【综述】NL2SQL (二) WikiSQL
目录
一. WikiSQL数据集
二. 效果一览
三. 论文简述
1. Seq2sql: Generating structured queries from natural language using reinforcement learning
2. Pointing Out SQL Queries From Text
3. SQLNet: Generating Structured Queries from Natural Language without Reinforcement Learning
4. Bidirectional Attention for SQL Generation
5. Natural Language to Structured Query Generation via Meta-Learning
6. TypeSQL: Knowledge-based Type-Aware Neural Text-to-SQL Generation
7. Coarse-to-Fine Decoding for Neural Semantic Parsing
8. A Transfer-Learnable Natural Language Interface for Databases
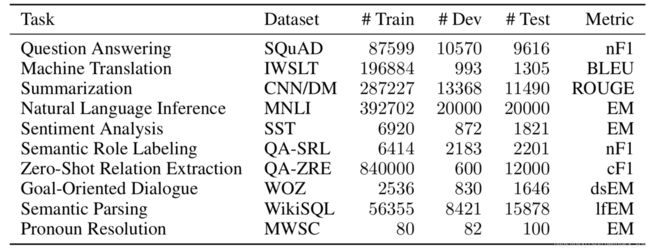
9. The Natural Language Decathlon: Multitask Learning as Question Answering
10. IncSQL: Training Incremental Text-To-SQL Parsers With Non-Deterministic Oracles
11. Robust Text-to-SQL Generation with Execution-Guided Decoding
12. A Comprehensive Exploration on WikiSQL with Table-Aware Word Contextualization
13. X-SQL: Reinforce Schema Representation With Context
四、小结
一. WikiSQL数据集
WikiSQL数据集包括80654个人工标注的问题和SQL查询示例,来自于wikipedia中的24241个表,样例如下图:

WikiSQL的问题长度8~15个词居多,查询长度8~11个词居多,表的列数5~7个居多,另外,大多数问题是what类型,其次是which、name、how many、who等类型。


