前言
本篇文章出自CVPR2017,四名作者为Tsinghua University,Peking University, 外加两名来自Megvii(旷视科技)的大佬。 文章中对能够帮助行人检测的extra features做了诸多分析,并且提出了HyperLearner行人检测框架(基于Faster R-CNN改进),在KITTI&Caltech&Cityscapes数据集上实现了极为优秀的性能。
论文:http://openaccess.thecvf.com/content_cvpr_2017/papers/Mao_What_Can_Help_CVPR_2017_paper.pdf
正文
行人检测出了什么问题?
无疑,行人检测在步态识别、智能视频监控和自动驾驶等领域发挥着重要作用。作者在文中指出,虽然近年来深度卷积网络在通用目标检测上取得了巨大的进步,但在行人检测领域的研究仍有两大主要挑战:
(1)首先,相比一般的物体,行人与背景的辨识度更小。 
如上图,行人在杂乱的背景带来难以区分的负样本,如交通标志、邮筒等。它有非常相似的表观特征与行人。没有额外的语义上下文,使用这种低分辨率输入的检测器无法区分它们,从而导致召回率的降低和误报的增加。
(2)如何准确定位每一个行人。行人在拥挤的场景中站得很近,给定位每个个体带来挑战。而对于深度卷积网络来说,这个问题变得更糟了,因为卷积和池化生成高层次的语义激活映射,它们也模糊了靠得近的行人之间的边界。
用额外特征改善行人检测器
相关改进:
作者考虑用额外的特征来提升CNN-based pedestrian detectors的性能。这些特征归类如下: 
(1)apparent-to-semantic channels(如梯度、边缘、像素分割、热力信息通道)
(2)temporal channels (时间序列通道,在文中为相邻时间帧中提取光流通道)
(3)depth channels (深度通道)
此外,作者对作为基本框架的Faster R-CNN做了相关改进:将原来anchor的 3 scales&3 ratios 增加到 5 scales&7 ratios,即一个anchor中心点可以对应为35个box;考虑到行人区域小,为了获得更高分辨率的信息,除去了所有的conv5层。
整合方案:
如何将额外的特征送入网络中?作者在VGG-16的主体网络上添加了一个新的分支网络。文章中介绍称,这个网络由一些卷积层(kernel size 3, padding 1 and stride 1)和池化层(kernel size 2 and stride 2)组成,输出为128通道的特征,1/8原图像的大小,而后与主体网络中输出的特征级联起来,再送入RPN。如图: 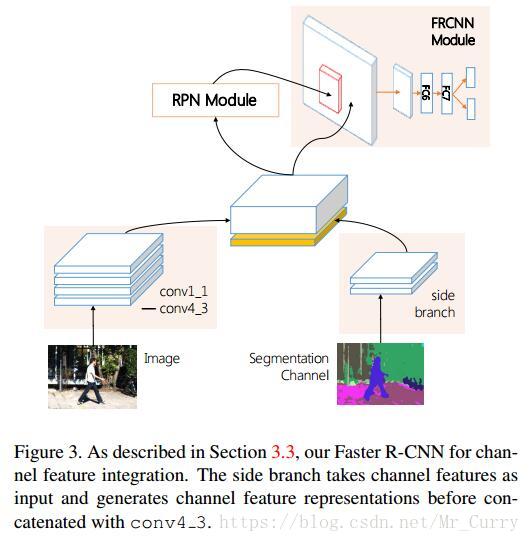
得出的结论是,在KITTI数据集上,所有的集成方法都提高了Faster R-CNN检测器的性能。 
比较分析:
