基于HMM的词性标注
环境:python2.7 , 数据:人民日报1998年一月标注数据
原文地址:https://blog.csdn.net/say_c_box/article/details/78550659 ,原文的代码在求发射概率的时候可能有些许错误,现更改代码如下:
举个例子来说:小明和小芳是两个城市的学生,现在小明知道小芳在下雨天时待在家看电视的概率为60%、出去逛街的概率为10%,洗衣服的概率为30%;晴天时洗衣服的概率为45%,出去逛街的概率为50%,在家看电视的概率为5%;阴天时出去逛街的概率为55%,洗衣服的概率为30%,看电视的概率为15%。那么三天内小芳出现“逛街-洗衣服-看电视”的情况的概率是多少?
HMM的构成主要有以下五个参数:
1.模型的状态数(晴天,雨天,阴天)
2.模型的观测数(逛街,洗衣,看电视)
3.模型的状态转移概率矩阵 ,表示step n-1 到step n 状态i下一个是状态j的概率
,表示step n-1 到step n 状态i下一个是状态j的概率
4.模型的状态发射概率矩阵![]() 表示i状态下产生k观测状态的概率
表示i状态下产生k观测状态的概率
5. 初始状态分布概率矩阵
初始状态分布概率矩阵
下面说一下具体参数的计算过程:
![]()
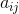 为状态i 转为状态j 的概率,为状态i转为状态j的频数,分母表示状态i到所有状态的总数,也就是状态i出现的次数。
为状态i 转为状态j 的概率,为状态i转为状态j的频数,分母表示状态i到所有状态的总数,也就是状态i出现的次数。

状态i 下出现k观测值的发射概率为:状态i下的出现观测值为k的频数 / 所有状态下出现k的频数
(i) 是初始状态分布概率矩阵,就词性标注来看,表示首个观测值为状态i的概率。
首先求解上面的参数:
def ChinesePOS():
#转移概率Aij,t时刻由状态i变为状态J的频率
#观测概率Bj(k),由状态J观测为K的概率
#PAI i 初始状态q出现的频率
#先验概率矩阵
pi = {}
a = {}
b = {}
#所有的词语
ww = {}
#所有的词性
pos = []
#每个词性出现的频率
frep = {}
#每个词出现的频率
frew = {}
fin = codecs.open("处理语料.txt","r","utf8")
for line in fin.readlines():
temp = line.strip().split(" ")
for i in range(1,len(temp)):
word = temp[i].split("/")
if len(word) == 2:
if word[0] not in ww:
ww[word[0]] = 1
if word[1] not in pos:
pos.append(word[1])
fin.close()
ww = ww.keys()
for i in pos:
#初始化相关参数
pi[i] = 0
frep[i] = 0
a[i] = {}
b[i] = {}
for j in pos:
a[i][j] = 0
for j in ww:
b[i][j] = 0
for w in ww:
frew[w] = 0
line_num = 0
#计算概率矩阵
fin= codecs.open("处理语料.txt","r","utf8")
for line in fin.readlines():
if line == "\n":
continue
tmp = line.strip().split(" ")
n = len(tmp)
line_num += 1
for i in range(1,n):
word = tmp[i].split("/")
pre = tmp[i-1].split("/")
#计算词性频率和词频率
frew[word[0]] += 1
frep[word[1]] += 1
if i ==1:
pi[word[1]] += 1
else :
a[pre[1]][word[1]] += 1
b[word[1]][word[0]] += 1
for i in pos:
#计算各个词性的初始概率
pi[i] = float(pi[i])/line_num
for j in pos:
if a[i][j] == 0:
a[i][j] = 0.5
for j in ww:
if b[i][j] == 0:
b[i][j] = 0.5
for i in pos:
for j in pos:
#求状态i的转移概率分布
a[i][j] = float(a[i][j])/(frep[i])
for j in ww:
#求词j的发射概率分布
b[i][j] = float(b[i][j])/(frew[j])
return a,b,pi,pos,frew,frep
print "game over"参数求解完毕运用动态规划的viterbi算法求解最佳路径:
def viterbi(a,b,pi,str_token,pos,frew,frep):
# dp = {}
#计算文本长度
num = len(str_token)
#绘制概率转移路径
dp = [{} for i in range(0,num)]
#状态转移路径
pre = [{} for i in range(0,num)]
for k in pos:
for j in range(num):
dp[j][k] = 0
pre[j][k] = ''
#句子初始化状态概率分布(首个词在所有词性的概率分布)
for p in pos:
if b[p].has_key(str_token[0]):
dp[0][p] = pi[p]*b[p][str_token[0]]* 1000
else:
dp[0][p] = pi[p]*0.5*1000
for i in range(0,num):
for j in pos:
if (b[j].has_key(str_token[i])):
sep = b[j][str_token[i]] * 1000
else:
#计算发射概率,这个词不存在,应该置0.5/frew[str_token[i]],这里默认为1
sep = 0.5 * 1000
for k in pos:
#计算本step i 的状态是j的最佳概率和step i-1的最佳状态k(计算结果为step i 所有可能状态的最佳概率与其对应step i-1的最优状态)
#
if (dp[i][j] dp[num-1][max_state]:
max_state = j
# print
i = num -1
#根据最大观测值max_state和前面求的pre找到概率最大的一条。
while i>=0:
resp[i] = max_state
max_state = pre[i][max_state]
i -= 1
for i in range(0,num):
print str_token[i] +"\\" +resp[i].encode("utf8") 主入口函数如下:
if __name__ == "__main__":
a,b,pi,pos,frew,frep = ChinesePOS()
#北京/ns 举行/v 新年/t 音乐会/n
str_token = [u"北京",u"举行",u"新年",u"音乐会"]
viterbi(a, b, pi, str_token, pos, frew,frep)运行结果如下:
北京\ns
举行\v
新年\t
音乐会\n
数据下载链接:链接: https://pan.baidu.com/s/1tFvC9Mekyz-vQMtTrwUmvw 提取码: mb7e