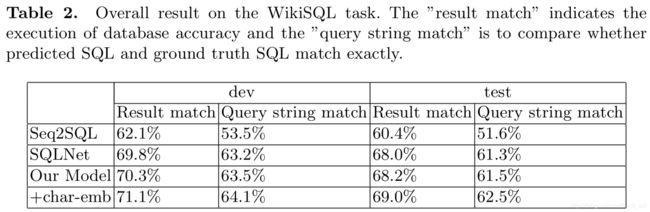
二. 效果一览
WikiSQL数据集于2017年在Seq2SQL这篇论文中提出,当时的baseline和提出模型结果分别为35.9%和59.4%,目前最新成绩为91.8%,进展飞速。
从机构上来看,较多来自Salesforce、华盛顿大学、微软、斯坦福大学等。从方法上来看,从最开始简单的seq2seq模型,逐渐发展到多任务、迁移学习、以及基于BERT和MT-DNN预训练的模型。
| 模型(作者和年份) |
Dev logical form Acc | Dev query match Acc | Dev execution Acc | Test logical form Acc | Test query match Acc | Test execution Acc | 单位 | 备注 |
| Baseline (Victor Zhong, 2017) | 23.3 | - | 37 | 23.4 | - | 35.9 | Salesforce | 公开数据集+强化学习 |
| Seq2SQL (Victor Zhong, 2017) | 49.5 | - | 60.8 | 48.3 | - | 59.4 | - | - |
| Pointer-SQL(Chenglong Wang, 2017) | 59.6 | - | 65.2 | 59.5 | - | 65.1 | 华盛顿大学、微软 | 监督的深层seq2seq模型 |
| SQLNet (Xiaojun Xu, 2017) | - | 63.2 | 69.8 | - | 61.3 | 68.0 | 上海交通大学、加州大学伯克利分校 | 基于草图+序列到集合 |
| BI-Attention(Tong Guo, 2018) | - | 64.1 | 71.1 | - | 62.5 | 69.0 | 联想AI实验室、中国电科集团信息研究院 | Bi-attention |
| PT-MAML (Po-Sen Huang, 2018) | 63.1 | - | 68.3 | 62.8 | - | 68.0 | 微软、华盛顿大学、艾伦人工智能研究院、京东 | 元学习 |
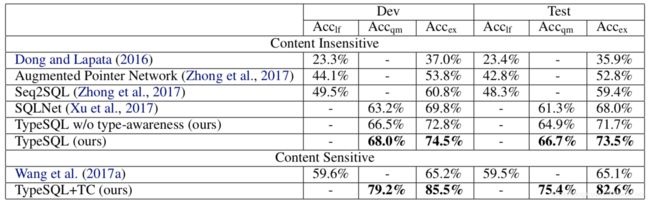
| TypeSQL (Tao Yu, 2018) | - | 68 | 74.5 | - | 66.7 | 73.5 | 耶鲁大学 | 利用类型信息 |
| TypeSQL + TC (Tao Yu, 2018) | - | 79.2 | 85.5 | - | 75.4 | 82.6 | - | TC表示对数据库的完全访问 |
| Coarse2Fine (Li Dong, 2018) | - | - | - | 71.7 | - | 78.5 | 爱丁堡大学 | 先草图再SQL |
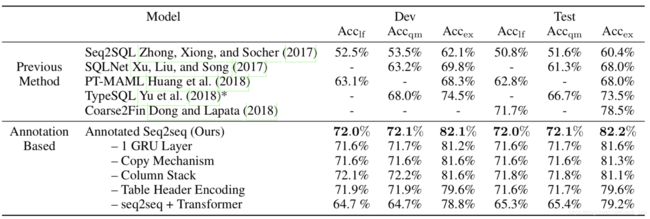
| Annotated Seq2seq (Wenlu Wang, 2018) | 72.0 | 72.1 | 82.1 | 72.0 | 72.1 | 82.2 | 奥本大学、石溪大学、斯坦福大学、WeWork | 迁移学习+自动注释机制 |
| MQAN (Bryan McCann, 2018) | - | - | - | 72.4 | - | 80.4 | Salesforce | 多任务问答网络 |
| IncSQL (Tianze Shi, 2018) | 49.9 | - | 84.0 | 49.9 | - | 83.7 | 康内尔大学、斯坦福大学、微软 | 非确定性预言机+序列到动作模型 |
| IncSQL + EG(5) (Tianze Shi, 2018) | 51.3 | - | 87.2 | 51.1 | - | 87.1 | - | - |
| Execution-Guided Decoding (Chenglong Wang, 2018) | 76.0 | - | 84 | 75.4 | - | 83.8 | 华盛顿大学、斯坦福大学、微软、谷歌大脑 | EG |
| SQLova (Wonseok Hwang, 2019) | 81.6 | - | 87.2 | 80.7 | - | 86.2 | 韩国公司 Clova AI, NAVER Corp | 基于BERT预训练 |
| SQLova + EG (Wonseok Hwang, 2019) | 84.2 | - | 90.2 | 83.6 | - | 89.6 | - | - |
| X-SQL (Pengcheng He, 2019) | 83.8 | - | 89.5 | 83.3 | - | 88.7 | 微软 | shema增强+基于MT-DNN预训练 |
| X-SQL + EG (Pengcheng He, 2019) | 86.2 | - | 92.3 | 86.0 | - | 91.8 | - | - |
三. 论文简述
1. Seq2sql: Generating structured queries from natural language using reinforcement learning
Victor Zhong, Caiming Xiong, and Richard Socher, 2017
本文来自Salesforce。
摘要:关系数据库存储大量的世界数据。但是,当前访问这些数据需要用户理解一种查询语言,比如SQL。我们提出了一种用于将自然语言问题转化为相应的SQL查询的深层神经网络Seq2SQL。我们的模型使用在数据库中循环查询执行的奖励来学习生成查询的策略,该策略包含不太适合通过交叉熵损失进行优化的无序部分。此外,seq2sql利用sql的结构来修剪生成查询的空间,并大大简化生成问题。除了这个模型之外,我们还发布了wikisql,一个由80654个手工标注的问题和sql查询示例组成的数据集,它分布在wikipedia的24241个表中,比可比较的数据集大一个数量级。通过将基于策略的强化学习和查询执行环境应用到WikiSQL中,Seq2SQL优于最先进的语义解析器,执行准确率从35.9%提高到59.4%,逻辑形式准确率从23.4%提高到48.3%。
1. Augmented pointer network
Pointer nerwork的特点是输出序列中的token是从输入序列token中选取出来的。本文的输入序列是将表格的列名、SQL词典、问题拼接起来形成的。其中SQL的词典包括select、where、count、min、max等固定词汇。
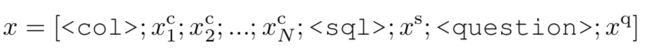
2. Seq2SQL
模型包括3个组件:(1)聚合分类器:选择聚合类型,比如sum、count等,也可以没有为null;(2)select列的pointer:采用pointer network选择要查询的列;(3)where条件解码器:采用pointer network选择语句。

