TensorFlow进阶教程
目标读者:假设读者是已经熟悉python,并且已经看了一些tensorflow示例程序,希望能了解tensorflow的内在编码规则、特点和高效的编码方式。如果是这样,本文会适合你。
本文切入点是介绍tensorflow与python/numpy的不同以及语法习惯/编程思路的转换,然后介绍TF语言的重要特征和推荐的编程习惯及方法;
如果读者还不熟悉numpy或python,请先学习相应教程。如果你还未看过tensorflow代码实例,可先学习tensorflow最新官方教程 https://www.tensorflow.org/tutorials, 或这个历史版本的中文教程:http://www.tensorfly.cn/tfdoc/get_started/introduction.html;看两三个示例,看懂就够了。
本文总结&修改自:https://github.com/vahidk/EffectiveTensorflow,大量素材也来源于此。
喜欢阅读英文资料的同学也可以直接阅读原文,目录相同,但部分实例和讲解角度不同。
============
目录
1. numpy 与 tensorflow的最大不同,符号型语言
2. 区分static shape和dynamic shape
3 variable scope的使用
4 broadcasting的优缺点
5 Tensorflow的数据读入
6 Tensor与Variable的区别
7 逻辑分支与循环
8 多卡并行运算
9 TF Debug
10 数值精度问题
11 几种常用函数的实现示例代码
参考资料:
============
1. numpy 与 tensorflow的最大不同,符号型语言
numpy是解释性语言,tensorflow是符号性语言。如果你是从c++(编译性语言) -> java -> python 的路径学习的编程语言,那么应该还没有接触过符号语言。类似的符号语言,还有 Hadoop(Map Reduce),Spark (scala, pyspark),如果了解它们则可以在学习过程中类比它们与tensorflow的异同。
符号语言(symbolic)最大的特点就是暗含了一个框架规则,不需要把程序的每一步都清清楚楚的写出来,但你也必须按框架要求的接口编程。Tensorflow中只需要把数据流图定义好,然后指定数据,系统执行时会使用大量框架约束好的,自动执行的行为,这部分不需要显示定义。在tensorflow中,和numpy最显著地区别就是你不需要再显示去计算梯度了,只需要调用.minimize(),tensorflow就会自己去算loss所依赖的所有w的梯度,并更新这些w。这会大大减少编程成本,当然同时也会增加学习成本。(类似于Map Reduce,你只需要实现mapper和reducer就好,剩下的就配置超参指定数据源,剩下的系统自己搞定)
因此,同样的操作,可以看看下图numpy和tensor编程时的异同:
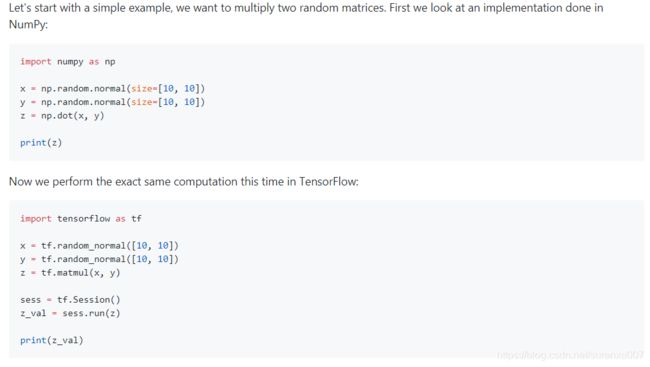
通过代码可以看到:
- tensorflow中直接print(z) 会报错,所有的节点在sess.run()中执行前都是虚拟的,不包含值。print时会得到:
-
Tensor("MatMul:0", shape=(10, 10), dtype=float32) - 其原因是tensorflow中,代码分为graph定义 和 session执行两部分,且必须先定义graph再定义session。前者定义数据流图,但不会立刻执行,后者才会触发执行。它还有以下特点:
- Graph部分代码:是特殊的代码块,一般都是在GPU中并行执行的,这里应该定义且仅定义矩阵计算代码。部分python代码将无法被正常执行(但可能不报错),比如print();另外一定要杜绝使用for, while 语句,并尽量少使用 if 语句,已提升运行性能。
- Session部分代码:位于普通python代码函数中,一般都是在CPU中串行执行的,可以认为是普通的python代码。这个函数可以自由调用各种python函数,比如print(),for, np.xxx等。
- 交互规则:在session执行之前,graph中节点是没有值的。session可以循环执行图中节点,后者除了varaible类型节点不会被重复初始化外,图中的所有节点值均会存储一份实例在内存,并在上次更新结果的基础上继续更新。如果是多GPU并行,它们还会在多卡之间通过参数服务器同步。
- 归属区分:除了像tf.session()这种流程接口函数,所有你能遇到矩阵计算相关的 tf.xxx 函数(区别于np.xxx函数)都是graph函数,它们都只能在graph定义时出现,并在sess.run()中通过运行图节点被真正执行,不能在普通函数中正常执行(如上面直接print(z))。
- 兼容性:Tensorflow支持你把graph和session代码混着写,即你可以把它们写进同一个函数。这方便了我们在交互式环境中调试代码,但不是好的编程习惯。正式代码一定要把graph和session代码分开写。另外在Graph中是可以调用 np.xxx 矩阵计算函数的,np.xxx得到的数据不具备Graph节点的特点,即其值不会被记忆,也不能被自动更新,一般只用于常量的声明,但是并不是好习惯,提倡用tf.xxx创建常量。
- 注意:tf实例代码中,这里是tf.random_norm()生成tensor,所以可以直接执行。
- 如果是tf.get_variable("somename", shape=[10,10]) 生成的是variable,则需要先sess.run(tf.global_vairables_initializer()) 后才能计算后续节点。
2. 区分static shape和dynamic shape
tensorflow的调试过程中经常要打印tensor的shape出来,来确定我们的各项操作正确性(因为一般tensor都太大,你不太可能打印其中的每个元素,会刷屏)。tensorflow中定义了两种shape类型:
- 静态shape: 其类型是
- 静态shape 是tensor与session无关的状态:
- 对于a = tf.placeholder(tf.float32, [None, 2, 3]),它的静态shape就是[None, 2, 3]
- 对于a = tf.random_norm([128, 2, 3]), 它的静态shape是[128, 2, 3]
- 静态shape 是tensor与session无关的状态:
- 动态shape: 其类型就是Tensor
- 动态shape是tensor在session中的状态
- 对于 a = tf.placeholder(tf.float32, [None, 2, 3]),它的动态shape取决于sess.run()中feed_dict对a赋值的数组大小。如sess.run(xopt, feed_dict={a:np.random_norm([10,2,3])},则a的动态shape是[10, 2, 3]
- 对于a = tf.random_norm([128, 2, 3]), 它的动态shape与静态相同,都是[128, 2, 3]
- 动态shape是tensor在session中的状态
显然:Debug应该优先用静态shape,动态shape只有使用sess.run才可以取到。
- 动态shape值应该用于Graph逻辑中,可以Debug,也可以作为某个函数的算子(如tf.reshape()),它只有在sess.run中才能取到值;
- 静态shape值只应该在Graph外调用,只能用来Debug,它不需要也不能在sess.run()中执行。
具体对应的两种操作方法是有显著区别的:
- a.shape: 这种方法获得的是tensor的静态(static) shape
- a是tensor,或placeholder
- 它支持[None, 32]这种带占位符的表达方式,可以被直接print,也可以.to_list()后转为list供Graph外的操作使用;
- 它不需要也不能在sess.run()中执行。比如不能执行sess.run(a.shape)
- 示例代码:

