DL4J中文文档/分布式深度学习/技术说明
DL4J分布式训练: 技术说明
本节将介绍DL4J的Apache Spark梯度共享训练实现的技术细节。关于参数平均实现的细节也有。注意,从1.0.0beta开始,参数平均实现已经被梯度共享实现所取代。本指南假定读者熟悉分布式训练中的关键概念,如数据并行和同步与异步SGD。这篇博客文章可以提供一个介绍。
- 异步SGD实现
- 参数平均实现
- 容错
异步SGD实现
DL4J的异步SGD实现基于Nikko Strom的Strom2015神经网络训练论文,并做了一些修改。下一节将回顾Strom论文的主要特性,然后介绍DL4J实现以及它与论文的不同之处。
Strom的方法
当在集群上训练神经网络时,工作机器需传递对其参数的改变。通过直接传递新的参数值(例如在参数平均中)或通过传递梯度/更新信息(如在梯度共享中)。
此方法的关键特征在于,与跨网络转达所有参数/更新相反,仅传送高于用户指定阈值的更新。换一种说法:我们从一个需要通信的更新向量(每个参数一个条目)开始。代替原样通信向量,我们仅以量化方式(它是稀疏二进制向量)通信大元素,而不是所有元素。这里的动机是减少所需的网络通信量——这种“稀疏、1位二进制编码”方法可以将通信更新所需的大小减少1000倍或更多——有关一些压缩统计信息,请参阅Strom的论文。
注意,低于阈值的更新不会被丢弃,而是累积在稍后要应用的“剩余”向量中。同样值得注意的是,缺少一个集中式参数服务器,它被对等通信所取代,如下图所示。
更新的向量, 上图中的δi,j 是:
- 稀疏:在每个向量δi,j中只传递一些梯度(其余的假设为0)-稀疏条目使用整数索引编码
- 量化为单个比特:稀疏更新向量的每个元素取值+τ 或 −τ。向量的所有元素的t值是相同的。因此只需要一个位来区分这两个选项。
- 整数索引(用于标识稀疏数组中的条目)可选地使用熵编码进行压缩,以进一步减小更新大小(作者以额外的计算为代价引用了进一步3倍的通信量缩减,然而这种好处可能比不上额外的开销)
异步SGD的主要问题之一是陈旧梯度问题。在Strom的方法中,不需要显式地处理陈旧梯度——在大多数情况下,更新在每个节点上应用非常快。论文报告网络传输减少了几个数量级。给定一个适当的计算密集型模型(如RNN或CNN),网络通信的急剧减少确保了模型在所有节点上相等,并且陈旧的梯度不是问题。
然而,这种方法无法规避下述的缺点:
- Strom报告说在训练的早期阶段可能会出现收敛问题(在一个epoch的一小部分使用较少的计算节点似乎是有帮助的)
- 压缩和量化不是免费的:这些过程导致每个小批量额外的计算时间和每个执行器的少量内存开销
- 该过程引入两个要考虑的额外超参数:阈值的值、τ以及是否使用熵编码进行更新(然而很显然,参数平均和异步SGD都引入额外的超参数)
DL4J的ASGD实现
DL4J 实现与Strom的方法有以下不同 :
- 非点对点:该实现允许用户选择两种网络组织模式——普通模式和网格模式。当集群中的节点数小于32个节点时,使用普通模式,对于较大的集群则使用网格模式。详情请参阅“不同模式”一节。
- 两种编码方案:DL4J使用两种编码方案,根据哪种方案将提供较少的网络通信,在这两种方案之间动态切换。有关详细信息,请参阅关于编码的章节。
- 调整量化阈值:根据每次迭代后的更新分布,将量化阈值提高或降低。这是在每个节点上独立完成的,以确保更新确实稀疏。实际上,这是通过ThresholdAlgorithm接口及其实现实现的。