作者进行了两个尺度的实验(1x and 2x,这里指的是图像比例),下表为实验结果。 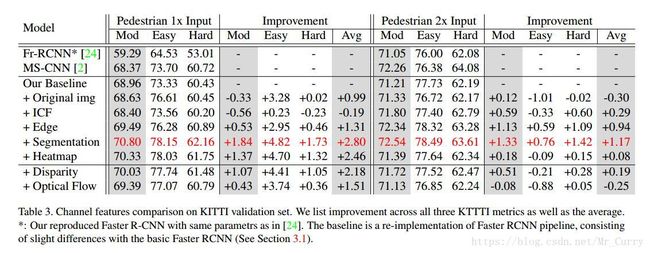
在1x和2x实验中,semantic information都表现出了更好的性能。在2x试验中,高层语义信息但没有低级的明显特征(即热图通道)未能超过1X的实验的效果。作者认为,当图像以大的scale输入时,低级别的细节将显示出更大的重要性。随后的验证实验也证实了这一想法。
HyperLearner
原理:
将不同通道的特征强行整合虽然有利于提升性能,但相对于原生的Faster R-CNN,在计算成本上变的更为昂贵。由于许多的通道特征都是可以用CNN生成的(如semantic segmentation and edge),于是,作者想要教会CNN生成通道特征,并且实现行人检测。 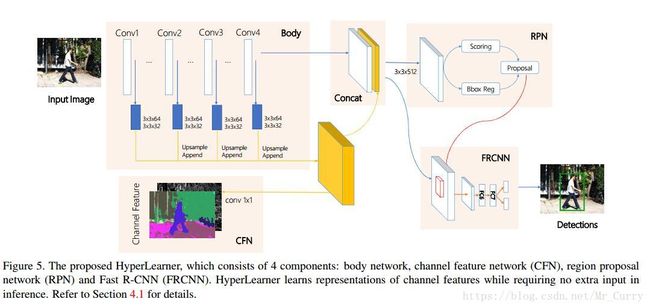
HyperLearner的框架由四部分组成:提取原图特征的body network,通道特征的网络(CFN),区域建议网络(RPN)和用于最终检测认为的Fast R-CNN(FRCNN)网络。
类似于HyperNet,作者提取提取层conv1_2,conv2_2,conv3_3和conv4_3的特征,并进行汇聚(黄色部分的特征图)。而CFN通过一个完全卷积结构,直接让聚合激活图生成预测的通道特征图。RPN和FRCNN与Faster R-CNN中的网络同理。在训练时,是需要一张额外的通道特征图作为监督的。而在测试时,如图所示,黄色的那部分特征图其实就相当于其它通道提取的特征,与body network concat一下即可。
训练:
作者采用了Multi-stage training的方法。整个训练阶段分为四个阶段。
在第一阶段,只有CFN的优化。详细来说,修正所有参数(conv1_1到conv4_3),并放弃训练RPN和FRCNN。
在第二阶段,我们将整个body network(包括聚合激活图卷积层)和CFN,只训练RPN。
第三阶段,CFN和RPN是固定的;只有FRCNN优化。
最后阶段,所有层都是联合优化的。
实验
实验结果可以说是非常暴力了。在KITTI&Caltech dataset&Cityscapes上都实现了极为优越的性能。
KITTI: 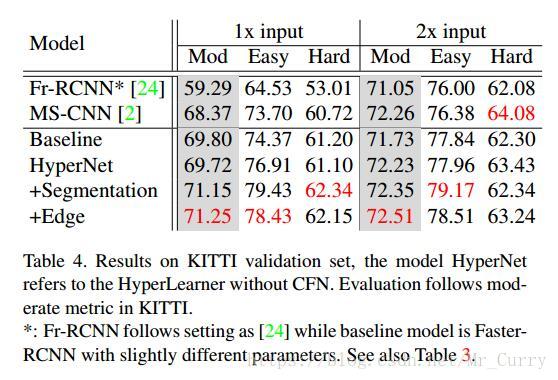
Cityscapes: 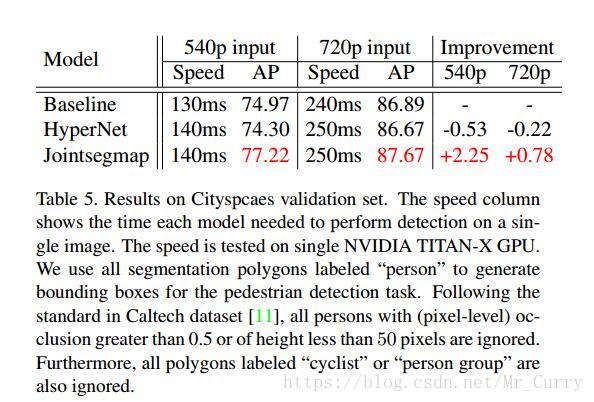
Caltech dataset: 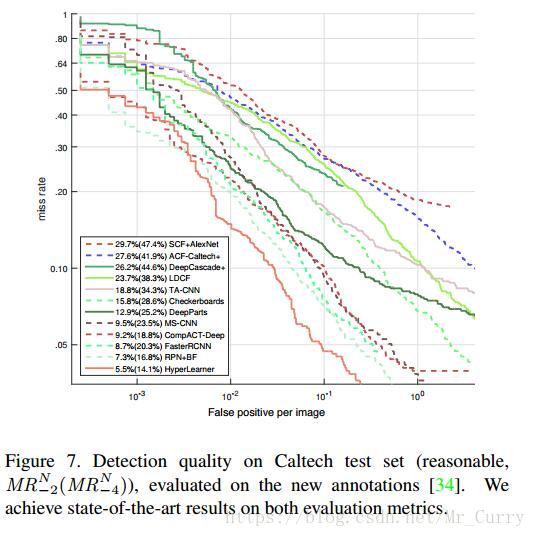
总结
为了利用额外特征提升检测器性能,同时解决计算成本问题,文中提出了一个新的框架HyperLearner,以共同学习通道特征和完成行人检测。HyperLearner能够学习通道特征的表示,同时不需要额外的推理输入,在几个数据集上有着显著的改进。
感谢您的阅读,文中的疏漏与错误,恳请批评指正。