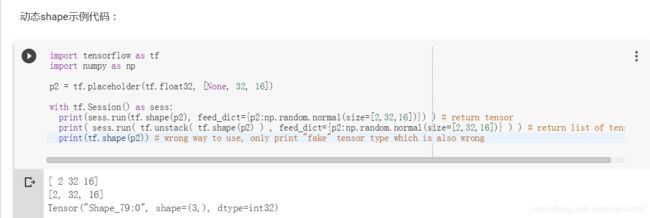
- tf.shape(a): 这种方法获得的是tensor的动态(dynamic) shape
- a是tensor,或placeholder
- 它不支持[None, 32]这种带占位符的表达方式,必须在feeddict赋值基础上才能返回值;
- 由于类型是Tensor,如果需要转换为list,需要用 tf.unstack()
- 它必须在sess.run中使用,或在graph中使用。不可以直接从外部调用。比如不能执行print(tf.shape(a))
- 实例代码
3 variable scope的使用
3.1)变量name: Graph中的所有节点(tensor, place_holder, variable)都有一个名字,类似于C++/Python里的变量。如果你不显式给出的话,系统也会默认命名。变量名是模型存储、加载、迭代运算所必须的,建议显式给出,这样对你后续debug,打印各个变量及变量梯度会有很大帮助。