如果直接用pointer network解码得到Where语句会存在一个问题,where语句中多个条件之间是没有顺序的,不同的顺序实质上是等价的。因此,本文提出用强化学习来学习策略以生存执行正确的查询语句。强化学习的奖励通过执行查询的结果来获得,设置如下:

3. 实验结果
评价指标为执行准确率Acc-ex和逻辑形式准确率Acc-lf,前者根据执行查询得到的结果来评价,后者根据sql语句的形式来评价,因此执行准确率更高一些,因为有些查询的形式跟groundtruth可能不一样,但是执行结果是一样的。

2. Pointing Out SQL Queries From Text
Chenglong Wang,Marc Brockschmidt & Rishabh Singh, 2017
本文来自华盛顿大学和微软。
摘要:数据的数字化导致以关系数据库和电子表格的形式向数百万用户提供数据集。但是,这些用户中的大多数来自不同的背景,并且缺乏查询和分析此类表的编程知识。我们提出了一种系统,该系统允许使用自然语言问题查询数据表,该系统将问题转换为可执行的SQL查询。我们使用一个深层序列到序列的模型,它的解码器使用简单的SQL表达式类型系统来构造输出预测。根据类型,解码器或者使用基于注意力的复制机制从输入问题中复制输出令牌,或者从固定词汇表中生成输出令牌。我们还引入了基于值的损失函数,该函数将要复制的位置分布转换为输入令牌集的分布,以改善模型的训练。我们在最近发布的WikiSQL数据集上评估了我们的模型,并表明我们仅使用监督学习进行训练的模型就大大优于当前使用强化学习的最新Seq2SQL模型。
1. 模型介绍
模型结构包括两个部分,首先是编码器:输入为表头和用户query拼接起来,采用双向LSTM来编码,如下图前半部分。

其次是类型解码器:首先将输出的sql语法规范化为标准模式,如下图。解码过程生成的词可以分为三种情况:第一种是sql术语,包括select, from, where, id, max, min, count, sum, avg, and, =, >, >=, <, <=,
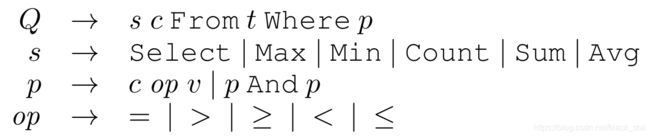
2. 实验结果
采用精准的语法匹配准确率和执行准确率来评价。

3. SQLNet: Generating Structured Queries from Natural Language without Reinforcement Learning
Xiaojun Xu, Chang Liu, Dawn Song,2017
本文来自上海交通大学、加州大学伯克利分校。
摘要:从自然语言合成SQL查询是一个长期存在的开放问题,并且最近引起了极大的兴趣。为了解决该问题,实际中的方法是采用序列到序列样式的模型。这种方法必然要求将SQL查询序列化。由于同一个SQL查询可能具有多个等效的序列化,因此训练序列到序列样式的模型对从其中之一进行选择很敏感,该现象被记录为“订单事项”问题。现有的最新方法依赖于强化学习来在解码器生成任何等效序列化时对解码器进行奖励,但是,我们观察到强化学习的改进是有限的。在本文中,我们提出了一种新颖的方法,即SQLNet,通过在顺序无关紧要时避免使用序列到序列的结构来从根本上解决此问题。具体地,我们采用了一种基于草图的方法,其中草图包含一个依赖图,因此可以通过仅考虑其依赖的先前预测来进行下一个预测。此外,我们提出了一个序列到集合以及列关注机制来基于草图合成查询。通过结合所有这些新颖的技术,我们证明SQLNet在WikiSQL任务上可以比现有技术高9%到13%。
1. 基于草图的查询合成
首先将query查询规范为标准形式,如下图(a)所示,其中黑色粗体表示SQL关键字,$AGG表示聚合类型(比如:SUM、MAX等),$COLUMN表示表的列名,$VALUE必须来自输入自然语言的子串,$OP表示比较符号(比如:=、<、>),结尾的*表示括号内的片段可以重复0或多次。它们的依赖关系参考图(b)。

