PBFT算法
PBFT算法
- PBFT算法
- 算法前置
- 算法介绍
算法前置
State Machine Replication
State Machine Replication是一项很有效的fault tolerance技术。在这个模型中,程序(比如一个apache server)被视为 deterministic state machine ,意思就是给程序一定顺序的 input requests ,程序执行后就会到达一定的状态(准确的说是数据结果),而replication就是在多个 nodes 中保持相同的state。
给予每个replicas的input request sequence一致,在deterministic execution的前提下,这些replicas就会 reach the same exact state
摘自原文State Machine Replication 技术 和 PAXOS 算法
FLP Impossibility:
No completely asynchronous consensus protocol can tolerate even a single unannounced process death. [ Impossibility of Distributed Consensus with One Faulty Process,Journal of the Association for Computing Machinery, Vol. 32, No. 2, April 1985]
在异步网络环境中只要有一个故障节点, 任何Consensus算法都无法保证正确结束.
摘自拜占庭将军问题和FLP的启示
Quorum-based voting for replica control
The quorum-based voting for replica control is due to [Gifford, 1979].[3] Each copy of a replicated data item is assigned a vote. Each operation then has to obtain a read quorum (Vr) or a write quorum (Vw) to read or write a data item, respectively. If a given data item has a total of V votes, the quorums have to obey the following rules:
1. Vr + Vw > V
2. Vw > V/2
The first rule ensures that a data item is not read and written by two transactions concurrently. Additionally, it ensures that a read quorum contains at least one site with the newest version of the data item. The second rule ensures that two write operations from two transactions cannot occur concurrently on the same data item. The two rules ensure that one-copy serializability is maintained.
这个是摘自wiki,主要思想就是一个少数服从多数。
它假设每个节点都有一个投票,第一个条件保障了读写不会并行执行。因为当你拿到n>=Vw个投票时,获得n个节点的同意,因而可以执行,而此时另一个人想要读,它无法得到>=Vr个投票,因为V-Vw小于Vr, 因此读操作不会被执行。
以上概念对PBFT算法理解很有帮助!
算法介绍
以下内容参考了微软的论文。里面内容如有不正确或者不合理,请批评指正。
算法的概括
假设,我们有R=3f+1个节点,f个faulty节点。
View number的选取,对于每个replica都有一个编号n,假设我们一共有5个replica,编号分别为0,1,2,3,4,初始化V=0,那么我们的初始化view就是replica p = v mod |R|,编号为0的replica。
- Client发送一个request 到各个replica,其中o代表操作,t代表请求发生的时间戳,c估计是client的信息。
- Replica接收到信息后,并验证信息的真实性(签名,MAC,PK),把信息放到log日志里(这些信息对以后的view change有用)。有序的执行完operation后将reply直接发送给客户端。 ,v代表当前的view number,t代表client发送请求时产生的时间戳,i代表当前的replica,r为结果。
- 当client 接收到f+1个一致性结果时,client就get到一个weak certificate。(当然接收过程都会包括一个认证过程,一下就省略)
- Client有一个timeout机制,如果在一定时间内没有收到足够的请求时,它会重新发送request到replica里,replica如果已经执行过这个请求,它会重新发送一个reply到client(replica的每一次操作发送请求几乎都是有记录里)。如果replica接收到请求的seq是不合法的,就会触发一个view change的操作,此时认为primary出问题了。
Normal Case Operation
现在我们只考虑单个操作,单个操作分三个阶段,pre-prepare prepare commit阶段。其中前两个阶段主要是为了保证的请求执行顺序(SMR理论)
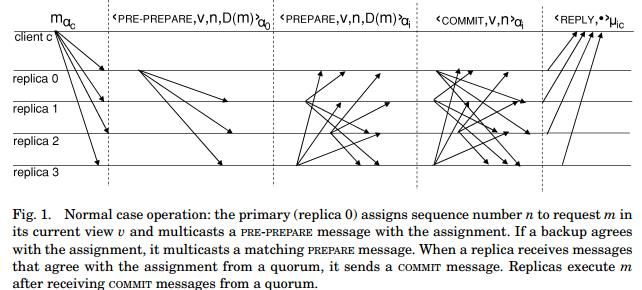
上面图,表示的是在没有faulty节点时的pbft过程。首先client发送请求到各个replica。View节点也就是primary,为接收的请求分配一个序列号,并广播pre-prepare messages出去。
如果replica i之前没有接收过具有相同n和view但degiest不同的消息,并且这个系列号是在某个区间h~H,它的view和当前记录的view相同,身份验证成功,replica也就是备份节点会同意这个分配,它会将 信息广播出去,表示自己同意分配。同时会将pre-prepare与prepare信息记录在log里。如果replica i发送了关于request 的pre-prepare或prepare信息,那么就称这个request在replica中处于pre-prepared状态。
每个replica开始收集prepare 信息,当有至少2f+1(包括自己)相匹配的时候,一个request就达到prepared状态。(当然有可能部分节点达不到prepared状态,如果2f+1达不到prepared状态,理论上各个节点do nothing).
