Transformer详解
目录
模型结构
Attention
放缩点积Attention(Scaled Dot-Product Attetion)
多头Attention(Multi-Head Attention)
Transformer中的Attention
嵌入和Softmax
位置编码
使用Self-Attention的原因
Transformer内部细节
Encoder内部细节
残差网络
Encoder过程
层归一化
Encoder和Decoder之间细节
Encoder-Decoder attention 与self-attention mechanism的区别:
multi-head self-attention mechanism具体的计算过程
Decoder工作细节
The Final Linear and Softmax Layer
模型结构
Encoder:编码器由N = 6 个完全相同的层堆叠而成。每一层都有两个子层。第一个子层是一个multi-head self-attention机制,第二个子层是一个简单的、位置完全连接的前馈网络。我们对每个子层再采用一个残差连接,接着进行层标准化。也就是说,每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x) 是由子层本身实现的函数。为了方便这些残差连接,模型中的所有子层以及嵌入层产生的输出维度都为dmodel = 512。
Decoder:解码器同样由N = 6 个完全相同的层堆叠而成。 除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该层对Encoder堆栈的输出执行multi-head attention。 与编码器类似,我们在每个子层再采用残差连接,然后进行层标准化。我们还修改解码器堆栈中的self-attention子层,以防止位置关注到后面的位置。这种掩码结合将输出嵌入偏移一个位置,确保对位置的预测 i 只能依赖小于i 的已知输出。
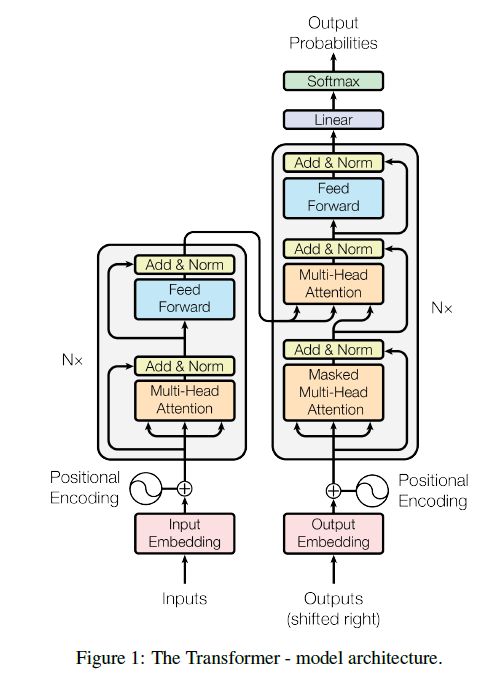
Transformer其实这就是一个Seq2Seq模型,左边一个encoder把输入读进去,右边一个decoder得到输出:
Transformer=Transformer Encoder + Transformer Decoder
Attention
放缩点积Attention(Scaled Dot-Product Attetion)
在实践中,同时计算一组query的Attention函数,并将它们组成一个矩阵Q,key和value也组成矩阵K和V,输出矩阵为

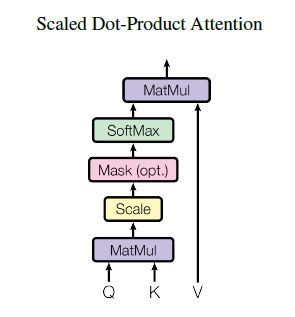
相较于加法Attention,在实践中点积Attention速度更快,更节省空间,因为其使用矩阵乘法实现计算过程。
当![]() 较小时,加法Attention和点积Attention性能相近;但
较小时,加法Attention和点积Attention性能相近;但![]() 较大时,加法Attention性能优于不带缩放的点积Attention。
较大时,加法Attention性能优于不带缩放的点积Attention。
原因:对于很大的![]() ,点积幅度增大,将softmax函数推向具有极小梯度的区域,为抵消这种影响,在Transformer中点积缩小
,点积幅度增大,将softmax函数推向具有极小梯度的区域,为抵消这种影响,在Transformer中点积缩小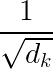 倍。
倍。
多头Attention(Multi-Head Attention)

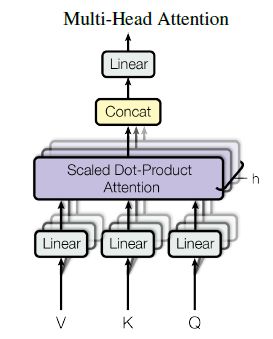
多头Attention的优点:
1、可以允许模型在不同的表示子空间里学习到相关的信息。在Transformer中有8个头,维持多个Query、Key、Value权重矩阵,这些矩阵都是随机初始化生成的,然后通过训练,用于将词嵌入投影到不同的表示子空间中。
2、拓展了模型关注不同位置的能力。