3.2)scope的作用--解决变量重名问题:不像Python通过变量的作用域优先级区分同名变量,Tensorflow中默认所有节点都在同一个作用域中,python是解释型语言,变量不需要声明,所以默认会把重名变量当做同一个变量复用。
想象一下你想生成两个全链接层,于是调用了该子函数两次,结果你并没有生成两个独立的全链接层,而是把同一个全链接层执行了两次。这恐怕不是我们想要的。此时你就需要在两个不同的namescope里调用该函数,这样,就能保证得到的是两层独立的网络了。
3.3)两种scope声明方法作用及区别:
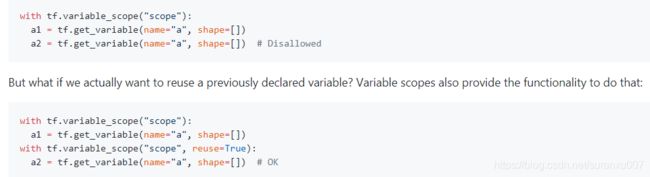
直接说结论:在任何时候都应该用get_variable()和vairable_scope()的组合。这将减少后期很多让你疯魔又找不到的bug。
懒得翻译了,直接看代码吧。。。(好吧真实原因是我饿了要去吃晚饭了)

3.4)reuse的作用和特点
先说结论:除非你特意要复用网络,否则reuse都应该设置为None(缺省默认是None),千万不要顺手给个AUTO_REUSE
上面说到了重名变量,get_variable()函数有个特点,如果它发现两个同名变量,而且reuse又没有被设置为True,或者AUTO_REUSE,那么它就会报Exception。其用法如下面代码截图。
-- 注意这个Exception是个非常好的事情,总好过你不知不觉间复用了网络还不自知,然后你的网络loss一直无法下降,然后你花了一个星期还不知道是什么原因,你去检查了数据,loss,梯度,以及各种你能想到的原因。然而除非你把每个w都打印出来,你可能一辈子也发现不了这个bug。这就是你应该使用get_variable() 而不是 tf.Variable()的原因。
reuse的可以有三个值:True, None, tf.AUTO_REUSE; 默认为None
-- 为什么没有False呢?原因是variable_scope出现嵌套时,子空间会继承上层空间的reuse,且一旦上层空间reuse为True,则子空间也是True(即使设置为reuse=False)(稍微想一下就能理解为什么)。即如果上层为False,下层可以设置为True,但反过来不行。那么允许写reuse=False直观上就很有歧义了,所以TF版本升级后把False和None的处理逻辑完全等价并且从文档里去掉了False,只保留了None(骚操作)。None表示:继承上层,即上层是什么当前层就是什么,如果当前节点为最顶层,则为False。
那么一共有以下几种情况:
1)如果所有scope都没有设置reuse,所有reuse默认为None,为False。此时如果你在同一个scope中调用了两个同名的get_variable(),则会抛重名异常
2)如果某节点设置为reuse=True,则自该节点往下所有scope均为reuse=True。该scope内所有变量默认已经初始化过了,遇到get_variable时直接拿来用。此时,如果你第一次调用一个变量的get_variable()同时该scope的reuse又是True,就会抛异常(没有初始化)
3)上述两种异常实在太烦了。如果设置为tf.AUTO_REUSE,则第一次调用时自动设为False,以后任何重复调用时自动设为True。再也不用担心异常了。嗯。。。已经说过这样做不好了。
3.5)好吧,那么,我该怎么解决函数内部同名变量的Exception问题呢?
我们会遇到两种不同的情形:
a) 我们确实想复用变量:
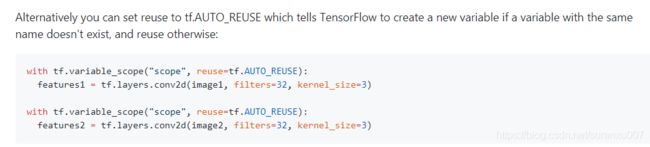
比如DSSM中我们的两个子网络(query, title)想复用同一个embedding层。此时,只需要在embedding层的variable_scope中使用AUTO_REUSE就好了。示例代码我就直接用参考资料中的了,大家类比理解就好。这里的feature1和feature2就是共用一个相同网络参数得到的,它们的梯度会同时影响这个网络的w。
b) 我们不想复用变量
比如上面提到的例子,我们有两层网络, layer2是layer1的输出是layer2的输入,此时我们不能复用参数。我们只需要把它们放在不同的variable scope即可,此时虽然函数内名字相同,但变量拥有了不同前缀也就是不同的变量。注意,没事就写个reuse=False,终有一天你会感谢我的 (-- 祝没有这一天 (⊙v⊙) )
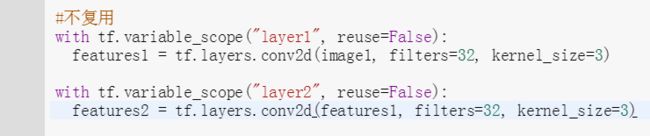
4 broadcasting的优缺点
这里的broadcasting不是spark中的broadcasting,TF中是指:
当不同shape tensor做element-wise运算时,若a张量的某维为1,而b张量不为1,则自动将a张量该维补齐到和b张量相同大小,再计算的隐藏规则。相当于省去了你显式的调用tf.tile(),看代码:


这里显然 a.shape 是[2, 2], 而b是[2, 1],但运算时隐式的补齐了b的维度,让b变成了[ [1., 1.], [2., 2. ]。
broadcasting的优点和缺点:
- 优点:不用写tile,让代码更简洁,运行效率也更高。比如在DSSM计算两个向量内积时,这种做法比较常见。
- 缺点:导致代码可读性下降,在一些情况下可能导致有bug无法被发现。如下面的代码截图,c=12而不是6,原因是a,b都被隐式地tile了。即 a=[1., 1.], [2., 2.] , b = [1., 2.], [1. , 2.]
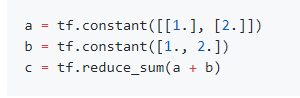
5 Tensorflow的数据读入
几乎所有情况下,你都应该利用placeholder将数据传入Graph,来增加代码的可复用性。示例程序如下:

数据读入常见问题:性能
由于python语言的特点,当我们在读取一些大的数据集时,如果直接用Python本地读取再用feed_dict装载进placeholder,读取速度,尤其是random batch的速度会非常慢,进而导致GPU利用率非常低,系统大部分延时都是在读数据。之前的解决方法是用c++写这部分代码并且取消random batch,然后通过python调用c++获得高性能的数据读入。还好,现在我们有了更方便的方法。
数据读入性能优化方法:TFRecord API
TFRecord是TF约定的一种数据组织形式,其数据结构类似json。只要我们按照此结构组织数据,就可以通过API函数直接调用得到数据。示例代码如下:
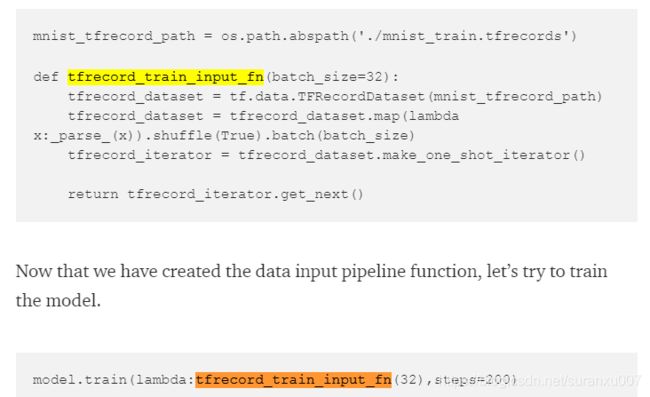
TFRecord更多资料请参见下面两个链接
教程:https://medium.com/coinmonks/beginners-guide-to-feeding-data-in-tensorflow-part2-5e2506d75429
官方文档:https://www.tensorflow.org/api_guides/python/reading_data#Reading_from_files
6 Tensor与Variable的区别
先说结论:能用Tensor的时候不要用variable,如果variable有赋值操作,注意是否需要使用tf.dependency
在大部分运算中,Tensor和Variable的用法貌似没什么区别,它们都可以被赋值,被调用,被打印。但两者有本质的不同:
- Tensor是常量,Tensorflow会自动记录tensor之间的依赖关系,按依赖关系依次计算
- Variable是变量,如果某个操作没有与tensor的依赖关系,则其运行顺序是随机的。TF并不是按代码顺序执行的。
示例1:这里我们其实建立了3个tensor而不是2个。TF会自动先算a,再算b,再算a'=a+b ( 因为 a' 依赖于前两者)

