_log_info=/data/mysql/relay-log.info --relay_dir=/data/mysql/ --slave_pass=xxx
Mon Feb 13 17:32:52 2017 - [info] Connecting [email protected](10.192.203.102:22)..
Checking slave recovery environment settings..
Opening /data/mysql/relay-log.info ... ok.
Relay log found at /data/mysql, up to PC-relay-bin.000011
Temporary relay log file is /data/mysql/PC-relay-bin.000011
Testing mysql connection and privileges.. done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Mon Feb 13 17:32:53 2017 - [info] Slavessettings check done.
Mon Feb 13 17:32:53 2017 - [info]
10.192.203.201(10.192.203.201:3306)(current master)
+--10.192.203.101(10.192.203.101:3306)
+--10.192.203.102(10.192.203.102:3306)
Mon Feb 13 17:32:53 2017 - [info] Checkingreplication health on 10.192.203.101..
Mon Feb 13 17:32:53 2017 - [info] ok.
Mon Feb 13 17:32:53 2017 - [info] Checkingreplication health on 10.192.203.102..
Mon Feb 13 17:32:53 2017 - [info] ok.
Mon Feb 13 17:32:53 2017 - [info] Checkingmaster_ip_failover_script status:
Mon Feb 13 17:32:53 2017 - [info] /usr/bin/master_ip_failover --command=status--ssh_user=root --orig_master_host=10.192.203.201--orig_master_ip=10.192.203.201 --orig_master_port=3306
IN SCRIPT TEST====/etc/init.d/keepalivedstop==/etc/init.d/keepalived start===
Checking the Status of the script.. OK
Mon Feb 13 17:32:53 2017 - [info] OK.
Mon Feb 13 17:32:53 2017 - [warning]shutdown_script is not defined.
Mon Feb 13 17:32:53 2017 - [info] Got exitcode 0 (Not master dead).
MySQL Replication Health is OK.
8 在管理端启动监控
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
#查看状态
masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:3349) is running(0:PING_OK),master:10.192.203.201
9 验证故障转移
在10.192.203.201上关闭Mysql实例:
[root@pc2mha]# service mysqld stop
Shutting downMySQL... SUCCESS!
在管理节点上查看日志:
tail -f /var/log/mha/app1/manager.log
会看到:
Started automated(non-interactive)failover.
Invalidated master IP address on10.192.203.201(10.192.203.201:3306)
The latest slave10.192.203.101(10.192.203.101:3306) has all relay logs for recovery.
Selected10.192.203.101(10.192.203.101:3306) as a new master.
10.192.203.101(10.192.203.101:3306): OK:Applying all logs succeeded.
10.192.203.101(10.192.203.101:3306): OK:Activated master IP address.
10.192.203.102(10.192.203.102:3306): Thishost has the latest relay log events.
Generating relay diff files from the latestslave succeeded.
10.192.203.102(10.192.203.102:3306): OK:Applying all logs succeeded. Slave started, replicating from10.192.203.101(10.192.203.101:3306)
10.192.203.101(10.192.203.101:3306):Resetting slave info succeeded.
Master failover to10.192.203.101(10.192.203.101:3306) completed successfully.
Mon Feb 13 17:44:28 2017 - [info] Sendingmail..