2. 序列到集合的预测
WHERE语句预测时,先采用序列到集合的方式,预测表的哪些列应该出现,然后针对每个出现的列,预测运算符和取值,如上图(b)所示。具体地,预测列时采用sigmoid函数来计算每个列出现的概率,并采用列注意力来提高预测能力。一般的,我们可以设置一个阈值,当列出现的概率超过阈值时就输出该列,但是本文采用了另外一种方法,即先预测出WHERE语句中列的数量K,然后取top-K的列,我们发现这样效果更好。紧接着,我们预测运算符,这是一个三分类的问题(=、>、<)。最后预测取值,我们采用序列到序列的方法,从自然语言中提取出来。
SELECT语句预测时,预测聚合函数和列都是分类问题。
3. 实验结果
除了逻辑形式准确率、执行准确率之外增加了查询匹配准确率,它的含义是将合成的查询SQL和ground truth的查询SQL转换成标准形式,看看是否精确匹配,这个可以避免顺序带来的false negatives。

4. Bidirectional Attention for SQL Generation
Tong Guo, Huilin Gao, 2018
本文来自联想AI实验室、中国电科集团信息研究院。
摘要:从自然语言生成结构化查询语言(SQL)查询是一个长期存在的开放问题。 要回答有关数据库表的自然语言问题,就需要对表的列与问题之间的复杂交互进行建模。 在本文中,我们采用合成方法来解决此问题。 基于SQL查询的结构,我们将模型分为三个子模块,并为每个子模块设计特定的深度神经网络。 从类似的机器阅读任务中汲取灵感,我们采用了双向注意力机制和卷积神经网络(CNN)进行字符级嵌入来改善结果。 实验评估表明,我们的模型在WikiSQL数据集中获得了最新的结果。
1. 模型介绍
模型总体结构如下,分为三个模块:aggregator-select module(左上), column-select module(中上), where module(右上)。采用Glove获取字符级的词嵌入,问题和column经过BILSTM后再通过bi-attention在进行最终的映射。

2. 实验结果
实验结果如下,执行准确率提升到69.0%。
5. Natural Language to Structured Query Generation via Meta-Learning
Po-Sen Huang, Chenglong Wang, Rishabh Singh, Wen-tau Yih, Xiaodong He, 2018
本文来自微软、华盛顿大学、艾伦人工智能研究院、京东。
摘要:在常规的监督训练中,模型被训练以适合所有训练样本。 但是,整体一致的模型可能并不总是最好的策略,因为样本可能会千差万别。 在这项工作中,我们借助于域依赖的相关函数,通过将原始学习问题简化为few-shot元学习场景,展示了一种将每个样本视为唯一伪任务的不同学习协议。在WikiSQL数据集上进行评估时,我们的方法可加快收敛速度,并且与非元学习方法相比,可以实现1.1%–5.4%的绝对准确度提升。
1. 模型介绍
训练阶段,每个样本被当做一个不同任务的测试样本,这个任务的训练数据是与该样本相关的top-K样本,由此我们得到一个通用的模型;测试阶段,用同样的方法获取测试样本相关的top-K样本,利用这些样本更新通用模型,然后再进行预测。框架如下图。

