难得跟了一次热点,从看到论文到现在已经过了快三周了,又安排了其他方向,觉得再不写又像之前读过的N多篇一样被遗忘在角落,还是先写吧,虽然有些地方还没琢磨透,但是paper总是这样吧,毕竟没有亲手实现一下,光是看永远无法理解透彻,然后又去忙别的工作,看过的都打了水漂。
第六章 EIE-用于稀疏神经网络的高效推理引擎
目测和发在ISCA2016的论文EIE: Efficient Inference Engine on Compressed Deep Neural Network 内容一致,补了一些图。是一个神经网络加速器,用硬件加速训练好的网络模型。
6.1 Introduction
为了评估EIE性能,为其建立了行为级描述和RTL级模型,并对RTL模型进行了综合和布局布线,以获得精确的功耗与时钟频率。在9个DNN benchmarks上的结果显示,EIE比未压缩的CPU快189倍,GPU快13倍。EIE在稀疏网络上的处理能力达102GOPS/s,相当于稠密网络3TOPS/s,而功耗只有600mW。
6.2 稀疏神经网络并行化
稀疏神经网络计算并行化的一种简单的方式是将稀疏矩阵恢复为稠密矩阵,然后通过稠密线性代数并行化技术加速计算。可以通过门控,跳过0操作来降低计算能耗。然而,此方法只能降低功耗,无法节省计算周期。因此,我们选择直接在稀疏模型上进行计算,可以同时节省计算时间和功耗。
6.2.1 计算
深度神经网络中的每一层通过计算b=f(Wa+v)实现,将偏置v合并到权值W里,并为向量a添加一个全1项,公式可写成如下格式:

这里a、b下标都是一维的(因为刚开始接触神经网络就是CNN,直接以为是卷积计算了,这里不是的,只是权值矩阵和向量a的点乘),形象化点的图:

深度压缩通过剪枝和权值共享对DNN进行压缩,剪枝使权值矩阵W变得稀疏,约能压缩4%~25%。权值共享将每个权值Wij用一个4bit索引Iij查找共享的向量表S,S里是16个可能的权值(S也是4bit,从0x0~0xF)。通过深度压缩,上述等式变为如下形式:
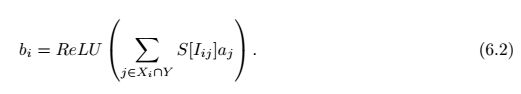
其中X是经过稀疏以后的权值W,是静态的,对于给定的模型,不会发生变化;Y是经过稀疏以后的输入a,随着输入的变化而变化。
对比公式6.1和6.2,主要两点不同:1. 用查找表S替代权值矩阵W的存储;2. 只对权值和输入同时非零的情况进行计算。
6.2.2 表达
将稀疏权值矩阵W用CSC格式存储,用v表示非0的权值,z表示索引,当两个非零权值相隔超过15时补一个0,如下所示:
![]()
![]()
再将所有的v和z成对地装在一个大数组里,用一个指针向量p进行索引,pj指向第j列的开始。
6.2.3 并行化
将一个权值矩阵拆分到N个PE里同时计算,稀疏矩阵*稀疏向量的实现方法:扫描稀疏向量a,查找其内部非零值,将非零值aj的索引j广播到每个PE,然后每个PE根据其对应的权值是否为零决定是否进行计算。举一个16行8列权值矩阵计算的例子:

对应的并行计算方式如下:

权值W按6.2.2描述的方式进行表达,并且是每个PE内排序,而不是整个W矩阵排序,作者给了个PE0的CSC示意图:

这里,W8,0和W0,0之间只隔了一个W4,0,如下所示:

6.3 硬件实现
EIE的结构如下,图(a)用于查找非零输入,图(b)是EIE中一个PE的结构:
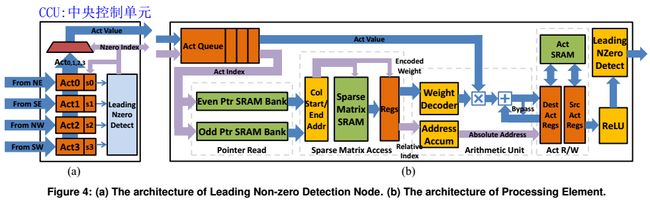
这个图画的很清晰,紫色是索引(地址流),蓝色是数据(数据流);绿色方框存储器,橙色方框寄存器。
除了非零输入的查找并广播到所有PE这一过程(图a),几乎其他所有计算都在独立的PE内部。但是由于大部分PE都需要对每个非零输入进行多周期计算,非零输入的查找与广播并不是关键路径(不local就不local吧,反正要等PE计算完,这个慢一点没关系)。
6.3.1 激活队列与负载平衡(对应模块Act Queue)
负载不平衡的问题描述(这一段毕业论文有,ISCA没有):
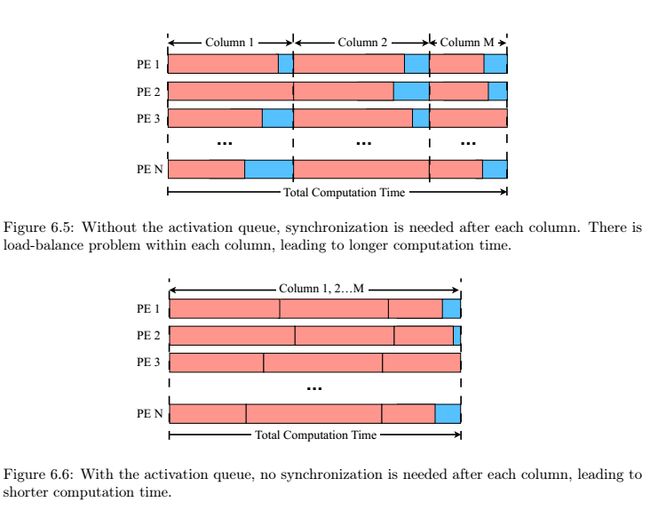
相当于木桶效应,只能等计算量最大,跑的最慢的PE计算完成才能完成一次计算,解决方案有两种负载平衡策略:
- 全局负载平衡在第三章剪枝中描述,用于处理非零元素在整个矩阵中分布不均匀的情况;
- 局部负载平衡使用队列将被挂起的任务进行排队,用于处理非零元素在矩阵某一列中分布不均匀的情况。
EIE为每个PE设计一个激活队列,有了这个激活队列以后,只要所有PE里的激活队列不满,CCU都可以放肆地广播新的非零输入;只要PE里的激活队列不空,该PE也可以任性地计算。
如果不使用队列的话,每完成一列计算,所有PE都需要同步一次,如图6.5,跑的快的PE就需要插入延时槽(蓝色)以等待跑的慢的PE。使用了队列以后如图6.6,只有队列排满或变空时才需要插入延时槽了,这里涉及到体系结构设计里的面积换速度问题:队列大,延时槽少,占用资源多但速度快;反之,如果使用的队列小,延时槽相应会增多,导致速度慢。
6.3.2 指针读取单元(对应模块Pointer Read)
读取p
6.3.3 稀疏矩阵读取单元(对应模块Sparse Matrix Access)
根据p读取W,
6.3.4 计算单元(对应模块Arithmetic Unit )
实现操作: bx = bx+v*aj,把上一节取到的W和发射队列里的aj乘起来,并根据取到的x和对应的bx累加,再送到对应的寄存器(x就是用来索引这个寄存器的)。这里还增加了bypass,如果相邻两个计算要写的是同一个目的寄存器,就直接通过旁路给过来,又可以节省一个读等待的时间。
6.3.5 激活神经元读写单元(对应模块Act R/W)
根据索引x读写bx数据,此单元设计双缓冲(包含两组寄存器文件),可以保存本层的计算结果,同时还可以作为下一层的输入,从而实现多层前向计算。
6.3.6 分布式LNZD(对应模块LNZD)
这个因为神经网络计算方式,本层计算结果作为下一层的计算输入,激活神经元要被分发到多个PE里乘以不同的权值(神经网络计算中,上一层的某个神经元乘以不同的权值并累加,作为下一层神经元),Leading非零值检测是说检测东南西北四个方向里第一个不为0(激活)的神经元,就是每个PE都接受东南西北4个方向来的输入,这4个输入又分别是其他PE的输出,是需要计算的,那我这个PE计算时取哪个方向来的数据呢?用LNZD判断,谁先算完就先发射谁,尽量占满流水线。