- 如前所述的残差裁剪,更新的“残差”部分(即那些未通信的部分)存储在残差向量中。如果更新远远大于阈值,则可能出现我们称之为“残差爆炸”的现象——即,残差值可以继续增长到阈值的许多倍(因此将采取许多步骤来传递梯度)。为了避免这种情况,DL4J具有一个ResidualPostProcessor接口,默认实现是ResidualClippingPostProcessor,每5步将残差向量裁剪到当前阈值的最大5倍。
- 通过ParallelWrapper实现的本地并行:这使得多CPU/GPU节点能够更快地共享信息
从描述中可以看出,ASGD的实现需要在每次迭代训练时进行更新传播。集群内的工作机之间的进一步通信是网格模式的要求。
为了使spark通信快速脱离,DL4J使用了Aeron。Aeron是一种高性能的消息传递系统,可以在UDP、无限带宽或共享内存上运行。Aeron被设计成最高吞吐量并且最低和最可预测的延迟的任何可能的消息系统。在Aeron之上构建我们自己的通信栈允许我们使用Spark集成参数服务器的自定义实现,同时控制和最小化线路的分配权。
普通模式VS网格模式
DL4J的梯度共享实现可以通过两种方式来配置,这取决于集群大小。
下面是一个描述普通模式如何组织的图片:
在普通模式下,量化编码更新由每个节点转达到主节点,然后主节点转达到其余节点。这确保了主节点始终具有模型的最新版本,这是容错所必需的。然而,主节点在这个实现中是一个潜在的瓶颈。为了扩展到更大的集群(超过大约32个节点——尽管这是网络和硬件指定的),使用网格模式,如下所述。
下面是描述网格模式如何组织的图像:

网络模式是一个非二进制树,spark主节点是它的根。默认情况下,每个节点最多可以有8个节点,树最多可以有5层深。在网格模式下,每个节点将编码的更新转达到连接到它的所有节点,并且每个节点聚合从连接到它的所有其他节点接收的更新。在网格模式下,由于直接接收的通信量减少,主节点不再是瓶颈。在编写本文档时,已经用单播和多播(1.0.0-beta3中提供)测试了实现。未来的支持计划为RDMA。
编码方案
使用以下两种方案中的一种来发送更新。
- 阈值编码:发送一个整数数组,每个整数组都引用参数的索引。对于正阈值发送正整数,对于负阈值发送负整数。
- 位图编码:每个参数更新用两个比特编码。这四种状态用于指示没有变化,a +ve阈值变化,a -ve阈值变化以及+ve和-ve之间循环的半阈值变化。
使用这两种编码方案可以适应更新密集的情况。因为每个节点都有自己的阈值,它的值也与每个传输进行通信。为了实现性能和GPU并行化,将编码更新推到优化的本机代码(C++)。稀疏阈值(整数索引)编码可以导致非常高的压缩率,而位图编码导致固定大小的16倍压缩比(即,对于原始更新向量,每个参数2比特,相对于32比特)。
参数平均实现
参数平均实现是DL4J中第一个分布式训练实现,它已经被上一节描述的梯度共享实现所取代。为了完整起见,这里包括了关于参数平均实现的细节。
参数平均实现是一种完全在Spark中实现的同步SGD方法。DL4J的参数平均实现使用单个参数服务器,一个由Spark主节点服务的角色。
参数平均是概念上最简单的数据并行方法。它要求用户指定工作机彼此之间和与主节点同步的频率。通过参数平均,训练进行如下:
- 主机(Spark驱动程序)从初始网络配置和参数开始
- 基于TrainingMaster的配置,数据被分成多个子集。
- 对数据拆分进行迭代。对于训练数据的每个分割:a.将配置、参数(以及如果适用的话,用于momentum/rmsprop/adagrad的网络更新器状态)从主节点分配给每个工作机 b.使每个工作机拟合其分割的部分 c.平均参数(以及如果适用的话,更新器状态)并且返回平均结果到主节点。