2. 实验结果
执行准确率最高为采用sum loss达到68.0%。

6. TypeSQL: Knowledge-based Type-Aware Neural Text-to-SQL Generation
Tao Yu,Zifan Li,Zilin Zhang,2018
本文来自耶鲁大学。
摘要:通过自然语言与关系数据库进行交互可帮助任何背景的用户轻松查询和分析大量数据。 这需要一个能够理解用户问题并将其自动转换为SQL查询的系统。 在本文中,我们提出了一种新颖的方法TYPESQL,它将此问题视为插槽填充任务。 另外,TYPESQL利用类型信息更好地理解自然语言问题中的稀有实体和数字。 我们在WikiSQL数据集上测试了此想法,并在更短的时间内将其性能提高了5.5%。 我们还表明,当用户的查询格式不正确时,访问数据库的内容可以显着提高性能。 TYPESQL的准确度达到82.6%,与以前的内容敏感模型相比,绝对提高了17.5%。
1. 模型介绍
输入预处理-类型识别:识别的类型包括数字类(整数、浮点、日期、年份),实体类(人名、地名、国家、结构、体育,基于Freebase的数据利用grams和关键词查询)、表的列明。参考图中最下面的type,每个词都会对应一个类型。
输入编码器:包含两个BI-LSTM,一个是输入query+type的编码器(左下方),另一个是表的列名的编码器(左上方)。
槽填充模型:包含三个模型(右侧),(1)Model_col:预测select的列、条件的数量、条件的列;(2)Model_agg:预测聚合函数;(3)Model_opval:预测运算符、条件的取值。
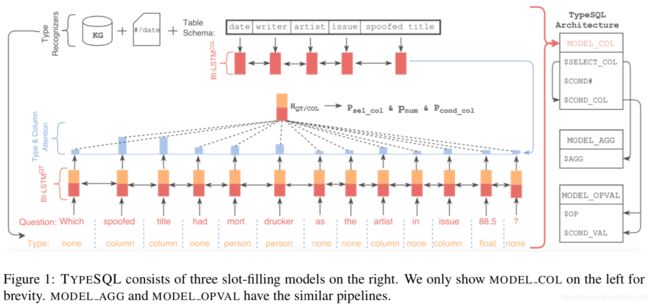
2. 实验结果
表中上部分为内容不敏感的结果,即没有利用数据库的内容,下部分则利用了数据库的内容。执行准确率从SQLNet的68.0%提升到73.5%。另外可以看到,如果可以获取数据库内容的话,效果提升非常明显。
7. Coarse-to-Fine Decoding for Neural Semantic Parsing
Li Dong and Mirella Lapata, 2018
本文来自爱丁堡大学。
摘要:语义解析旨在将自然语言映射为结构化的表示。本文中,我们提出了一种结构感知的神经体系结构,该结构将语义解析过程分解为两个阶段。 首先,给定输入的句子,生成其含义的粗略草图,它会掩盖低级信息(例如变量名和参数), 然后,通过考虑自然语言和草图本身来填充缺失的细节。 在四个不同域和含义表示的数据集上的实验结果表明,尽管使用了相对简单的解码器,但我们的方法始终如一地提高了性能,获得了有竞争力的结果。
1. 草图定义
在输入自然语言x和输出语义表示y之间增加了草图a,可以用于多个场景,比如数据库查询、代码生成、自然语言转SQL等。这里就需要一种从自然语言生成草图的方法。

2. 模型介绍
模型框架如下:输入自然语言x,编码后解码得到草图a,然后接着编码再解码得到语义表示输出。

3. 自然语言转SQL
上述框架在应用到NL2SQL是,编码时需要感知表格,实现方式如下:

SQL语句的生成包括:(1)select语句生成,采用分类;(2)where语句生成,如下图,从编码得到的表述出发,先进行一个分类得到草图(模型是有限的),然后基于运算符解码得到条件的列名,接着将解码的列名作为解码器的输入,继续解码得到预算符的取值,然后继续解码得到AND,再之后是解码下一个条件语句,直到结束。
4. 实验结果
这里我们只关注WikiSQL上的实验结果,本文将执行准确率提高到了78.5%。

8. A Transfer-Learnable Natural Language Interface for Databases
Wenlu Wang, Yingtao Tian, Hongyu Xiong, Haixun Wang, Wei-Shinn Ku, 2018
本文来自奥本大学、石溪大学、斯坦福大学、WeWork。
摘要:关系数据库管理系统(RDBMS)功能强大,因为它们能够优化和回答针对任何关系数据库的查询。另一方面,针对数据库的自然语言界面(NLI)是为具体数据库量身定制的。本文中,我们介绍了一种通用的可转移学习的NLI,其目标是学习一种可用作任何关系数据库的NLI的模型。我们采用分离数据及其模式的数据管理原理,但对自然语言的特质和复杂性提供了额外的支持。具体来说,我们引入了一种自动注释机制,该机制将模式和数据分开,其中模式还涵盖了有关自然语言的知识。此外,我们提出了一个定制的序列模型,该模型可将带注释的自然语言查询转换为SQL语句。我们在实验中表明,我们的方法优于WikiSQL数据集上的以前的NLI方法,并且我们学习到的模型无需重新训练即可应用于另一个基准数据集OVERNIGHT。
1. 模型介绍
本文提出annotated question和annotated sql的概念,示例如下图,基本思想是对于问题和SQL中的片段打上语义标签,利用语义标签来将问题转化成sql。

模型结构如下图,分为三个部分:第一步将自然语言的问题q转化为注释的形式得到qa;第二步利用seq2seq模型将qa翻译为sql的注释形式sa;第三步将sq转化为标准的sql语句s。其中,关键点在于第一步和第二步。

第一步的问题注释是比较关键并且具有挑战的一个步骤,难点在于:(1)问题中的片段很难跟表头精确对应上,比如问题是who is the best actress of year 2011,表头是best actor 2011;(2)字面完全不相同,比如问题是Which film directed by Jerzy Antczak did Piotr Adamczyk star in,表头是actor;(3)依赖问题的语法结构,比如问题是For which player his rebounds is 2 and points is 3,“2”和“3”的标签依赖于语法分析。
为了解决这个问题,我们需要用到更多的知识,包括:数据库的schema(包括表的表头),数据库每列的统计特性(每列都是什么内容,比如可以用语言模型来判断给定token属于某列的概率),关于数据库、列、取值的一些自然语言表述(比如:population of 〈city〉, size of 〈city〉, how many people live in 〈city〉, ...)。实现上,我们先进行mention检测,方法包括字符串的覆盖情况、编辑距离、embedding相似性,语法树等,然后进行mention消歧,内容包括最小公共祖先、最大二部图匹配等。
第二步我们将注释作为额外的符号增加进问题字符串中,并把表头也放进去,用seq2seq来实现编码解码。
2. 实验结果
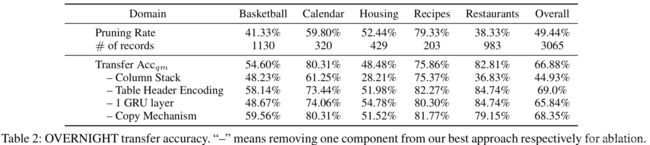
我们的结果执行准确率达到了历史新高82.2%,并且将该模型迁移到其他子领域也取得了较好的结果。
9. The Natural Language Decathlon: Multitask Learning as Question Answering
Bryan McCann, Nitish Shirish Keskar, Caiming Xiong, Richard Socher,2018
本文来自Salesforce。
摘要:深度学习提高了许多自然语言处理(NLP)任务的性能。但是,通用的NLP模型不能仅关注某个特定的度量、数据集和任务。我们介绍了自然语言十项全能(decaNLP),这项挑战涵盖了十项任务:问答,机器翻译,摘要,自然语言推断,情感分析,语义角色标签,关系提取,面向目标的对话,语义解析和常识代词解析。我们将所有任务都作为上下文的问题回答。此外,我们提出了一个新的多任务问答网络(MQAN),该网络可以联合学习decaNLP中的所有任务,而无需任何特定于任务的模块或参数。 MQAN展示出在机器翻译和命名实体识别的迁移学习上有提升,在情感分析和自然语言推断上具有领域适应性,在文本分类上具有zero-shot的能力。我们证明MQAN的多指针生成器解码器是成功的关键,并且通过反课程训练策略可以进一步提高性能。尽管是为decaNLP设计的,但MQAN还在单任务设置中的WikiSQL语义解析任务上获得了最先进的结果。我们还公开了代码,包括采购和处理数据、训练和评估模型以及为decaNLP复制所有实验。
1. 任务列表
所有的问题都建模为问答,给定上下文context和当前查询query,输出答案answer。
2. 模型介绍
模型结构如下图,编码器部分,首先是问题和上下文分别有独立的编码器,采用BILSTM,然后两者经过对齐模型,在通过对偶的注意力得到表示,并在此通过一个BILSTM对进行压缩,接着是自注意力机制得到表示,最后再通过BILSTM得到最终的编码表示。
解码部分,除了问题表述之外,重点注意它的pointer,一个是问题的pointer,另一个是context的pointer。
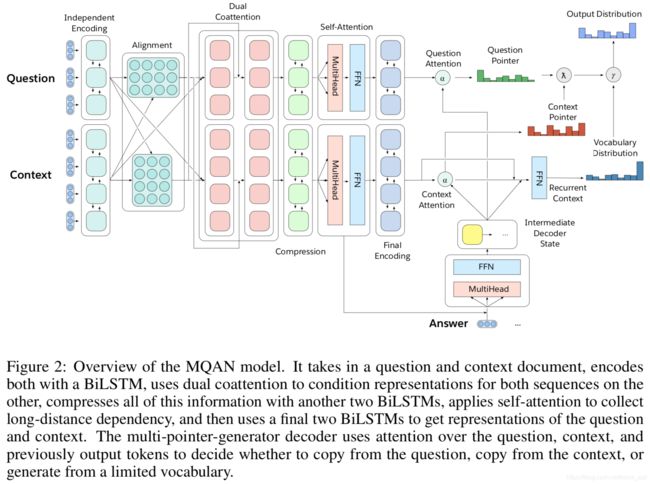
不同的任务在生成答案选择词的时候倾向不同,比如阅读理解倾向于从context中选择,翻译倾向于从目标词典中选择,情感分析倾向于从问题中选择。