示例2:这里的a是变量,事实上最终的打印值既可能是[5,7],也可能是[5, 3],这完全取决于TF在那个时刻的运算顺序。
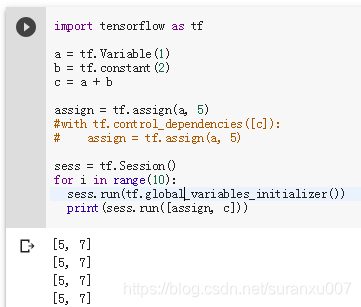
示例3:如果确实相对varable赋值该怎么办?使用tf.dependency
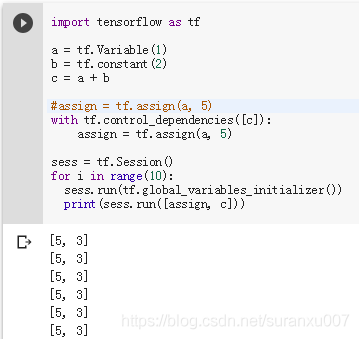
7 逻辑分支与循环
由于GPU的特点,TF的Graph应该尽量避免使用分支和循环语句,尤其是内存单元级别的,尽量用高效的矩阵运算代替。
但如果必须使用,应该用where和while_loop。示例代码如下:


8 多卡并行运算
多机多卡比较复杂,需要参数服务器通过同步/异步方式来同步参数,也需要资源分配中心去控制资源的生成、分配和销毁。多数企业都有自己的分布式TF框架,此时你只需要按说明的API实现即可,如果没有,则应该优先购买多卡机器,做单机多卡的并行运算。这里仅介绍单机多卡的编程技巧。
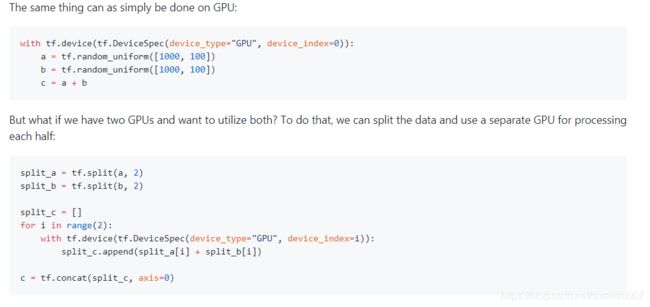
单机多卡的实现,本质上是一个在graph中手写"map"和"reduce"的过程。本质上,这里的“map"是把训练数据切片,分到多张GPU卡上去跑,"reduce"则是把不同卡上跑出的tensor concat起来。并行语法是tf.device(),看代码:
(第一段是单卡,第二段是双卡版本)
但这样写很不通用,我们可以写一个通用的并行化函数,并且在loss计算时使用:
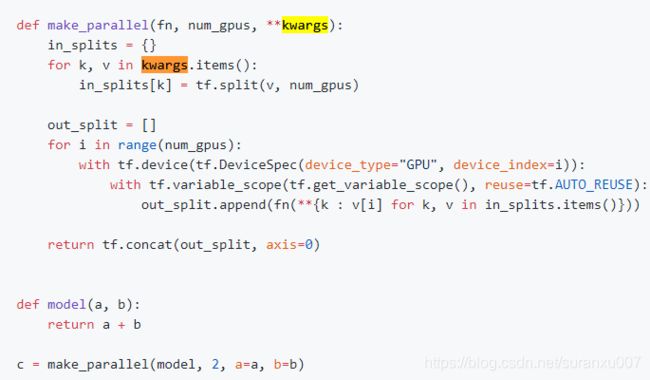
然后我们只需要在计算loss时使用即可,其中colocate_gradients_with_ops 设置为true后,梯度下降也将在各个对应的GPU上执行。