Transformer中的Attention
在Transformer中以3种方式使用Multi-Head Attention
1、在“Encoder-Decoder Attention”层,query来自上面的解码器层,key和value来自编码器的输出。这允许解码器中的每个位置能关注到输入序列中的所有位置。这模仿Seq2Seq模型中典型的Encoder-Decoder的attention机制
2、Encoder包含self-attention层。在self-attention层中,所有的key、value和query来自同一个地方,在这里是Encoder中前一层的输出。编码器中的每个位置都可以关注编码器上一层的所有位置。
3、Decoder中的self-attention层允许解码器中的每个位置都关注解码器中直到并包括该位置的所有位置(即Decoder中每个位置关注该位置及前面所有位置的信息)。我们需要防止解码器中的向左信息流来保持自回归属性。通过屏蔽softmax的输入中所有不合法连接的值(设置为-∞),我们在缩放版的点积attention中实现。
![]()
尽管线性变换在不同位置上是相同的,但它们层与层之间使用不同的参数。 它的另一种描述方式是两个内核大小为1的卷积。输入和输出的维度为![]() ,内部层的维度为
,内部层的维度为![]() 。
。
嵌入和Softmax
与其他序列转导模型类似,我们使用学习到的嵌入将输入词符和输出词符转换为维度为![]() 的向量。我们还使用普通的线性变换和softmax函数将解码器输出转换为预测的下一个词符的概率。在我们的模型中,两个嵌入层之间和pre-softmax线性变换共享相同的权重矩阵。在嵌入层中,我们将这些权重乘以
的向量。我们还使用普通的线性变换和softmax函数将解码器输出转换为预测的下一个词符的概率。在我们的模型中,两个嵌入层之间和pre-softmax线性变换共享相同的权重矩阵。在嵌入层中,我们将这些权重乘以![]()

位置编码

使用Self-Attention的原因
使用Self-Attention主要解决三个问题
1、每层计算的总复杂度
2、可以并行的计算量,以所需的最小顺序操作的数量来衡量
3、网络中长距离依赖之间的路径长度。影响学习这种依赖性能力的一个关键因素是前向和后向信号必须在网络中传播的路径长度。输入和输出序列中任意位置组合之间的这些路径越短,学习远距离依赖性就越容易。
因此,我们还比较了由不同图层类型组成的网络中任意两个输入和输出位置之间的最大路径长度。
n 为序列的长度,d 为表示的维度,k 为卷积的核的大小,r 为受限self-attention中邻域的大小。

Transformer内部细节
Encoder内部细节
Transformer Encoder(N=6层,每层包括2个sub-layers)

将每个单词编码为512维的向量,词嵌入只发生在最底层的Encoder
在每个单词进入Self-Attention层后都会有一个对应的输出。Self-Attention层中的输入和输出是存在依赖关系的,而前馈层则没有依赖,所以在前馈层,我们可以用到并行化来提升速率。

sub-layer-1:multi-head self-attention mechanism,用来进行self-attention。
sub-layer-2:Position-wise Feed-forward Networks,简单的全连接网络,对每个position的向量分别进行相同的操作,包括两个线性变换和一个ReLU激活输出(输入输出层的维度都为512,中间层为2048)
![]()
残差网络
每个sub-layer都使用了残差网络:![]() 。
。
残差网络:在正常的前向传播基础上开一个绿色通道,这个通道里x可以无损通过。避免了梯度消失(求导时多了一个常数项)。注意,这里输入进来的时候做了个norm归一化。

Encoder过程
1、输入x(512)
2、x做一个层归一化: x1 = norm(x)(512)
3、进入多头self-attention: x2 = self_attn(x1)(512)
4、残差加成:x3 = x + x2(1024)
5、再做个层归一化:x4 = norm(x3)(1024)
6、经过前馈网络: x5 = feed_forward(x4)(1024)
7、残差加成: x6 = x3 + x5(2048)
8、输出x6
层归一化
BatchNormalization的缺点:
1、对BatchSize非常敏感。BatchNormalization的一个重要出发点是保持每层输入的数据同分布。回想下开始那个独立同分布的假设。假如取的batch_size很小,那显然有些Mini-Batch的数据分布就很可能与整个数据集的分布不一致了,又出现了那个问题,数据分布不一致,这就等于说没起到同分布的作用了,或者说同分布得不充分。实验也证明,batch_size取得大一点, 数据shuffle的好一点,BatchNormalization的效果就越好。
2、对RNN不适合。对所有样本求均值。对于图片这类等长的输入来说,这很容易操作,在每个维度加加除除就可以了,因为维度总是一致的。而对于不等长的文本来说,RNN中的每个time step共享了同一组权重。在应用BatchNormalization时,这就要求对每个time step的batch_size个输入计算一个均值和方差。那么问题就来了,假如有一个句子S非常长,那就意味着对S而言,总会有个time_step的batch_size为1,均值方差没意义,这就导致了BatchNormalization在RNN上无用武之地了。
LayerNormalization:
不再对Mini-Batch中的N的样本在各个维度做归一化,而是针对同一层的所有神经元做归一化。