Unknown option: conf
也收到了报警邮件:
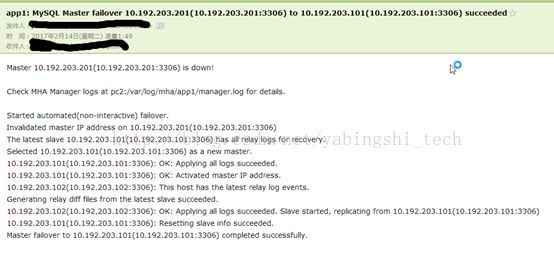
Vip也漂移过来了:
[root@slave1 mysql]# ip addr
1: lo: mtu16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen1000
link/ether 08:00:27:04:05:16 brd ff:ff:ff:ff:ff:ff
inet 10.192.203.101/24 brd 10.192.203.255 scope global eth0
inet 10.192.203.108/32 scope global eth0
inet6 fe80::a00:27ff:fe04:516/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
3: eth1: mtu 1500 qdisc pfifo_fast state UP qlen1000
link/ether 08:00:27:3a:ec:3c brd ff:ff:ff:ff:ff:ff
inet 10.0.10.5/24 brd 10.0.10.255 scope global eth1
inet6 fe80::a00:27ff:fe3a:ec3c/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
在PC上查看下slave状态:
mysql> show slave status \G;
*************************** 1. row***************************
Slave_IO_State: Waiting formaster to send event
Master_Host: 10.192.203.101
Master_User: rep_user
Master_Port: 3306
可以看到10.192.203.102复制自动指向了10.192.203.101了。
在现在的master上查看变量read_only,发现被自动关闭了,说明之前的slave现在可写了:
mysql> showvariables like 'read_only';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| read_only | OFF |
+---------------+-------+
1 row in set (0.01 sec)
切换完成后,manager进程会自动挂掉:
[root@pc2 mysql]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 is stopped(2:NOT_RUNNING).
mha配置文件被自己修改了(原主库的配置信息被删除掉了):
[root@pc2 mha]# cat app1.cnf
[server default]
manager_log=/var/log/mha/app1/manager.log
manager_workdir=/var/log/mha/app1.log
master_binlog_dir=/data/mysql
master_ip_failover_script=/usr/bin/master_ip_failover
master_ip_online_change_script=/usr/bin/master_ip_online_change
password=test
ping_interval=2
repl_password=beijing
repl_user=rep_user
report_script=/usr/bin/send_report
ssh_user=root
user=mha
[server2]
candidate_master=1
check_repl_delay=0
hostname=10.192.203.101
port=3306
[server3]
hostname=10.192.203.102
port=3306
现在的主库10.192.203.101上已经没有它原先的主从复制信息:
mysql> showslave status \G;
Empty set (0.00sec)
ERROR:
No queryspecified
接下来我们该做的事情:
① 找出主库挂到的原因,并修复之
② 确保原先的主库现在已追赶上现在的主库,并继续正确复制
③ 在现在的主库上change master to指向原来的主库开始复制,为将来故障切换做好准备。
④ 检查当前主从复制状态是否正常(masterha_check_repl--conf=/etc/mha/app1.cnf)
⑤ 启动原先主库keepalive进程
⑥ 确保原先主库配置文件(read_only设置为1,relay_log_purge=0)
⑦ 修改mha配置文件,将原先的主库信息重新加入
⑧ 启动manager进程,检查mha状态是否正常
10 在线切换
在许多情况下,需要将现有的主服务器迁移到另外一台服务器上。比如主服务器硬件故障,RAID 控制卡需要重建,将主服务器移到性能更好的服务器上等等。维护主服务器引起性能下降,导致停机时间至少无法写入数据。另外, 阻塞或杀掉当前运行的会话会导致主主之间数据不一致的问题发生。 MHA 提供快速切换和优雅的阻
塞写入,这个切换过程只需要 0.5-2s 的时间,这段时间内数据是无法写入的。在很多情况下,0.5-2s 的阻塞写入是可以接受的。因此切换主服务器不需要计划分配维护时间窗口。
MHA在线切换的大概过程:
(1)检测复制设置和确定当前主服务器
(2)确定新的主服务器
(3)阻塞写入到当前主服务器
(4)等待所有从服务器赶上复制
(5)授予写入到新的主服务器
(6)重新设置从服务器
假如现在我想从10.192.203.101切换回10.192.203.201,通过在线切换的方式完成。
10.1 停掉MHA监控
masterha_stop --conf=/etc/mha/app1.cnf
10.2 在线切换
[root@pc2 bin]# masterha_master_switch--conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=10.192.203.201--new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
Tue Feb 14 02:44:20 2017 - [info]MHA::MasterRotate version 0.56.
Tue Feb 14 02:44:20 2017 - [info] Startingonline master switch..
Tue Feb 14 02:44:20 2017 - [info]
Tue Feb 14 02:44:20 2017 - [info] * Phase1: Configuration Check Phase..
Tue Feb 14 02:44:20 2017 - [info]
Tue Feb 14 02:44:20 2017 - [warning] Globalconfiguration file /etc/masterha_default.cnf not found. Skipping.
Tue Feb 14 02:44:20 2017 - [info] Readingapplication default configuration from /etc/mha/app1.cnf..
Tue Feb 14 02:44:20 2017 - [info] Readingserver configuration from /etc/mha/app1.cnf..
Tue Feb 14 02:44:20 2017 - [info]Multi-master configuration is detected. Current primary(writable) master is10.192.203.101(10.192.203.101:3306)
Tue Feb 14 02:44:20 2017 - [info] Masterconfigurations are as below:
Master 10.192.203.101(10.192.203.101:3306),replicating from 10.192.203.201(10.192.203.201:3306)
Master 10.192.203.201(10.192.203.201:3306),replicating from 10.192.203.101(10.192.203.101:3306), read-only
Tue Feb 14 02:44:20 2017 - [info] GTIDfailover mode = 0
Tue Feb 14 02:44:20 2017 - [info] CurrentAlive Master: 10.192.203.101(10.192.203.101:3306)
Tue Feb 14 02:44:20 2017 - [info] AliveSlaves:
Tue Feb 14 02:44:20 2017 - [info] 10.192.203.201(10.192.203.201:3306) Version=5.5.19-log (oldest major versionbetween slaves) log-bin:enabled
Tue Feb 14 02:44:20 2017 - [info] Replicating from10.192.203.101(10.192.203.101:3306)
Tue Feb 14 02:44:20 2017 - [info] 10.192.203.102(10.192.203.102:3306) Version=5.5.19-log (oldest major versionbetween slaves) log-bin:enabled
Tue Feb 14 02:44:20 2017 - [info] Replicating from10.192.203.101(10.192.203.101:3306)
It is better to execute FLUSHNO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to executeon 10.192.203.101(10.192.203.101:3306)? (YES/no): yes
Tue Feb 14 02:45:03 2017 - [info] ExecutingFLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time..
Tue Feb 14 02:45:03 2017 - [info] ok.
Tue Feb 14 02:45:03 2017 - [info] CheckingMHA is not monitoring or doing failover..
Tue Feb 14 02:45:03 2017 - [info] Checkingreplication health on 10.192.203.201..
Tue Feb 14 02:45:03 2017 - [info] ok.
Tue Feb 14 02:45:03 2017 - [info] Checkingreplication health on 10.192.203.102..
Tue Feb 14 02:45:03 2017 - [info] ok.
Tue Feb 14 02:45:03 2017 - [info]10.192.203.201 can be new master.
Tue Feb 14 02:45:03 2017 - [info]
From:
10.192.203.101(10.192.203.101:3306)(current master)
+--10.192.203.201(10.192.203.201:3306)
+--10.192.203.102(10.192.203.102:3306)
To:
10.192.203.201(10.192.203.201:3306) (newmaster)
+--10.192.203.102(10.192.203.102:3306)
+--10.192.203.101(10.192.203.101:3306)
Starting master switch from10.192.203.101(10.192.203.101:3306) to 10.192.203.201(10.192.203.201:3306)?(yes/NO): yes
Tue Feb 14 02:45:09 2017 - [info] Checkingwhether 10.192.203.201(10.192.203.201:3306) is ok for the new master..
Tue Feb 14 02:45:09 2017 - [info] ok.
Tue Feb 14 02:45:09 2017 - [info] ** Phase1: Configuration Check Phase completed.
Tue Feb 14 02:45:09 2017 - [info]
Tue Feb 14 02:45:09 2017 - [info] * Phase2: Rejecting updates Phase..
