php+mysql实现简单的协同过滤推荐算法
昨天转载过一篇文章,描述的是协同过滤推荐算法。今天利用空余时间,我尝试了一下,当然,第一次实现没有考虑效率的问题,好多流程也是能省则省。写这篇文章,一方面理清自己的思路,另一方面为之后提升算法的实现效率,做一点文字记录。
要实现协同过滤推荐算法,首先就要理解算法的核心思想和流程。该算法的核心思想可以概括为:若a,b喜欢同一系列的物品(暂时称b是a的邻居吧),则a很可能喜欢b喜欢的其他物品。算法的实现流程可以简单概括为:1.确定a有哪些邻居 2.通过邻居来预测a可能会喜欢哪种物品 3.将a可能喜欢的物品推荐给a。
算法核心的公式如下:
1.余弦相似度(求邻居):

2.预测公式(预测a可能会喜欢哪种物品):
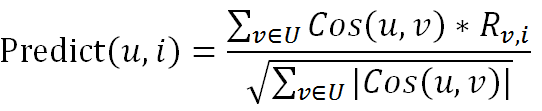
仅从这两个公式我们就可以看出,仅仅是按照这两个公式进行计算,就需要进行大量的循环与判断,而且还涉及到排序的问题,就涉及到排序算法的选择与使用,这里我选快排,从网上copy了一段快排,直接用。总之实现起来很麻烦,在大数据情况下,更何谈效率。
首先建表:
DROP TABLE IF EXISTS `tb_xttj`;
CREATE TABLE `tb_xttj` (
`name` varchar(255) NOT NULL,
`a` int(255) default NULL,
`b` int(255) default NULL,
`c` int(255) default NULL,
`d` int(255) default NULL,
`e` int(255) default NULL,
`f` int(255) default NULL,
`g` int(255) default NULL,
`h` int(255) default NULL,
PRIMARY KEY (`name`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
INSERT INTO `tb_xttj` VALUES ('John', '4', '4', '5', '4', '3', '2', '1', null);
INSERT INTO `tb_xttj` VALUES ('Mary', '3', '4', '4', '2', '5', '4', '3', null);
INSERT INTO `tb_xttj` VALUES ('Lucy', '2', '3', null, '3', null, '3', '4', '5');
INSERT INTO `tb_xttj` VALUES ('Tom', '3', '4', '5', null, '1', '3', '5', '4');
INSERT INTO `tb_xttj` VALUES ('Bill', '3', '2', '1', '5', '3', '2', '1', '1');
INSERT INTO `tb_xttj` VALUES ('Leo', '3', '4', '5', '2', '4', null, null, null);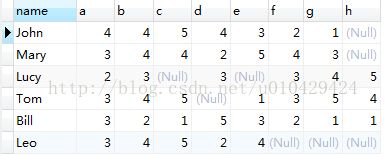 我这里只对最后一行的Leo进行推荐,看看f,g,h哪个可以推荐给他。
我这里只对最后一行的Leo进行推荐,看看f,g,h哪个可以推荐给他。
用php+mysql,流程图如下:

连接数据库并将其存储为二维数组的代码如下:
header("Content-Type:text/html;charset=utf-8");
mysql_connect("localhost","root","admin");
mysql_select_db("geodatabase");
mysql_query("set names 'utf8'");
$sql = "SELECT * FROM tb_xttj";
$result = mysql_query($sql);
$array = array();
while($row=mysql_fetch_array($result))
{
$array[]=$row;//$array[][]是一个二维数组
} 问题1:这一步完全可以看做是整表查询,这种查询是大忌,对于这种小小的演示系统还可以,但是对大数据的系统,没有效率,至于如何改进,还得多学习才是。
求Leo与其他人的Cos值代码如下:
/*
* 以下示例只求Leo的推荐,如此给变量命名我也是醉了;初次理解算法,先不考虑效率和逻辑的问题,主要把过程做出来
*/
$cos = array();
$cos[0] = 0;
$fm1 = 0;
//开始计算cos
//计算分母1,分母1是第一个公式里面 “*”号左边的内容,分母二是右边的内容
for($i=1;$i<9;$i++){
if($array[5][$i] != null){//$array[5]代表Leo
$fm1 += $array[5][$i] * $array[5][$i];
}
}
$fm1 = sqrt($fm1);
for($i=0;$i<5;$i++){
$fz = 0;
$fm2 = 0;
echo "Cos(".$array[5][0].",".$array[$i][0].")=";
for($j=1;$j<9;$j++){
//计算分子
if($array[5][$j] != null && $array[$i][$j] != null){
$fz += $array[5][$j] * $array[$i][$j];
}
//计算分母2
if($array[$i][$j] != null){
$fm2 += $array[$i][$j] * $array[$i][$j];
}
}
$fm2 = sqrt($fm2);
$cos[$i] = $fz/$fm1/$fm2;
echo $cos[$i]."