3. 实验效果
WikiSQL的逻辑形式准确率也达到了soa的效果72.4%。

10. IncSQL: Training Incremental Text-To-SQL Parsers With Non-Deterministic Oracles
Tianze Shi, Kedar Tatwawadi, Chakrabarti, Yi Mao, Oleksandr Polozov, and Weizhu Chen, 2018
本来来自康内尔大学、斯坦福大学、微软。
摘要:我们为NL2SQL任务提供了一种从序列到动作的解析方法,该方法用预定义清单中的可行操作逐步填充SQL查询的插槽。考虑到通常存在多个具有相同或非常相似语义的正确SQL查询这一事实,我们从句法解析技术中汲取了灵感,并提出使用非确定性预言机训练序列到动作模型。 我们在WikiSQL数据集上评估了我们的模型,并在测试集上实现了83.7%的执行准确度,比使用传统静态oracle训练的模型(假设单个正确的目标SQL查询)准确地提高了2.1%。 当与执行指导解码策略进一步结合时,我们的模型以87.1%的执行精度提高了新的最新性能。
1. 动作的定义
本文idea是从序列到动作,动作列表如下。

2. 模型介绍
编码器部分分别对问题和表schema进行编码,拼接后输出解码器解码器的输出是一个动作序列。
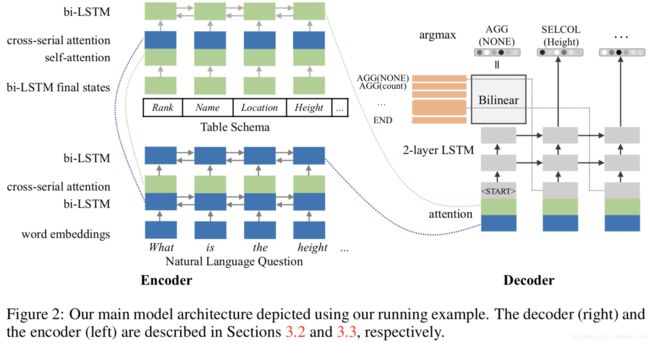
3. 实验结果
实验结果如下表。

11. Robust Text-to-SQL Generation with Execution-Guided Decoding
Chenglong Wang, Kedar Tatwawadi, Marc Brockschmidt, Po-Sen Huang, Yi Mao, Oleksandr Polozov, Rishabh Singh, 2018
本文来自华盛顿大学、斯坦福大学、微软、谷歌大脑。
摘要:我们考虑神经语义解析的问题,它将自然语言问题转换为可执行的SQL查询。 我们引入了一种新的机制,称为执行指南,以利用SQL的语义。 它以部分生成的程序的执行情况为条件,在解码过程中检测并排除故障程序。 该机制可与任何自回归生成模型一起使用,我们将在四种最新的循环或基于模板的语义解析模型上进行证明。 我们证明了执行指南可以普遍提高各种具有不同规模和查询复杂性的文本到SQL数据集的模型性能:WikiSQL,ATIS和GeoQuery。 最后,我们在WikiSQL上达到了83.8%的最新执行精度。
1. 执行指南示例
执行opponent > Haugar时发生runtime error,执行opponent=UEFA时返回空结果,利用这些信息修正sql语句的生成。