其中,H指的是一层神经网络的神经元个数。我们再回想下BatchNormalization,其实它是在每个神经元上对batch_size个数据做归一化,每个神经元的均值和方差均不相同。而LayerNormalization则是对所有神经元做一个归一化,这就跟batch_size无关了。哪怕batch_size为1,这里的均值和方差只和神经元的个数有关系

示意了两种方式的区别。假设有N个样本,每个样本的特征维度为4,图中每个小圆代表一个特征,特征1,特征2等等,特征4。BatchNormalization是在N个同一特征(如特征1)上求均值和方差,这里要对每个特征求1次,共4次。对照一下上面说的,万一有个样本有5个特征,是不是就没法玩了。LayerNormalization呢,别的样本都和我没啥关系,有多少个特征我把这些特征求个均值方差就好了。这也就是为什么一个叫”批归一化“,另一个叫”层归一化“了。理解了这一点,也就理解了为什么Transformer中使用LN而不是BN。
Encoder和Decoder之间细节
如果做堆叠了2个Encoder和2个Decoder的Transformer,那么它可视化就会如下图所示:

sub-layer-1:Masked multi-head self-attention mechanism,用来进行self-attention,与Encoder不同:由于是序列生成过程,所以在时刻 i 的时候,大于 i 的时刻都没有结果,只有小于 i 的时刻有结果,因此需要做Mask。
sub-layer-2:Encoder-Decoder attention计算。
sub-layer-3:Position-wise Feed-forward Networks,同Encoder。
Encoder-Decoder attention 与self-attention mechanism的区别:
它们都是用了 multi-head计算,不过Encoder-Decoder attention采用传统的attention机制,其中的Query是self-attention mechanism已经计算出的上一时间i处的编码值,Key和Value都是Encoder的输出,这与self-attention mechanism不同。
multi-head self-attention mechanism具体的计算过程

Transformer中的Attention机制由Scaled Dot-Product Attention和Multi-Head Attention组成,上图给出了整体流程。下面具体介绍各个环节:
Expand:实际上是经过线性变换,生成Q、K、V三个向量;
Split heads: 进行分头操作,在原文中将原来每个位置512维度分成8个head,每个head维度变为64;
Self Attention:对每个head进行Self Attention,具体过程和第一部分介绍的一致;
Concat heads:对进行完Self Attention每个head进行拼接;
Decoder工作细节
Decoder应用阶段:Decoder阶段中的每个步骤输出来自输出序列的元素(在这种情况下为英语翻译句子)
当序列输入时,Encoder开始工作,最后在其顶层的Encoder输出矢量组成的列表,然后我们将其转化为一组attention的集合(K,V)。(K,V)将带入每个Decoder的“encoder-decoder attention”层中去计算(这样有助于decoder捕获输入序列的位置信息)
训练阶段:直到输出一个特殊符号
图片参考
Decoder中的self-attention与Encoder的self attention略有不同:
在Decoder中,self-attention只关注输出序列中的较早的位置。这是在self-attention计算中的softmax步骤之前屏蔽了特征位置(设置为 -inf)来完成的。
“Encoder-Decoder Attention”层的工作方式与"Multi-Headed Self-Attention"一样,只是它从下面的层创建其Query矩阵,并在Encoder堆栈的输出中获取Key和Value的矩阵。
The Final Linear and Softmax Layer
最终的线性层和softmax层所做的工作:Decoder的输出是浮点数的向量列表,将其变成一个单词
线性层是一个简单的全连接神经网络,它是由Decoder堆栈产生的向量投影到一个更大,更大的向量中,称为对数向量
假设实验中我们的模型从训练数据集上总共学习到1万个英语单词(“Output Vocabulary”)。这对应的Logits矢量也有1万个长度-每一段表示了一个唯一单词的得分。在线性层之后是一个softmax层,softmax将这些分数转换为概率。选取概率最高的索引,然后通过这个索引找到对应的单词作为输出。
Transformer在GPT和Bert等词向量预训练模型中的应用
1、GPT中训练的是单向语言模型,其实就是直接应用Transformer Decoder;
2、Bert中训练的是双向语言模型,应用了Transformer Encoder部分,不过在Encoder基础上还做了Masked操作;
BERT Transformer 使用双向self-attention,而GPT Transformer 使用受限制的self-attention,其中每个token只能处理其左侧的上下文。双向 Transformer 通常被称为“Transformer encoder”,而左侧上下文被称为“Transformer decoder”,decoder是不能获要预测的信息的。
参考大佬的博客:
图解Transformer
最后如果转载,麻烦留个本文的链接,因为如果读者或我自己发现文章有错误,我会在这里更正,留个本文的链接,防止我暂时的疏漏耽误了他人宝贵的时间。