";
}
将求好的Cos值排序,采用快排代码如下(百度copy而来):
//对计算结果进行排序,凑合用快排吧先
function quicksort($str){
if(count($str)<=1) return $str;//如果个数不大于一,直接返回
$key=$str[0];//取一个值,稍后用来比较;
$left_arr=array();
$right_arr=array();
for($i=1;$i=$key)
$left_arr[]=$str[$i];
else
$right_arr[]=$str[$i];
}
$left_arr=quicksort($left_arr);//进行递归;
$right_arr=quicksort($right_arr);
return array_merge($left_arr,array($key),$right_arr);//将左中右的值合并成一个数组;
}
$neighbour = array();//$neighbour只是对cos值进行排序并存储
$neighbour = quicksort($cos); 这里的$neighbour数组仅仅存储了从大到小排序好的Cos值,并没有与人联系起来。这个问题还要解决。
选出Cos值最高的3个人,作为Leo的邻居:
//$neighbour_set 存储最近邻的人和cos值
$neighbour_set = array();
for($i=0;$i<3;$i++){
for($j=0;$j<5;$j++){
if($neighbour[$i] == $cos[$j]){
$neighbour_set[$i][0] = $j;
$neighbour_set[$i][1] = $cos[$j];
$neighbour_set[$i][2] = $array[$j][6];//邻居对f的评分
$neighbour_set[$i][3] = $array[$j][7];//邻居对g的评分
$neighbour_set[$i][4] = $array[$j][8];//邻居对h的评分
}
}
}
print_r($neighbour_set);
echo "
";
这一步得到的结果是酱紫:
![]()
这是一个二维数组,数组第一层的下标为0,1,2,代表3个人。第二层下标0代表邻居在数据表中的顺序,比如Jhon是表中的第0个人;下标1代表Leo和邻居的Cos值;下标2,3,4分别代表邻居对f,g,h的评分。
开始进行预测,计算Predict代码如下:
我是分别计算Leo对f,g,h的预测值。在此有一个问题,就是如果有的邻居对f,g,h的评分为空,那么该如何处理。比如Jhon和Mary对h的评分就为空。本能的想到用if判断一下,如果为空则跳过这组计算,不过这样处理是否合理,有待考虑。以下代码并没有写出这个if判断。
//计算Leo对f的评分
$p_arr = array();
$pfz_f = 0;
$pfm_f = 0;
for($i=0;$i<3;$i++){
$pfz_f += $neighbour_set[$i][1] * $neighbour_set[$i][2];
$pfm_f += $neighbour_set[$i][1];
}
$p_arr[0][0] = 6;
$p_arr[0][1] = $pfz_f/sqrt($pfm_f);
if($p_arr[0][1]>3){
echo "推荐f";
}
//计算Leo对g的评分
$pfz_g = 0;
$pfm_g = 0;
for($i=0;$i<3;$i++){
$pfz_g += $neighbour_set[$i][1] * $neighbour_set[$i][3];
$pfm_g += $neighbour_set[$i][1];
$p_arr[1][0] = 7;
$p_arr[1][1] = $pfz_g/sqrt($pfm_g);
}
if($p_arr[0][1]>3){
echo "推荐g";
}
//计算Leo对h的评分
$pfz_h = 0;
$pfm_h = 0;
for($i=0;$i<3;$i++){
$pfz_h += $neighbour_set[$i][1] * $neighbour_set[$i][4];
$pfm_h += $neighbour_set[$i][1];
$p_arr[2][0] = 8;
$p_arr[2][1] = $pfz_h/sqrt($pfm_h);
}
print_r($p_arr);
if($p_arr[0][1]>3){
echo "推荐h";
}$p_arr是对Leo的推荐数组,其内容类似如下;
Array ( [0] => Array ( [0] => 6 [1] => 4.2314002228795 ) [1] => Array ( [0] => 7 [1] => 2.6511380196197 ) [2] => Array ( [0] => 8 [1] => 0.45287424581774 ) )
f是第6列,Predict值是4.23,g是第七列,Predict值是2.65........
求完了f,g,h的Predict值后有两种处理方式:一种是将Predict值大于3的物品推荐给Leo,另一种是将Predict值从大到小排序,将Predict值大的前2个物品推荐给Leo。这段代码没有写。从上面的示例中可以看出,推荐算法的实现非常麻烦,需要循环,判断,合并数组等等。如果处理不当,反而会成为系统的累赘。在实际处理中还有以下问题:
1.以上示例我们只对Leo进行推荐,而且我们已经知道Leo没有评价过f,g,h物品。如果放到实际的系统里,对于每一个需要进行推荐的用户,都要查询出他没有评价过哪些物品,这又是一部分开销。
2.不应当进行整表查询,在实际系统中可以设定一些标准值。比如:我们求Leo与表中的其他人的Cos值,如果该值大于0.80,则表示可以为邻居。这样,当我找到10个邻居之后,就停止求Cos值,避免整表查询。对于推荐物品也可以适当采用此方法,比如,我只推荐10个物品,推荐完后就停止求Predict值。
3.随着系统的使用,物品也会发生变化,今天是fgh,明天没准就是xyz了,当物品变化时,需要动态的改变数据表。
4.可以适当引进基于内容的推荐,来完善推荐算法。
5.推荐的精确性问题,这个设置不同的标准值,会影响精确性。
总结:我觉得本质的问题是算法的效率就不高,继续学习,看看有没有更好的协同过滤推荐算法。