FCOS: Fully Convolutional One-Stage Object Detection(ICCV2019)论文笔记
目录
论文
摘要
1、引言
2、相关文献
anchor based模型
anchor free模型
3、方法
3.1 全卷积单阶段目标检测器
3.2 FCOS的FPN多层级预测
训练
预测
复现-ing-未完待续(链接)
建模
https://zhuanlan.zhihu.com/p/136172670
https://blog.csdn.net/WZZ18191171661/article/details/89258086
https://zhuanlan.zhihu.com/p/65459972
论文
摘要
提出全卷积单阶段目标检测器FCOS,在像素级预测中解决目标检测问题,类似于语义分割。几乎所有的sota目标检测器,如:RetinaNet、SSD、YOLOv3、Faster R-CNN都依赖于预定义的anchor框,而我们的FCOS是anchor free的,而且是proposal free的,完全避免了和anchor框相关的复杂计算(IOU),降低了计算内存占用。更重要的是,我们也避免了和anchor框相关的对检测性能非常敏感对所有超参数。经过NMS后处理,我们的FCOS比基于anchor的单阶段检测器要表现出色,且更加简单。我们首次证明了一种更简单、更灵活的检测框架,并且提升了检测效果。我们希望所提出的FCOS能成为其他实例级任务的强有力的替代品。https://github.com/tianzhi0549/FCOS/
1、引言
目标检测是一项基本但也富有挑战的计算机视觉任务,它需要一套算法来为图像上的每个实例预测一个带有类别标签的边界框。所有当前主流的检测器诸如Faster R-CNN、SSD、YOLOv3,都依赖于预定义的anchor集合,并且一直被认为是目标检测成功的关键点。尽管基于anchor的方法获得了巨大的成功,仍然有必要提出该方法的几个缺点:
1、如[12],[20]所述,检测性能对anchor的尺寸、宽高比、数量十分敏感。比如RetinaNet中,调整超参数能够影响4%的AP在COCO数据集上。因此对于anchor的超参数需要细致调整。
2、即使经过的精心的设计,由于anchor框的尺寸和宽高比是固定的,检测模型会难以处理尺度变化很大的目标,尤其是很小的目标。预定义的anchor框也会妨碍检测模型的泛化性能,对于新的检测任务就需要有不同的尺寸和宽高比。
3、为了获得更高的找回率,基于anchor的模型会在输入图像上密集放置anchor框(对于输入图像短边长度为800的FPN网络超过了180k个anchor),大多数anchor框在训练阶段被认为是负例,过多的负例加剧了正负样本之间的不平衡。
4、大量的anchor框也会明显增加计算量和内存占用,尤其在iou计算的阶段。
 图1
图1
如左图所示,FCOS预测一个4D向量(l,t,r,b)来编码每个前景像素点对应边界框的位置(训练时由ground-truth监督)。
右图展示了一个像素点对应多个边界框(重叠框),这可能会给边界框的回归带来问题。
近期,全卷积FCN神经网络在密集预测任务(语义分割、高度估计、关键点检测、计数)上获得了巨大的成功。作为其中一种高层的视觉任务,目标检测因为用到了anchor,可能是唯一一个没有纯粹全卷积像素级预测的任务了。很自然我们会疑问:我们能通过简单的像素级预测来做目标检测吗,像语义分割中的FCN那样?这样的话那些基础的视觉任务就可以用一套框架全部解决。我们的回答是肯定的。而且我们第一次证明,简单的全卷积模型甚至可以达到比anchor-base的模型更好的检测效果。
在文献中,一些工作尝试去构造一种FCN-base的框架,如DenseBox、UintBox。具体来说,这些FCN-base的模型直接特征图的一层的每个空间位置上预测一个4D向量和一个类别。如图1左所示,4D向量表示该位置到边界框四条边的偏移量。这些模型和语义分割的FCNs很像,除了每个位置需要回归一个4D向量以外。然而,为了处理不同尺寸的边界框,DenseBox将训练样本缩放成固定尺寸,从而在特征金字塔上进行检测,这和一次计算所有卷积的FCNs理念不同。而且,这些方法主要用在特定区域的检测上,比如场景文字检测和人脸检测,因为边界框大大重叠,所以这方法不适合在通用目标检测上使用。如图1右所示,高度重叠的边界框会给训练带来问题:重叠处的像素回归的框是不明确的。
这种新的检测模型有如下优势:
- 检测和其他FCNs的任务(如语义分割)统一,使它便于在任务间复用。
- 检测也可以是proposal free和anchor free的,显著降低参数量。设计参数一般需要多次调整,用上很多tricks来获得好的性能。因此我们新的检测框架使检测模型大大简化,尤其是在训练阶段。而且我们的方法完全避免了anchor的复杂的iou计算和匹配,降低了两倍的内存占用。
- 毫无疑问,我们达到了单阶段检测器sota的性能,而且我们提出的FCOS也可以用做RPN网络,在其他RPN的双阶段检测器中,达到了更好的性能。考虑到这是一个简单的、anchor free的、性能卓越的模型,我们建议学界重新思考anchor的必要性,而后者在当下被认为是检测中理所应当的标准。
- 提出了模型通过少量调整可以立刻用于解决其他视觉任务,包括实例分割、关键点检测。我们相信这种新的方法可以成为实例级预测问题的新的baseline。
2、相关文献