Tue Feb 14 02:45:09 2017 - [info]
Tue Feb 14 02:45:09 2017 - [info] Executingmaster ip online change script to disable write on the current master:
Tue Feb 14 02:45:09 2017 - [info] /usr/bin/master_ip_online_change--command=stop --orig_master_host=10.192.203.101--orig_master_ip=10.192.203.101 --orig_master_port=3306--orig_master_user='mha' --orig_master_password='test'--new_master_host=10.192.203.201 --new_master_ip=10.192.203.201--new_master_port=3306 --new_master_user='mha' --new_master_password='test' --orig_master_ssh_user=root--new_master_ssh_user=root --orig_master_is_new_slave
Tue Feb 14 02:45:09 2017 728241 Setread_only on the new master.. ok.
Tue Feb 14 02:45:09 2017 733969 Drpping appuser on the orig master..
Tue Feb 14 02:45:09 2017 735861 Set read_only=1on the orig master.. ok.
Tue Feb 14 02:45:09 2017 739394 Killing allapplication threads..
Tue Feb 14 02:45:09 2017 739431 done.
SIOCSIFFLAGS: Cannot assign requestedaddress
Tue Feb 14 02:45:09 2017 - [info] ok.
Tue Feb 14 02:45:09 2017 - [info] Lockingall tables on the orig master to reject updates from everybody (includingroot):
Tue Feb 14 02:45:09 2017 - [info] ExecutingFLUSH TABLES WITH READ LOCK..
Tue Feb 14 02:45:09 2017 - [info] ok.
Tue Feb 14 02:45:09 2017 - [info] Origmaster binlog:pos is single-mysql-bin.000009:997.
Tue Feb 14 02:45:09 2017 - [info] Waiting to execute all relay logs on10.192.203.201(10.192.203.201:3306)..
Tue Feb 14 02:45:09 2017 - [info] master_pos_wait(single-mysql-bin.000009:997)completed on 10.192.203.201(10.192.203.201:3306). Executed 0 events.
Tue Feb 14 02:45:09 2017 - [info] done.
Tue Feb 14 02:45:09 2017 - [info] Gettingnew master's binlog name and position..
Tue Feb 14 02:45:09 2017 - [info] single-mysql-bin.000022:107
Tue Feb 14 02:45:09 2017 - [info] All other slaves should start replicationfrom here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.192.203.201',MASTER_PORT=3306, MASTER_LOG_FILE='single-mysql-bin.000022', MASTER_LOG_POS=107,MASTER_USER='rep_user', MASTER_PASSWORD='xxx';
Tue Feb 14 02:45:09 2017 - [info] Executingmaster ip online change script to allow write on the new master:
Tue Feb 14 02:45:09 2017 - [info] /usr/bin/master_ip_online_change--command=start --orig_master_host=10.192.203.101 --orig_master_ip=10.192.203.101--orig_master_port=3306 --orig_master_user='mha' --orig_master_password='test'--new_master_host=10.192.203.201 --new_master_ip=10.192.203.201--new_master_port=3306 --new_master_user='mha' --new_master_password='test'--orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave
Tue Feb 14 02:45:09 2017 946501 Setread_only=0 on the new master.
Tue Feb 14 02:45:09 2017 947009 Creatingapp user on the new master..
Tue Feb 14 02:45:10 2017 - [info] ok.
Tue Feb 14 02:45:10 2017 - [info]
Tue Feb 14 02:45:10 2017 - [info] *Switching slaves in parallel..
Tue Feb 14 02:45:10 2017 - [info]
Tue Feb 14 02:45:10 2017 - [info] -- Slaveswitch on host 10.192.203.102(10.192.203.102:3306) started, pid: 8353
Tue Feb 14 02:45:10 2017 - [info]
Tue Feb 14 02:45:10 2017 - [info] Logmessages from 10.192.203.102 ...
