SSA的优势
业余民科,垃圾内容勿看
传统数据流分析(Data-flow analysis)劣势
前面的提到过传统的数据流分析是 Dense 的分析,就是在分析过程中,要携带当前所有的分析信息经过每一个程序点,即使很多信息与当前程序点没有任何关系。
(1)R大的解释
正是因为SSA形式贯穿于LLVM IR,所以针对SSA value的数据流分析,在LLVM里都是用sparse的方式做的,而不像传统的IR那样要用 bit vector / int vector / set 迭代遍历每条指令去传播信息直到到达fixed point。
- dense分析:要用个容器携带所有变量的信息去遍历所有指令,即便某条指令不关心的变量信息也要携带过去
- sparse分析:变量的信息直接在def与use之间传播,中间不需要遍历其它不相关的指令。
注:侵删
(2)《SSA-based compiler design》的解释
Thus it is possible to associate data-flow facts directly with variable names, rather than maintaining a vector of a data-flow facts indexed over all variables, at each program point.
同时还给出了一个作非零分析的例子,如下图(搬运)所示:
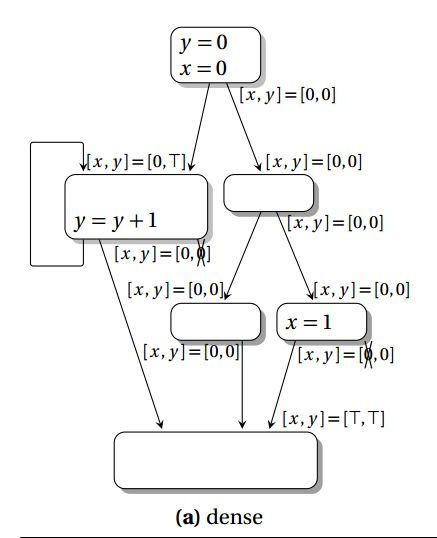
该图中,明显看到在CFG的每个 IN 和 OUT 集合中都要存储关于 x、y的信息,在实际的程序分析中,这些冗余的信息会更多。
(3)Harvard大学PPT
该PPT中有一页能够揭示SSA的必要性:
Motivation
- Data flow analysis need to represent facts at every program point.
- What if :
There are a lot of facts and
There are a lot of program points?
-> potentially takes a lot of space/time - Most likely, we’re keeping track of irrelevant facts.
下面给出了一个图示,该图与《SSA-based compiler design》很相似。
(4)《Engineering a compiler》.second edition.495
这里通过另外一个角度分析传统数据流分析的问题所在,就是很多传统的数据流分析有自己的独特的分析模式,所以传统的数据流分析要同时维护多种分析过程。这里提到的问题就是,能否通过一种 analysis 来同时实现多种 analysis的结果?
下面是《Engineering a compiler》的同时维护多种分析模式的描述:
Over time, many different data-flow problems have been formulated. If each transformation uses its own idiosyncratic analysis, the amount of time and effort spent implementing, debugging, and maintaining the analysis passes can grow unreasonably large.
To limit the number of analyses that the compiler writer must implement and that the compiler must run, it is desirable to use a single analysis to perform multiple transformations.