9 TF Debug
1) 打log,观察正确性
使用第2部分中的print(tensorX.shape) 可以看到tensor大小,这里不再讲。
使用tf.Print() 或 tf.print() 可以打印出tensor中的内容(梯度也可以打印)


2)使用assert,确保数据符合自己预期
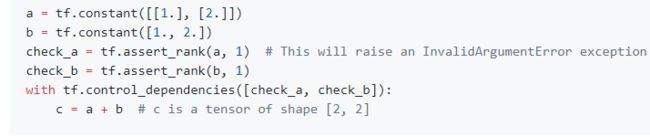
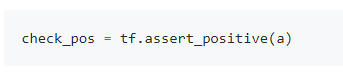
TF所有的assert函数可以看这里:https://www.tensorflow.org/api_docs/python/tf/debugging/Assert
3)使用tf.compute_gradient_error 检查梯度偏差
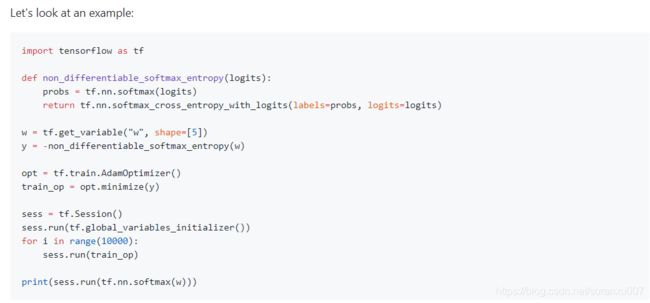
这段没看太懂,该函数在计算 the maximum error for dy/dx between the computed Jacobian and the numerically estimated Jacobian.
我理解应该是当用错一些函数,导致梯度计算中出现精度损失时(此时数学中的梯度和实际算出的梯度大小差距较大),可以通过该函数检查发现。一般该值在10^(-5)级别,如果在10^(-2)级别及以上则应该警惕。把原文的例子粘过来:

10 数值精度问题
数值精度是DNN实现时最应该警惕的问题之一。两种类型:最大值越界和小数部分精度消失。
1)比如float32的最大值在10^30左右,而如果有exp(x)操作,则一旦x>88.7就会越界
2)比如float32的最大精度在10^(-45)左右,当小数部分不足时会截断,只留整数部分。这在sigmoid, tanh激活时需要警惕。
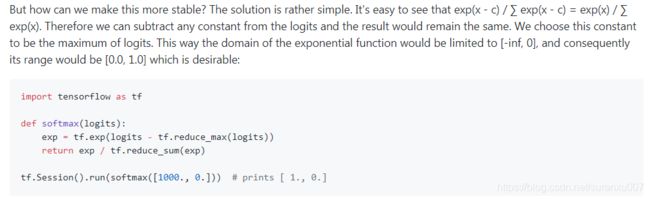
解决方法:在涉及到exp, log操作时,尽量参考他人代码,使用tf已有的API,而不是手动实现。
比如算多分类交叉熵loss的时候,tf有softmax_cross_entropy_with_logits()函数,算log(sigmoid(x))时有log_sigmoid(x)函数。
看1个有问题的例子和解决方法:

11 几种常用函数的实现示例代码
都是代码就不粘贴了,大家直接在原文看就好:(有些函数实现最新的TF API中已经包含)
https://github.com/vahidk/EffectiveTensorflow#get_shape
[全文完]
参考资料:
https://github.com/vahidk/EffectiveTensorflow
版权声明:转载请注明出处:苏冉旭的博客 https://blog.csdn.net/suranxu007/article/details/87531215