Tue Feb 14 02:45:10 2017 - [info]
Tue Feb 14 02:45:10 2017 - [info] Waiting to execute all relay logs on10.192.203.102(10.192.203.102:3306)..
Tue Feb 14 02:45:10 2017 - [info] master_pos_wait(single-mysql-bin.000009:997)completed on 10.192.203.102(10.192.203.102:3306). Executed 0 events.
Tue Feb 14 02:45:10 2017 - [info] done.
Tue Feb 14 02:45:10 2017 - [info] Resetting slave10.192.203.102(10.192.203.102:3306) and starting replication from the newmaster 10.192.203.201(10.192.203.201:3306)..
Tue Feb 14 02:45:10 2017 - [info] Executed CHANGE MASTER.
Tue Feb 14 02:45:10 2017 - [info] Slave started.
Tue Feb 14 02:45:10 2017 - [info] End oflog messages from 10.192.203.102 ...
Tue Feb 14 02:45:10 2017 - [info]
Tue Feb 14 02:45:10 2017 - [info] -- Slaveswitch on host 10.192.203.102(10.192.203.102:3306) succeeded.
Tue Feb 14 02:45:10 2017 - [info] Unlockingall tables on the orig master:
Tue Feb 14 02:45:10 2017 - [info] ExecutingUNLOCK TABLES..
Tue Feb 14 02:45:10 2017 - [info] ok.
Tue Feb 14 02:45:10 2017 - [info] Startingorig master as a new slave..
Tue Feb 14 02:45:10 2017 - [info] Resetting slave10.192.203.101(10.192.203.101:3306) and starting replication from the newmaster 10.192.203.201(10.192.203.201:3306)..
Tue Feb 14 02:45:10 2017 - [info] Executed CHANGE MASTER.
Tue Feb 14 02:45:10 2017 - [info] Slave started.
Tue Feb 14 02:45:10 2017 - [info] All newslave servers switched successfully.
Tue Feb 14 02:45:10 2017 - [info]
Tue Feb 14 02:45:10 2017 - [info] * Phase5: New master cleanup phase..
Tue Feb 14 02:45:10 2017 - [info]
Tue Feb 14 02:45:10 2017 - [info] 10.192.203.201: Resetting slave infosucceeded.
Tue Feb 14 02:45:10 2017 - [info] Switchingmaster to 10.192.203.201(10.192.203.201:3306) completed successfully.
中间需要手动输入两个yes。
10.3 检查是否切换成功
执行masterha_check_repl --conf=/etc/mha/app1.cnf验证下当前主从配置是否正确。
登录各从库,验证下现在复制是否已指向新的主库。
现在10.192.203.101, 10.192.203.102复制都指向10.192.203.201.
10.192.203.201上没有复制信息:
mysql> show slave status \G;
Empty set (0.00 sec)
ERROR:
No query specified
发现在线切换后有如下特点:
① :在线切换完成后,其他库复制都会指向现在的主库。现在的主库上原先的复制信息被清除
② :mha配置文件里原先主库的信息没有被删除。
③ :原先的主库自动变成只读,现在的主库自动变成可写。
④ :原来主库上的vip自动漂移到了现在的主库上。
10.4 后续操作
①:在线切换完成后,现在的主库仍然需要change master to原先的主库,然后开始复制。
② :启动原先主库的keepalive进程
③:启动mha监控
我发现当备用主库宕机后,假如主库也宕掉了,此时mha无法自动切换到其他slave上。错误日志:
Wed Feb 15 21:42:04 2017 -[error][/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln492] Server 10.192.203.101(10.192.203.101:3306) isdead, but must be alive! Check server settings.
Wed Feb 15 21:42:04 2017 -[error][/usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm, ln177] Got ERROR: at/usr/share/perl5/vendor_perl/MHA/MasterFailover.pm line 268
--本篇文章参考了:http://www.cnblogs.com/xuanzhi201111/p/4231412.html
--文章如有不当之处,欢迎指出!