itemCF算法
什么是itemCF算法?
itemCF:ItemCollaborationFilter,基于物品的协同过滤
算法的核心思想:给用户推荐那些和他们之前喜欢的物品相似的物品
那么如何判断物品的是否相似呢?
该算法认为,喜欢物品A的用户大都也喜欢物品B,那么我们称物品A和物品B相似。
itemCF算法流程
1.计算物品之间的相似度
2.根据物品的相似度和用户的历史行为给用户生成推荐列表
原理
我们使用下面的公式定义物品的相似度:

其中,|N(i)|是喜欢物品i的用户集,|N(j)|是喜欢物品j的用户集,|N(i)&N(j)|是同时喜欢物品i和物品j的用户集。
从上面的定义看出,在协同过滤中两个物品产生相似度是因为它们共同被很多用户喜欢,两个物品相似度越高,说明这两个物品共同被很多人喜欢。
这里面蕴含着一个假设:就是假设每个用户的兴趣都局限在某几个方面,因此如果两个物品属于一个用户的兴趣列表,那么这两个物品可能就属于有限的几个领域,而如果两个物品属于很多用户的兴趣列表,那么它们就可能属于同一个领域,因而有很大的相似度。
这个假设很容易理解,比如说我喜欢篮球,也喜欢外星人笔记本电脑。给别人推荐电脑的时候可不能推荐篮球。所以,这个假设很重要。
举个?
用户A对物品a、b、d有过行为,用户B对物品b、c、e有过行为,等等

依据上图可以得出相似度矩阵

以(d,a)为例,根据公式可以得出(d,a)的相似度为2/开根(3*6)
得到相似度之后我们还需要结合用户的兴趣做一个乘积,就是算法流程中的第二步。
ItemCF通过如下公式计算用户u对一个物品j的兴趣:
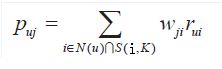
其中,Puj表示用户u对物品j的兴趣,N(u)表示用户喜欢的物品集合(i是该用户喜欢的某一个物品),S(i,k)表示和物品i最相似的K个物品集合(j是这个集合中的某一个物品),Wji表示物品j和物品i的相似度,Rui表示用户u对物品i的兴趣(这里简化Rui都等于1)
该公式含义是:和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
给一个《推荐系统实践》中的例子

可以看得出来,itemCF算法是一个比较简单的算法。那么有没有什么地方可以进行优化的呢?
优化
1.用户活跃度对物品相似度的影响(ItemCF-IUF)
假设一个人买了当当网上80%的书,那么他的选择对于我们来说就不是很重要了,因为他啥都喜欢,参考价值不大。推荐算法是个性化推荐。所以我们引入一个itemCF-IUF。(活跃度越高,权重越小)
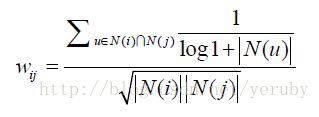
公式只是对活跃用户做了软性的惩罚,但在实际计算中,我们为了避免稠密矩阵的发生一般都直接忽略这种用户的数据。
2.物品相似度的归一化(ItemCF-Norm)

我们首先举个例子。
物品总是属于很多不同的类别,每一类中的物品联系比较紧密。假设在一个音乐网站中,拿黑金属和流行乐这两类聚例子,itemCF算出来的相似度一般都是同类的相似度大于一类的相似度。但是黑金属和黑金属之间的相似度,流行乐和流行乐之间的相似度却不一定相同。
假如说黑金属 互相之间的相似度为 0.8 , 流行乐之间的相似度可能只有 0.3 ,而黑金属和流行乐之间的相似度为 0.1 。在这种情况下, 如果一个用户喜欢了 5 首黑金属 , 5 首流行乐 ,用 ItemCF 给他进行推荐,推荐的就都是黑金属 : 因为,黑金属之间的相似度大。
但如果归一化之后,流行乐之间的相似度变成了 1 ,黑金属之间的相似度也是 1 ,那么这种情况下, 如果用户喜欢了 5 首黑金属 , 5 首流行乐,那么他的推荐列表中的流行乐和黑金属的数目也应该是大致相等的。
所以,如果将itemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率和覆盖率。
参考
itemCF,基于物品的协同过滤算法:https://blog.csdn.net/yeruby/article/details/44154009
协同过滤:https://zhuanlan.zhihu.com/p/37759389