自然语言理解系列论文笔记
1 BERT
双向的Transformer预训练语言模型,使用fine-tuning用于下游任务(用于下游任务的策略有两种,基于特征和微调)。主要是用Masked LM实现双向自编码,摒弃先前的自回归方式(自左向右或自右向左预测下一个单词,无法同时利用上下文信息),实现了上下文信息的利用。
BERT输入
输入格式:[cls] Text-A [SEP] Text-B [SEP]
(源码有自动处理的过程)
对于每一个token,它的输入表示为Token Embeddings+Segment Emdeddings+Position Embeddings。
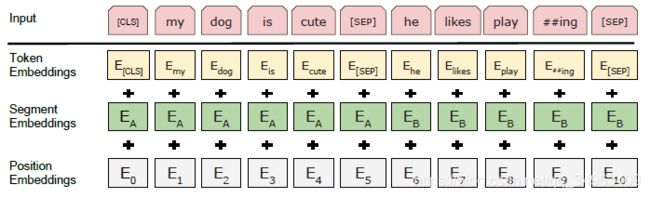
图1 BERT输入表示
预训练
BERT预训练中使用的两大方法为:Mask LM和Next Sentence Prediction。Mask LM为最为重要的贡献。
Masked LM
如图2左图所示,Masked LM用于与训练过程中,Masked LM也是一些文献中的Cloze task–完形任务。
- 随机mask每个句子的15%
- 对于选择的15%的token,每个token:
80% 被替换为[token]
10% 替换为一个随机的token (增加了泛化能力)
10% 不改变 (缓解预训练与微调的不匹配)
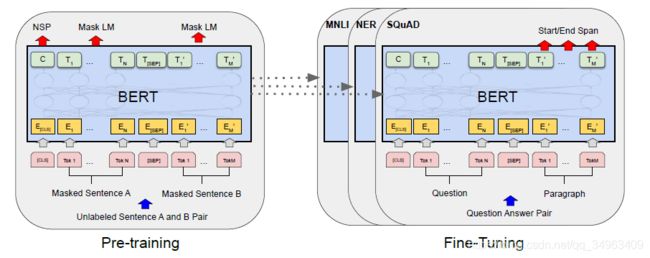
图2 BERT预训练和微调
Next Sentence Prediction
该文章认为,例如QA、NLI任务是基于对两个句子关系的理解,故预训练了一个二分类,判断句子B是不是句子A的下一句。
用于预测的句子表示使用[CLS]经过Transformer的深度encoding的最后一个隐藏状态。为什么使用[CLS]代表整个句子的表示?
个人理解:[CLS]本身没有语义信息,只是为句子的开头,并且在预训练时不会被mask,[CLS]面向整个序列的做 attention,[CLS]的输出足够表达整个句子的信息;而每个token 对应的 embedding 更关注该 token 的语义语法及上下文信息表达。
Fine-tuning
如图2右图为Fine-tuning过程,该过程中不再使用Masked LM,也就是上面提到的和预训练不匹配。
其输出,token representations用于token-level的下游任务,[CLS] representation 用于分类。
Bert使用
附上链接:https://cloud.tencent.com/developer/article/1461418
这里说明一下,对于bert-as-service方式,若以以下两种服务器启动方式:
- 命令bert-serving-start -model_dir filrpath -num_worker=1
- 命令bert-serving-start -pooling_strategy None -model_dir filrpath -num_worker=1
from bert_serving.client import BertClient
bc = BertClient()
bc.encode([“今天天气真好”])
上述编码会分别生成一下维度的表示:
- 1*768 [CLS]的representation 即句子的向量表示;
- 25*768 所有token的representation,当然,这里token的representation也是具有上下文语义信息的。
2 Transformer XL
vailla Transformer