- 训练完成后,主节点有一个已训练网络的拷贝。
在下面的图像中演示了步骤3a到3c。在这个图中,W表示神经网络的参数(权重、偏置)。订阅用于对参数的版本进行索引,并在必要时对每个工作机器进行索引。
该实现在后台使用Spark的树状聚集。可以对这个实现进行许多增强,这将导致更快的训练时间。即使有了这些增强,具有量化压缩更新的异步SGD方法预计将持续快得多。因此,强烈建议用户从参数平均实现切换到异步SGD梯度共享方法。
容错
DL4J中分布式训练的Spark实现在1.0.0-beta3中具有容错性。参数平均实现始终是容错的;梯度共享实现是在(不包括)1.0.0-beta2之后完全容错的。
在深入了解实现的细节之前,让我们首先考虑当节点出现故障时会发生什么。由于Spark对通过Aeron发送的更新没有感知,RDD谱系回溯到初始参数和优化器状态。当Spark恢复一个节点来代替故障节点时,它将因此从初始状态恢复训练。换句话说,这个恢复的节点将与其他节点不同步,这将导致训练偏离。
DL4J的梯度共享利用Spark之外的其自身的内部心跳机制来检测节点何时出现故障,以及检测恢复的节点何时联机。为了确保训练持续而不偏离,需要恢复节点,使用与当前点处的其他节点相同的模型副本来恢复训练。为了确保更新不会被多次应用,每个更新都用唯一的ID进行标记。更新器/优化器(RMSProp、AdaGrad等)的状态以及迭代/周期号也要求 网络训练从节点故障之前的状态开始。
以下概述当节点在普通模式下出现故障并恢复时发生的情况:
- 还原的节点重新连接到主节点。
- 恢复的节点开始接收更新,然后发送对参数、更新器状态和当前epoch/迭代的请求。
- 主节点实现这些请求(由其本身或代理)
- 恢复的节点仅应用相关的更新(相对于参数向量)
- 继续训练新节点上的RDD数据,与其他节点适当同步并适当收敛
在节点开始接收更新之后,请求模型的副本可以确保不错过更新。更新由唯一的ID标记,并且不会两次错误应用更新。由于主节点不执行任何训练,因此它不保持更新器状态,当它接收到对更新器/优化器状态的请求时,它向其他节点之一发送请求——在接收到请求时,它向恢复的节点发送更新器。
当节点失败时,网格节点中唯一的附加步骤是重新映射失败节点的子节点。在这种情况下,失败节点的子节点被映射到主节点并且所有剩余的子节点都被映射到主节点的一个映射。
具体来说,如果节点2失败,则使用下面的树结构,将节点5映射到主节点,将节点6和7映射到节点5。
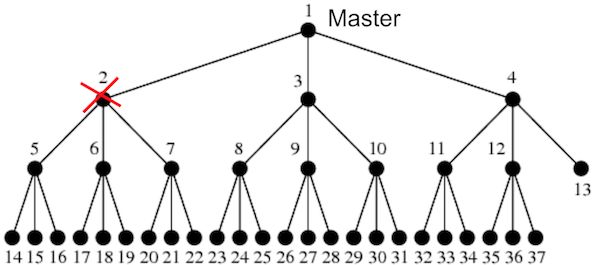
之所以决定重新映射到主节点而不是相邻节点,是因为假定主节点是最可靠的选项。由于同样的原因,向主节点请求模型副本等也是如此。需要注意的是,类似于Spark作业,使用DL4J的分布式神经网络训练不能承受主节点故障。因此,建议用户频繁地保持模型的状态。在这种情况下,如果主控程序失败,则可以从最新的保存状态重新启动训练。
容错限制:梯度共享实现的容错有两个主要限制。第一:少量数据(几个小批量)可以多次处理。这是因为失败的节点可能在失败之前处理分区的一部分(发送更新)。在实践中这不是一个问题:重复的小批量通常很少,而且我们通常要进行多个epoch的训练(因此在训练期间已经多次看到每个示例)。第二:主/驱动节点是单点故障。这实质上是Spark限制:DL4J可以(原则上)实现从失败的主节点恢复并继续训练的功能,但是Apache Spark不支持主节点的容错。