当change views时,各个replica就有可能收集的是不同view的prepare messages,进而可能2f+1节点达不到prepared状态,此时各个节点不应执行,此时就增加了commit阶段来解决这个问题。用广播commit信息,告诉大家我的request n在view v里已经处于prepared状态。这样每个节点开始收集commit,当有2f+1 commit 匹配时,就获得了一个quorum certificate ,达到committed状态。
此时replica就会按照seq由低到高的顺序来执行请求,保证结果的正确性。同时会丢弃时间戳小于记录里最新消息的时间戳的请求。
View change
View change主要发生在view节点出现问题时。这个主要的idea,就在于同步信息。下面过程在不限制内存空间下进行。 
存储在各个节点的数据结构:
P和Q集合,其中P集合存储prepared状态 n, d, v ,Q集合存储了那些已经发送prepare或pre-prepare消息的request的信息n, d, v,meaning that i pre-prepared a request with digested with number n in view v and that request did not pre-prepare at i in a later view with the same number.
当一个节点认为主节点坏掉了,它会进入v+1并广播view-change消息 ,h为replica i最新的stable check point,C包含i中的stable check point的seq和摘要。在发送之前log里的信息都会被更新,发送之后该节点的pre-prepare,prepare,commit信息都会被删除。
各个节点收集view number <= v 的view-change消息,得到一个quroum certificate。这样可以排除faulty节点所发的消息。然后将view-change-ack消息发送到v+1,[view-change-ack,v+1,i,j,d] ,i为sender,d为view-change的摘要,j为view-change的发出者。
新的主节点会不断收集view-change和view-change-ack消息,这些消息可以构成一个a quorum certificate。并且把view-change消息存储在集合S中。它在收到2f-1个关于节点i的view-change-ack消息后,证明i的view-change合理,再将其存储到S里。S里的每一项都是来自不同replica的view-change消息。
大家对viewchange达成一致后,并且验证成功,primary节点就会广播newmessage,这个message是新的主节点会根据S里的信息选择的一个checkpoint和一组request。通俗的就是说要同步上一个primary执行工作中还未执行完的请求和各个节点的状态。
Garbage Collection
这里面有个很重要的概念就是checkpoint,这个checkpoint是用做垃圾处理的一个点。在stablecheckpoint之前的请求都是已经处理好的,因此PBFT算法会在一个间隔来清理掉stablecheckpoint以前存储在log里的信息,来避免无限的去占用内存。
上面垃圾回收部分,也可以参考这篇http://blog.csdn.net/BlueCloudMatrix/article/details/51898105,
实际上的实现要比论文说的还要复杂,hyperleger的PBFT算法是一个很好的实现,不愧IBM大牛,不过跟论文说的也不是完全相同!里边并没有view-change-ack阶段~