重点是最后一句话,使用一种分析来实现多种变换。
Summary
传统的数据流分析需要在每个程序点处维护所有元素的值信息,如果CFG比较大或者需要维护的结果太多时,所带来的space/time开销就不能忽略了。另外由于存在很多种代码分析和优化种类,所以就需要一种analysis来同时执行多种变换。
基于SSA的数据流分析优势
(1)R大的描述
描述1:
- sparse 分析:变量的信息直接在def与use之间传播,中间不需要遍历其它不相关的指令。
即便是sparse分析,放在一个dataflow framework里还是可以使用lattice的,而且分析过程可能还是迭代的(只是不需要每次迭代所有指令而已)。
对于SSA的sparse分析,R大给出的部分描述是不需要迭代每条指令,信息直接在def-use之间传播,不需要迭代所有指令。
描述2:
构造SSA形式的IR自身隐含的若干优化,例如:
- 复写传播(copy propagation):所有 x = y 形式的纯拷贝在构造SSA形式时可以自然的优化掉
- 无用代码消除(dead code elimination):SSA形式的的IR通常会有显示的use-def信息,如果IR里有特殊结点是一定存活的(例如函数的return节点),那么以这些节点为根集合跟着 use-def 去遍历 IR 就能找到所有活跃的节点,而剩下的节点肯定是无用的了(因为没有活节点 use 了它们的 def)。这跟GC是一样的。
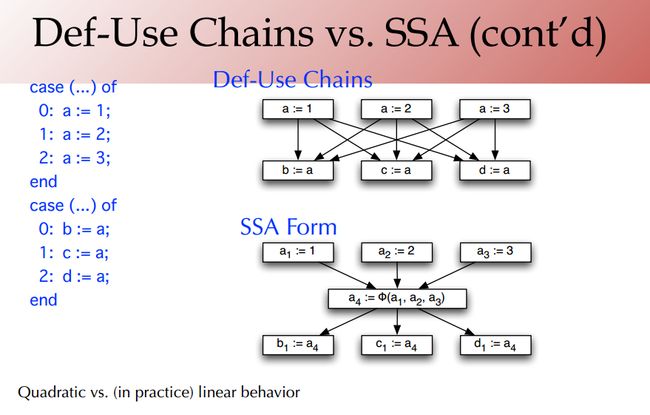
(2)Def-Use Chains vs. SSA
但是如果直接在传统的数据流分析之上加上def-use use-def信息呢,是不是就可以得到SSA的好处,同时又省去构造SSA的开销了呢。Harvard一篇PPT中给出了否定的回答。
- Alternative: Don’t do renaming; instead, compute simple def-use chains (reaching definitions). Propagate facts along def-use chains.
- Drawback: Potentially quadratic(二次方程) size
上面提到如果要定义def-use的话,def-use chains的个数是二次方的 n * m, 其中 n 表示 n 处定义,m 表示 m 处使用。而SSA中的定义-使用的个数是线性的。
(3)《SSA-based Compiler design》
这本书前面提到了SSA对于传统数据流之上的优点,这里我摘抄过来。
However, this example illustrate some key advantages of the SSA-based analysis.
- Data-flow information propagates directly from definition statements to uses, via the def-use links in the SSA naming scheme. In contrast, the classical data-flow framework propagates information throughout the program, including points where the information does not change, or is not relevant.
- The results of the SSA data-flow analysis are more succinct. In the example, there are fewer data-flow facts associated with the sparse(SSA) analysis than with the dense (classical) analysis.
根据上面的描述,基于SSA的分析,信息是沿着从 def-use 链,直接从 def 传播到 use 处的。而传统的数据流之上,即使当前程序点与传播的信息相关,或者是没有改变,这些信息还是要通过当前程序点进行传播的。
而且基于SSA的分析比较简洁,仅需要维护很少的信息即可。
《Engineering a Compiler》
我再搬运一下《Engineering a Compiler》中关于SSA优点的描述。
One strategy for implementing such a “universal” analysis involves building a variant form of the program that encodes both data flow and control flow directly in the IR.
为了解决多种数据流分析,种类繁多很难维护的问题,可以提出一种通用的分析,来将数据流和控制流直接编码在IR中。
SSA has this property. It can serve as the basis for a large set of transformations. From a single implementation that translates the code into the SSA form, a compiler can perform many of the classic scalar optimizations.
上面说 SSA 恰好可以作为多种analysis的基础,在实现SSA的过程中可以实现多种经典的优化过程。
总结
通过以上的描述,我们可以得到SSA的优势可以从两个方面来描述,一个方面是 dense(紧密) 和 sparse(稀疏)两个关键字。另一个方面是在构造SSA可以实现几种经典的优化,并且SSA可以作为很多后续分析优化的基础。
如果要深刻体会SSA的好处的话,要么对编译后端理论有深刻的理解,要么写过几个编译器。可惜两方面我都不满足,所以暂且做个知识的搬运工,搬运过程难免有“损坏”,有问题还望多多交流!
-----------------2019.11.20更新--------------
Benefits of SSA Representation
《Data Flow Analysis Theory and Practice》中有对SSA benefits的详细阐述。主要分为如下两点:
- Sparse,较少的def-use edges意味着较少的计算量
- SSA自带的def-use,可以帮助分析