anchor based模型
anchor based模型由传统滑窗和proposal base模型演变而来。在anchor based模型中,anchor框可以看作是由滑窗或提议得到的预定义的框,并且对这些框所包含的图域进行分类,再经过回归得到准确对边界框对位置。因此anchor框在这些模型中可以被看作是训练样本。不同于之前对检测模型,如Fast RCNN,分别计算图域内的特征,anchor充分利用了卷积神经网络的特征图,避免了特征的重复计算,加速了检测过程。Faster RCNN中的RPN、SSD、YOLOv2中anchor的设计非常流行,已经成为了现代检测模型的惯例。
但是,如上所述,anchor框会带来很多超参数,需要精细调整才能达到好的性能。不光是anchor框,anchor还需要额外的参数来标记自身是一个正例、忽略、负例样本。在之前的工作中,通常会计算anchor框和gt框的iou来判断标签类别(正例iou [0.5,1])。这些超参数对最终对准确度有非常大对影响,需要反复调整。同时,这些超参数对不同任务不同,使检测任务和简单的FCNs架构不同。
anchor free模型
最流行的anchor free检测器该属YOLOv1,它预测目标中心附近的点上的边界框,而不使用anchor。只有接近中心的点会被使用,因为它们可以提高检测质量。但是,因为只使用了中心附近的点来预测边界框,YOLOv2提到YOLOv1的召回率很低。因此YOLOv2同样用上了anchor。和YOLOv1相比,FCOS利用到了ground truth中的所有点来预测边界框,而差的边界框会被”中心度“分支抑制。因此,FCOS可以达到和anchor based方法相近的召回率。
CornerNet是一种最近提出的单阶段anchor free目标检测器,它通过检测边界框的一对角点并且归并得到最终的检测框。CornerNet的将角点分配给实例的后处理过程十分复杂,并且为了归并,需要额外学习一种距离度量。
另外一些anchor free模型,如UnitBox,是基于DenseBox的。这一类模型因为难以处理重叠框,召回率低,而不适合作为通用目标检测模型。在本文中,我们展示了上述的两种问题都可以通过多层FPN解决。而且我们也把中心度分支结合进去,得到了比anchor base更好的检测结果。
3、方法
在本章中,我们首先推导目标检测在像素级预测范式中的形式。其次展示了如何利用多层预测来提高召回率,解决训练中重叠边界框的不确定性的问题。最后,我们提出了“中心度”分支,抑制差的检测框,大幅度提高总体性能。
3.1 全卷积单阶段目标检测器


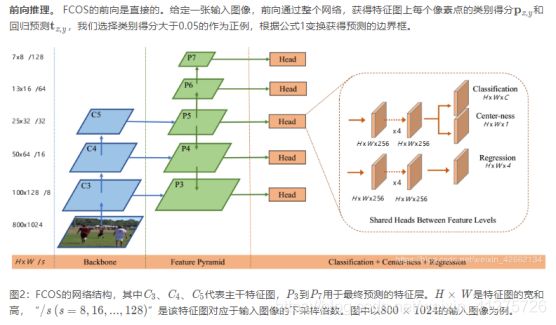
3.2 FCOS的FPN多层级预测
本章展示了FCOS如何解决文章开头的两个问题。
- CNN最终特征图的大的stride(如16)会导致相对低的最佳可能召回(best possible recal,BPR),这个原因是由于较大stride会在某种程度上降低正例框的IOU得分。对于FCOS而言,乍一看我们的BPR肯定比anchor based方法小,这是因为在最终特征图上因为stride大,而且没有位置信息,几乎不可能召回目标。这里,我们重点想说明,即使是stride很大,FCN based FCOS也可以得到好大BPR,甚至可以好过官方实现大Detectron的anchor based RetinaNet。因此BPR对于FCOS来说不是问题。而且使用多层级FPN预测,BPR可以进一步提高,接近RetinaNet对最好水平。
- 重叠框会在训练过程中带来二义性模糊的问题,因为重叠区域的像素需要判断:我到底该去回归哪个框呢?这是导致FCN based模型性能较差的一个原因。在本文中,我们展示了多层级预测可以很好的解决这个问题,使FCN based模型达到甚至超过anchor based模型。
训练
主干resnet50,
优化器SGD训练90K次迭代,
初始学习率0.01,
batchsize=16,
学习率在60K和80K次迭代时减小10倍,
weight_decay衰减系数1e-4,momentum动量0.9。
用ImageNet预训练模型,RetinaNet中的初始化方法初始化其他参数,输入图像短边固定在800,长边小于等于1333。
预测
输入图像经过模型,后处理和RetinaNet相同(包括超参数)(文中表示这些超参数再优化一下效果还能更好)。
复现-ing-未完待续
建模链接
Backbone :采用现有模型,如resnet50,提取5个block
[C1、C2、C3、C4、C5]
FPN模块:参考标准FPN。一般是Backbone参数抽象特征,再经过融合阶段。[https://zhuanlan.zhihu.com/p/148738276]
当前考虑,先通过seblock增加通道联系,分别经过1x1卷积,再经过RetinaNet中的FPN-BiFPN
[P1、P2、P3、P4、P5] = F[C1、C2、C3、C4、C5]
检测头head:
[pre_conf_i、pre_reg_i、pre_ctn_i] = detect_head[Pi] {Pi=[P1、P2、P3、P4、P5]}
制作偏移标签 lrtb
制作类别标签 cls
制作中心度标签 ctn
计算cls_loss_i(pre_conf_i, cls)
计算reg_loss_i(pre_reg_i, lrtb)
计算ctn_loss_i(pre_ctn_i, ctn)