2. 实验结果
基于之前工作Corarse2Fine的基础上增加执行指南,效果达到83.8%。

12. A Comprehensive Exploration on WikiSQL with Table-Aware Word Contextualization
Wonseok Hwang, Jinyeung Yim, Seunghyun Park, Minjoon Seo,2019
本文来自韩国公司 Clova AI, NAVER Corp。
摘要:WikiSQL是给定Wikipedia文章中的表格将自然语言问题映射到SQL查询的任务。 我们发现,学习高度依赖上下文和表的单词表示是实现任务高精度的最重要考虑因素。 我们探索了基于BERT体系结构的三种变体,我们的最佳模型在逻辑形式和执行精度方面分别比以前的先进技术高出8.2%和2.5%。 我们提供了对模型的详细分析,以指导如何在此类语义解析任务中利用单词上下文。 然后,我们认为该分数接近WikiSQL的上限,我们观察到大多数评估错误是由于错误的标注引起的。 我们还评测了一部分数据集上的人类准确性,并发现我们的模型超过了人类,执行精度上提升至少1.4%。
1. 模型介绍
编码器采用bert,输入为问题和表头的拼接,开头增加[CLS]标签,问题和表头以及表头各列之间用[SEP]间隔。
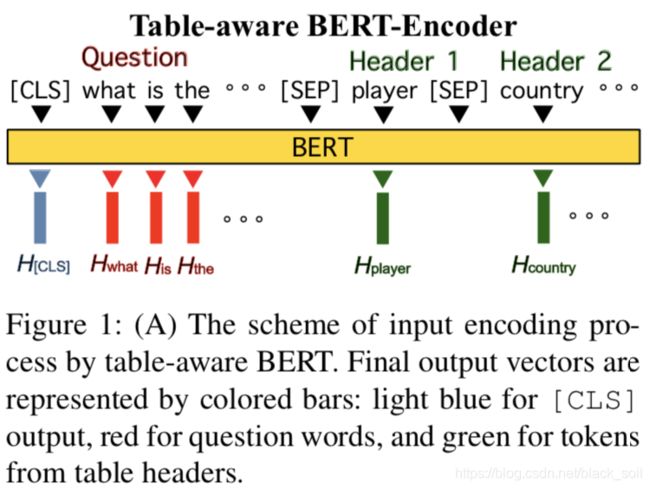
在该编码器之上,本文提出了三种结构:第一种是shallow-layer,也是基于草图来生成sql语句的六个部分,即利用表头表示Hh的第0维度来得到select-column,利用表头表示Hh的第1~6维度来选择select-aggregation(总共6种聚合函数,每个维度对应一个),利用开头表示H[CLS]来选择where-number,利用表头表示Hh的第7维度来选择where-column,利用表头表示Hh的第8~10维度来生成where-operator(三种>,=,<),利用问题表示Hn来生where-value。
第二种是使用采用了pointer network的LSTM来解码生成sql。
第三种是将bert的输出看成embeding,每个部分都有自己的编码解码,有自己的参数。

2. 实验结果

13. X-SQL: Reinforce Schema Representation With Context
Pengcheng He, Yi Mao, Kaushik Chakrabarti, Weizhu Chen, 2019
本文来自微软 Dynamics 365 AI。
摘要:在这项工作中,我们提出了X-SQL,这是一种用于将自然语言解析为SQL查询的新网络体系结构。 X-SQL提议通过BERT样式的预训练模型的上下文输出以及类型信息来学习用于下游任务的新模式表示,从而增强结构模式表示的能力。 我们在WikiSQL数据集上评估了X-SQL,并展示了其最新的性能。
1. 模型介绍
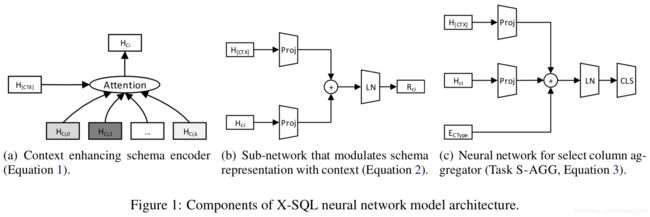
模型包括三个部分:(1)序列编码器:类似BERT,不同点在于,一是我们给每个表增加了一个特殊的空列[EMPTY],二是segment embedding替换为类型embeding,包括问题、类别列、数字列、特殊空列,共4种类型,三是采用MT-DNN而不是BERT-Large来初始化。
(2)上下文增强的schema编码器:根据表格每列的tokens的编码来得到相应列的表示hCi,利用attention,如图(a)。
(3)输出层:将任务分解为6个子任务,每个均采用更简单的结构,采用LayerNorm,输入为schema的表示hCi和上下文表示hCTX。
2. 实验结果
可以看到,最新效果已经被推导了91.8%。

四、小结
WikiSQL数据集于2017年提出,执行准确率从最初的59.4%提升到91.8%,进展飞速,方法也从简单的seq2seq到多任务、迁移学习、预训练等。另一方面WikiSQL数据集并不涉及group by等复杂操作以及多表联合查询,期待这些工作可以早日落地工业界,发挥关系数据库数据的价值。