PE之间用H-tree结构,可以保证PE数量增加时布线长度以log函数增长(增长最缓慢的形式),来自维基百科:
6.3.7 中央控制单元(CCU)
根节点(输入层)上的LNZD作为中央控制单元,配合CPU工作,接收CPU指令,发给PE。两种工作方式:I/O和计算。
I/O模式下,每个PE处于idle态,等待DAM把权值和神经元初值写入片上内存,这个属于一次性开销(每层计算只需要这样load一次);
计算模式下,CCU不停地通过四叉树LNZD查找非零值并广播到所有的PE,控制PE进行计算,直到达到输入长度。
CPU可以通过给定不同输入长度和起始地址,使EIE实现神经网络中不同的层的计算。
6.4 评估方法
1. 用C++实现了模拟器,把每个硬件模块抽象成一个对象,具有两种行为:传递和更新,分别对应RTL模型中的运算逻辑和翻转。该模拟器可用于体系结构设计空间搜索,同时也是RTL验证的黄金模型。
2. 为了测量面积、功耗和关键路径延时,用Verilog实现了RTL模型,并用仿真器进行了逻辑验证。然后使用Synopsys的IC编译器对45nm的工艺库进行布局布线,用Cacti对SRAM的面积和功耗进行计算,再将RTL仿真结果标到门级网标(这块涉及前仿,不是很了解,总之是用来计算如果设计成45nm工艺,性能如何)。
使用压缩前和压缩后的9个DNN模型(包括Alex、VGG、LSTM网络)分别和Core-i7 CPU、Titan X GPU以及移动GPU做了对比。
6.5 实验结果
关键路径延时设为1.15ns(870Mhz),神经元的一次激活划分为4级流水线:1)。通过访问局部寄存器对激活神经元进行读写,通过旁路技术避免流水线冲突。使用800M*64PE可实现超过102GOP/s的性能,再考虑到10倍的权值稀疏和3倍的激活神经元稀疏,需要处理能力达3TOP/s的dense DNN加速器才能达到等量吞吐性能。
每个PIE PE的SRAM容量为162KB,激活神经元SRAM2KB,用于存储权值及其索引的Spmat SRAM 128KB,每个权值4bit,其索引4bit,将权值和索引合并为8bit/组并一起寻址,
6.6 讨论
本节是对不同设计方案的讨论,都是用数据说话。
6.6.1 划分方式
稀疏矩阵乘是EIE的关键部件,这一节讨论三种划分方式的优缺点。
列划分:好处是一个aj对应一个PE,不用广播了,但是如果一个aj=0,对应的一列计算都省了,会导致忙的PE累死,闲的PE闲死。
行划分:本文的方式。
混合划分方式:行列划分矩阵W,所有PE构成2维阵列并行计算,适合通讯代价大的分布式系统,设计复杂度高。
6.6.2 可扩展性
6.7 结论
即是专用芯片,能效比肯定是相当好,跟GPU相比,对典型全连接层计算可节省3400倍的功耗。跟CPU、mobile GPU比也是绝对的碾压。
第七章 结论
觉得论文最后一段很是感人,贴在这里,向男神学习。