语言模型根据之前的字符预测片段中的下一个字符。Al-Rfou等人基于Transformer提出对于较长输入,将输入分成段,并分别从每个段中进行学习,如下图所示。
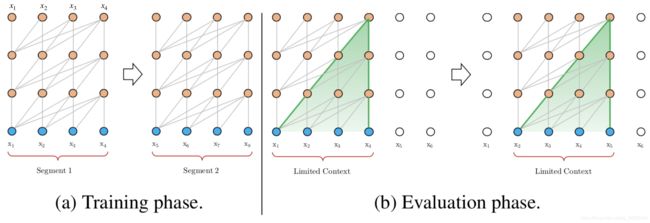
该方法处理长度增加,性能优于RNN,但仍有以下缺点:
- 上下文依赖长度受限:模型看不到前面段的上文信息
- 上下文碎片:段与段之间没有上下文依赖性,尤其是对分段周围影响较大
- 推理速度慢:测试时,每预测下一个单词都要重新构建上下文,并从头计算,并且每次只能前进一个单词(word-level)
Transformer XL
为了解决上述问题,提出段级的使用状态重用的循环机制以及相对位置编码方案。Transformer XL还可以被用于单词级和字符级的语言建模。
段级状态重用的循环机制
与vanilla Transformer的本质不同是在于引入了段与段之间的循环机制,使得当前段在建模的时候能够利用之前段的信息来实现长期依赖性。
处理每个段时,除第一个段外,每层隐藏层的输入来自:
- 上一层隐藏层的输出
- 前一段中上一层隐藏层的输出(这里前段不再进行梯度更新,即作为固定输入)
在输入前,将前段和当前段隐藏层进行级联:
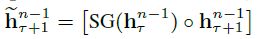
其后:

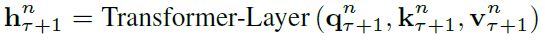
其中SG(·)代表stop-gradient,[hu, hv]代表沿长度的尺度级联,是沿长度将上一段的上一层隐藏层的输出和当前段上一层隐藏层的输出级联嘛?这里存留一个问题,如何级联?我这里对图中的对应关系有所疑惑,希望大神能够解答哇~
相对位置编码
文中现直接将transformer中的位置编码应用于上述循环机制,计算如下:
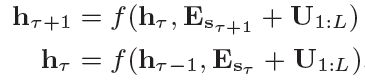
其中τ表示第τ段,Esτ代表段sτ的单词嵌入序列,f代表transfomer函数。很明显,这里两端位置编码是相同的,这就会导致绝对的性能损失。
为此,引入相对位置编码到attention score的计算中,代替静态地引入初始嵌入,从而使得时间序列的偏差更直观、更具推广性。
Transformer的attention score:

上述公式也就是Ai,jabs=(Wq(Exi+Ui))T·Wk(Exj+Uj)。
Transformer XL的相对位置编码attention acore:
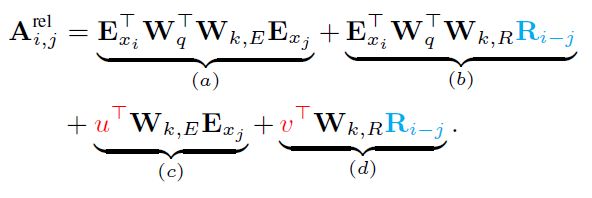
三点变化:
-
Uj -> Ri-j
-
项(c)中,UiTWqT -> uT,项(d)中,UiTWqT -> vT。整个query vectors对于所有位置都是相同的,无论query位置如何,对不同单词的偏向都应该保持不变,故将上述参数改为u,v可学习的参数向量。(个人认为对于每个query,由于已经编码了key和query的相对位置,query的位置信息编码就没有意义了,毕竟要关注的是它们的关系)
-
Wk,E和Wk,R的分割,分别被用于生成基于内容的key vectors和基于位置的key vectors。
对于Transformer XL的相对位置编码attention acore的四部分可直观地理解为: -
基于内容的寻址:没有添加位置编码的原始分数
-
基于内容的位置偏置:相对于当前内容的位置偏差
-
全局的内容偏置:用于衡量key的重要性
-
全局的位置偏置:根据query和key之间的距离调整重要性
这一部分感觉更难理解一些,我也有一个遗留问题:Transformer XL是不是只编码了上文信息?
整体计算公式
考虑一个N层的只有一个注意力头的模型,对于n=1,2,…,N:
