爬虫库Urllib(代理IP等)
Python3中-爬虫库Urllib
- 代理IP
- 1. urllib.request.ProxyHandler()
- 2. 演示一下代理IP去访问目标网址吧
- Cookies的使用
- 1. Urllib提供HTTPCookieProcessor()
- 1.1 Cookies写入文件:
- 1.2 Cookies读取:
- 证书验证
代理IP
1. urllib.request.ProxyHandler()
①代理IP的原理:本机---->大力IP---->访问的网站(服务器)
文字描述:本机先访问代理IP,再通过代理IP地址访问互联网,这样网站(服务器)接收到的访问IP就是代理IP地址。
②由Urllib提供urllib.request.ProxyHandler()方法可动态设置代理IP池,具体摘录如下:

2. 演示一下代理IP去访问目标网址吧
①打开浏览器,去搜索几个免费的代理ip吧,如下是我找的免费ip代理(时间是2020年07月28日 09:53,后续也许能用,也许用不了,用不了的话,就自己网上找一下吧)
58.211.134.98 38480
171.35.163.230 9999
218.241.154.252 3128
118.113.247.4 9999
182.149.82.88 9999
116.196.85.150 3128
110.189.152.86 40698
②找到免费的代理ip,然后就开始写代码,如下代码:
# 方法一
import urllib.request
# 请求的url
url = "https://movie.douban.com/"
# 添加请求头字典
# headers = {
# 'User-Agent': "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
# 'Referer': " https://movie.douban.com/",
# 'Connection': "keep-alive"}
# 注意:此处的headers要写为一个元组类型才可以。写为字典类型的话会报错!
headers = [('User-Agent',"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"),
('Referer',"https://movie.douban.com/"),
('Connection',"keep-alive")]
# ①设置代理IP
proxy_handler = urllib.request.ProxyHandler({
'http':'58.211.134.98:38480',
'http':'171.35.163.230:9999',
'http':'218.241.154.252:3128',
'http':'118.113.247.4:9999',
'http':'182.149.82.88:9999',
'http':'116.196.85.150:3128',
'http':'110.189.152.86:40698'
})
# ②使用build_opener()函数创建带有代理ip功能的opener对象
opener = urllib.request.build_opener(proxy_handler)
# ③增加请求头
opener.addheaders = headers
response = opener.open(url)
# 读取返回内容
html = response.read().decode('utf8')
# 写入文件txt
f = open('html.txt', 'w', encoding='utf8')
f.write(html)
f.close()
# 方法二
import urllib.request
import random
# 请求的url
url = "https://movie.douban.com/"
# 添加请求头字典
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
'Referer': " https://movie.douban.com/",
'Connection': "keep-alive"}
# ①设置代理IP
proxy_list = [
{'http':'58.211.134.98:38480'},
{'http':'171.35.163.230:9999'},
{'http':'218.241.154.252:3128'},
{'http':'118.113.247.4:9999'},
{'http':'182.149.82.88:9999'},
{'http':'116.196.85.150:3128'},
{ 'http':'110.189.152.86:40698'},
]
# 随机选择一个代理
proxy_ip = random.choice(proxy_list)
print(proxy_ip) # 打印一下随机的代理ip
# 使用选择的代理构建代理处理器对象
proxy_handler = urllib.request.ProxyHandler(proxy_ip)
opener = urllib.request.build_opener(proxy_handler)
request = urllib.request.Request(url, headers=headers)
response = opener.open(request)
# 读取返回内容
html = response.read().decode('utf8')
# 写入文件txt
f = open('html1.txt', 'w', encoding='utf8')
f.write(html)
f.close()
上述代码验证是可以的(验证时间2020年7月28日11:43)
| 错误 | 描述说明 |
|---|---|
| ConnectionResetError | [WinError 10054]远程主机强迫关闭了一个现有的连接。 |
| urllib.error.URLError | urlopen error Remoteend closed connection without response(结束没有响应的远程连接) |
| urllib.error.URLError | urlopen error[WinError 10054]远程主机强迫关闭了一个现有的连接 |
| TimeoutError | [WinError 10060]由于连接方在一段时间后没有正确答复或连接的主机没有反应,因此连接尝试失败 |
| urllib.error.URLError | urlopen error[WinError 10061]由于目标计算机拒绝访问,因此无法连接。 |
Cookies的使用

1. Urllib提供HTTPCookieProcessor()
Urllib提供HTTPCookieProcessor() 对Cookies操作,但Cookies的读写是由MozillaCookieJar()完成的。
1.1 Cookies写入文件:
import urllib.request
from http import cookiejar
import random
# 请求的url
url = "https://movie.douban.com/"
# 添加请求头字典
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
'Referer': " https://movie.douban.com/",
'Connection': "keep-alive"}
# ①设置代理IP
proxy_list = [
{'http':'58.211.134.98:38480'},
{'http':'171.35.163.230:9999'},
{'http':'218.241.154.252:3128'},
{'http':'118.113.247.4:9999'},
{'http':'182.149.82.88:9999'},
{'http':'116.196.85.150:3128'},
{ 'http':'110.189.152.86:40698'},
]
# 随机选择一个代理
proxy_ip = random.choice(proxy_list)
print(proxy_ip) # 打印一下随机的代理ip
filename = "cookie.txt"
# MozillaCookieJar保存cookie
cookie = cookiejar.MozillaCookieJar(filename)
# HTTPCookieProcess创建cookie处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
# 使用选择的代理构建代理处理器对象
proxy_handler = urllib.request.ProxyHandler(proxy_ip)
#创建自定义opener
opener = urllib.request.build_opener(proxy_handler,handler)
request = urllib.request.Request(url,headers=headers)
# open方法打开网页
response = opener.open(request)
# 保存cookie文件
cookie.save()
运行结果:
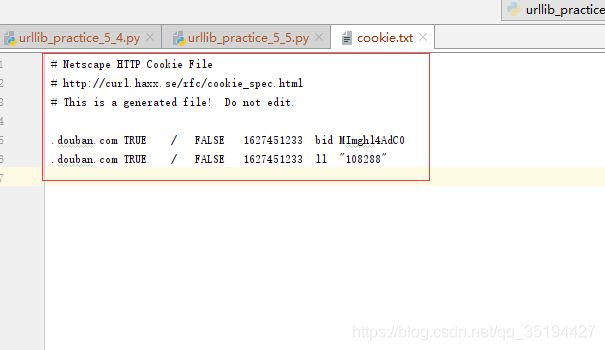
1.2 Cookies读取:
import urllib.request
from http import cookiejar
# 请求的url
url = "https://movie.douban.com/"
# 添加请求头字典
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
'Referer': " https://movie.douban.com/",
'Connection': "keep-alive"}
filename = "cookie.txt"
# 创建MozillaCookieJar对象
cookie = cookiejar.MozillaCookieJar()
# 读取cookie.txt内容到变量
cookie.load(filename)
# HTTPCookieProcessor创建cookie处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
# 创建opener
opener = urllib.request.build_opener(handler)
request = urllib.request.Request(url,headers=headers)
# opener打开网页
response = opener.open(request)
# 输出结果
print(cookie)
执行结果:


证书验证
摘录过来的:
当遇到一些特殊的网站时,在浏览器上会显示连接不是私密连接而导致无法浏览该网页。若在没有安装12306根证书的情况下访问12306网站


import urllib.request
import ssl
# 关闭证书校验
ssl._create_default_https_context = ssl._create_unverified_context
url = "https://kyfw.12306.cn/otn/leftTicket/init"
response = urllib.request.urlopen(url)
# 输出状态码
print(response.getcode())
执行结果:
