Spark Operator浅析
本文作者: 林武康(花名:知瑕),阿里巴巴计算平台事业部技术专家,Apache HUE Contributor, 参与了多个开源项目的研发工作,对于分布式系统设计应用有较丰富的经验,目前主要专注于EMR数据开发相关的产品的研发工作。
本文介绍Spark Operator的设计和实现相关的内容.
Spark运行时架构
经过近几年的高速发展,分布式计算框架的架构逐渐趋同. 资源管理模块作为其中最通用的模块逐渐与框架解耦,独立成通用的组件.目前大部分分布式计算框架都支持接入多款不同的资源管理器. 资源管理器负责集群资源的管理和调度,为计算任务分配资源容器并保证资源隔离.Apache Spark作为通用分布式计算平台,目前同时支持多款资源管理器,包括:
YARN
Mesos
Kubernetes(K8s)
Spark Standalone(自带的资源管理器)
Apache Spark的运行时框架如下图所示, 其与各类资源调度器的交互流程比较类似.

图1 Spark运行时框架(Client模式)
其中,Driver负责作业逻辑的调度和任务的监控, 资源管理器负责资源分配和监控.Driver根据部署模式的不同,启动和运行的物理位置有所不同. 其中,Client模式下,Driver模块运行在Spark-Submit进程中, Cluster模式下,Driver的启动过程和Executor类似,运行在资源调度器分配的资源容器内.
K8s是Spark在2.3开始支持资源管理器,而相关讨论早在2016年就已经开始展开(https://issues.apache.org/jira/browse/SPARK-18278). Spark对K8s的支持随着版本的迭代也逐步深入, 在即将发布的3.0中,Spark on K8s提供了更好的Kerberos支持和资源动态支持的特性.
Spark on K8s
Kubernetes是由Google开源的一款面向应用的容器集群部署和管理系统,近年来发展十分迅猛,相关生态已经日趋完善. 在Spark官方接入K8s前,社区通常通过在K8s集群上部署一个Spark Standalone集群的方式来实现在K8s集群上运行Spark任务的目的.方案架构如下图所示:

图2 Spark Standalone on K8s
这个模式简单易用,但存在相当大的缺陷:
无法按需扩展, Spark Standalone部署后集群规模固定,无法根据作业需求自动扩展集群;
无法利用K8s原生能力, Spark Standalone内建的资源调度器不支持扩展,难以接入K8s调度,无法利用K8s提供的云原生特性;
Spark Standalone集群在多租户资源隔离上天生存在短板;
为此,Spark社区进行了深入而广泛的讨论,在2.3版本提供了对K8s的官方支持.Spark接入K8s的好处是十分明显的:
直接和K8s对接,可以更加高效和快捷的获取集群资源;
利用K8s原生能力(如namespace等)可以更好的实现资源隔离和管控.
Spark on K8s方案架构如下图所示, 设计细节可以参考:SPARK-18278
https://issues.apache.org/jira/browse/SPARK-18278?spm=a2c6h.12873639.0.0.4c2a21c4pIXnNk
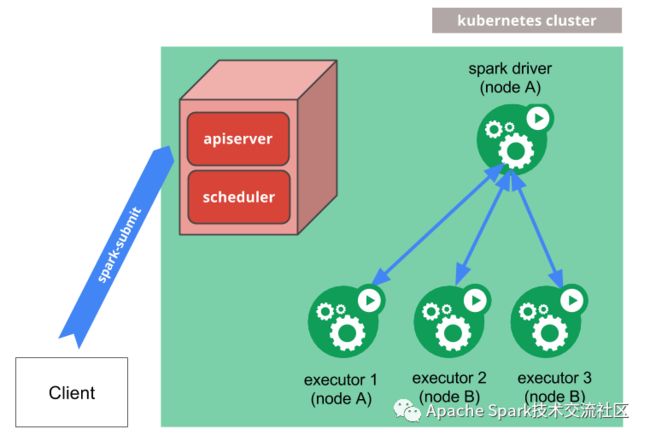
图3 Spark on K8s (Native)
在这个方案中,
Spark-Submit通过调用K8s API在K8s集群中启动一个Spark Driver Pod;
Driver通过调用K8s API启动相应的Executor Pod, 组成一个Spark Application集群,并指派作业任务到这些Executor中执行;
作业结束后,Executor Pod会被销毁, 而Driver Pod会持久化相关日志,并保持在'completed'状态,直到用户手清理或被K8s集群的垃圾回收机制回收.
当前的方案已经解决了Spark Standalone on K8s方案的部分缺陷,然而,Spark Application的生命周期管理方式和调度方式与K8s内置的工作负载(如Deployments、DaemonSets、StatefulSets等)存在较大差异,在K8s上执行作业仍然存在不少问题:
Spark-submit在K8s集群之外,使用非声明式的提交接口;
Spark Application之间没有协同调度,在小集群中很容易出现调度饿死的情况;
需要手动配置网络,来访问WebUI;
任务监控比较麻烦,没有接入Prometheus集群监控;
当然Spark on K8s方案目前还在快速开发中,更多特性不久会发布出来,相信未来和K8s的集成会更加紧密和Native, 这些特性包括:
动态资源分配和外部Shullfe服务
本地文件依赖管理器
Spark Application管理器
作业队列和资源管理器
Spark Operator浅析
在分析Spark Operator的实现之前, 先简单梳理下Kubernetes Operator的基本概念. Kubernetes Operator是由CoreOS开发的Kubernetes扩展特性, 目标是通过定义一系列CRD(自定义资源)和实现控制器,将特定领域的应用程序运维技术和知识(如部署方法、监控、故障恢复等)通过代码的方式固化下来. Spark Operator是Google基于Operator模式开发的一款的工具(https://github.com/GoogleCloudPlatform/spark-on-k8s-operator), 用于通过声明式的方式向K8s集群提交Spark作业.使用Spark Operator管理Spark应用,能更好的利用K8s原生能力控制和管理Spark应用的生命周期,包括应用状态监控、日志获取、应用运行控制等,弥补Spark on K8s方案在集成K8s上与其他类型的负载之间存在的差距.
下面简单分析下Spark Operator的实现细节.
系统架构

图4 Spark Operator架构
可以看出,Spark Operator相比Spark on K8s,架构上要复杂一些,实际上Spark Operator集成了Spark on K8s的方案,提供了更全面管控特性.通过Spark Operator,用户可以使用更加符合K8s理念的方式来控制Spark应用的生命周期.Spark Operator包括如下几个组件:
SparkApplication控制器, 该控制器用于创建、更新、删除SparkApplication对象,同时控制器还会监控相应的事件,执行相应的动作;
Submission Runner, 负责调用spark-submit提交Spark作业, 作业提交的流程完全复用Spark on K8s的模式;
Spark Pod Monitor, 监控Spark作业相关Pod的状态,并同步到控制器中;
Mutating Admission Webhook: 可选模块,基于注解来实现Driver/Executor Pod的一些定制化需求;
SparkCtl: 用于和Spark Operator交互的命令行工具
Spark Operator除了实现基本的作业提交外,还支持如下特性:
声明式的作业管理;
支持更新SparkApplication对象后自动重新提交作业;
支持可配置的重启策略;
支持失败重试;
集成prometheus, 可以收集和转发Spark应用级别的度量和Driver/Executor的度量到prometheus中.
工程结构
Spark Operator的项目是标准的K8s Operator结构, 其中最重要的包括:
manifest: 定义了Spark相关的CRD,包括:
ScheduledSparkApplication: 表示一个定时执行的Spark作业
SparkApplication: 表示一个Spark作业
pkg: 具体的Operator逻辑实现
ScheduledSparkApplication控制器
SparkApplication控制器
api: 定义了Operator的多个版本的API
client: 用于对接的client-go SDK
controller: 自定义控制器的实现,包括:
batchscheduler: 批处理调度器集成模块, 目前已经集成了K8s volcano调度器
spark-docker: spark docker 镜像
sparkctl: spark operator命令行工具
下面主要介绍下Spark Operator是如何管理Spark作业的.
Spark Application控制器
控制器的代码主要位于"pkg/controller/sparkapplication/controller.go"中.
提交流程
提交作业的提交作业的主流程在submitSparkApplication方法中.
// controller.go
// submitSparkApplication creates a new submission for the given SparkApplication and submits it using spark-submit.
func (c *Controller) submitSparkApplication(app *v1beta2.SparkApplication) *v1beta2.SparkApplication {
if app.PrometheusMonitoringEnabled() {
...
configPrometheusMonitoring(app, c.kubeClient)
}
// Use batch scheduler to perform scheduling task before submitting (before build command arguments).
if needScheduling, scheduler := c.shouldDoBatchScheduling(app); needScheduling {
newApp, err := scheduler.DoBatchSchedulingOnSubmission(app)
...
//Spark submit will use the updated app to submit tasks(Spec will not be updated into API server)
app = newApp
}
driverPodName := getDriverPodName(app)
submissionID := uuid.New().String()
submissionCmdArgs, err := buildSubmissionCommandArgs(app, driverPodName, submissionID)
...
// Try submitting the application by running spark-submit.
submitted, err := runSparkSubmit(newSubmission(submissionCmdArgs, app))
...
app.Status = v1beta2.SparkApplicationStatus{
SubmissionID: submissionID,
AppState: v1beta2.ApplicationState{
State: v1beta2.SubmittedState,
},
DriverInfo: v1beta2.DriverInfo{
PodName: driverPodName,
},
SubmissionAttempts: app.Status.SubmissionAttempts + 1,
ExecutionAttempts: app.Status.ExecutionAttempts + 1,
LastSubmissionAttemptTime: metav1.Now(),
}
c.recordSparkApplicationEvent(app)
service, err := createSparkUIService(app, c.kubeClient)
...
ingress, err := createSparkUIIngress(app, *service, c.ingressURLFormat, c.kubeClient)
return app
}提交作业的核心逻辑在submission.go这个模块中:
// submission.go
func runSparkSubmit(submission *submission) (bool, error) {
sparkHome, present := os.LookupEnv(sparkHomeEnvVar)
if !present {
glog.Error("SPARK_HOME is not specified")
}
var command = filepath.Join(sparkHome, "/bin/spark-submit")
cmd := execCommand(command, submission.args...)
glog.V(2).Infof("spark-submit arguments: %v", cmd.Args)
output, err := cmd.Output()
glog.V(3).Infof("spark-submit output: %s", string(output))
if err != nil {
var errorMsg string
if exitErr, ok := err.(*exec.ExitError); ok {
errorMsg = string(exitErr.Stderr)
}
// The driver pod of the application already exists.
if strings.Contains(errorMsg, podAlreadyExistsErrorCode) {
glog.Warningf("trying to resubmit an already submitted SparkApplication %s/%s", submission.namespace, submission.name)
return false, nil
}
if errorMsg != "" {
return false, fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %s", submission.namespace, submission.name, errorMsg)
}
return false, fmt.Errorf("failed to run spark-submit for SparkApplication %s/%s: %v", submission.namespace, submission.name, err)
}
return true, nil
}
func buildSubmissionCommandArgs(app *v1beta2.SparkApplication, driverPodName string, submissionID string) ([]string, error) {
...
options, err := addDriverConfOptions(app, submissionID)
...
options, err = addExecutorConfOptions(app, submissionID)
...
}
func getMasterURL() (string, error) {
kubernetesServiceHost := os.Getenv(kubernetesServiceHostEnvVar)
...
kubernetesServicePort := os.Getenv(kubernetesServicePortEnvVar)
...
return fmt.Sprintf("k8s://https://%s:%s", kubernetesServiceHost, kubernetesServicePort), nil
}可以看出,
可以配置控制器启用Prometheus进行度量收集;
Spark Operator通过拼装一个spark-submit命令并执行,实现提交Spark作业到K8s集群中的目的;
在每次提交前,Spark Operator都会生成一个UUID作为Session Id,并通过Spark相关配置对driver/executor的pod进行标记.我们可以使用这个id来跟踪和控制这个Spark作业;
Controller通过监控相关作业的pod的状态来更新SparkApplication的状态,同时驱动SparkApplication对象的状态流转.
提交成功后,还会做如下几件事情:
更新作业的状态
启动一个Service,并配置好Ingress,方便用户访问Spark WebUI
另外,如果对Spark on K8s的使用文档比较困惑,这段代码是比较好的一个示例.
状态流转控制
在Spark Operator中,Controller使用状态机来维护Spark Application的状态信息, 状态流转和Action的关系如下图所示:
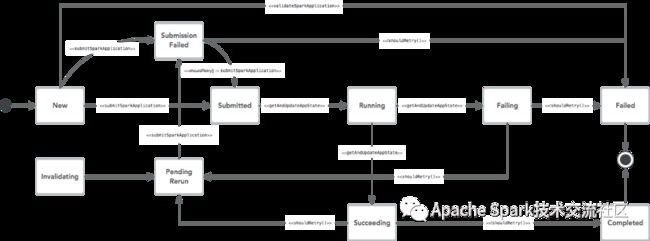
图5 _State Machine for SparkApplication_
作业提交后,Spark Application的状态更新都是通过getAndUpdateAppState()方法来实现的.
// controller.go
func (c *Controller) getAndUpdateAppState(app *v1beta2.SparkApplication) error {
if err := c.getAndUpdateDriverState(app); err != nil {
return err
}
if err := c.getAndUpdateExecutorState(app); err != nil {
return err
}
return nil
}
// getAndUpdateDriverState finds the driver pod of the application
// and updates the driver state based on the current phase of the pod.
func (c *Controller) getAndUpdateDriverState(app *v1beta2.SparkApplication) error {
// Either the driver pod doesn't exist yet or its name has not been updated.
...
driverPod, err := c.getDriverPod(app)
...
if driverPod == nil {
app.Status.AppState.ErrorMessage = "Driver Pod not found"
app.Status.AppState.State = v1beta2.FailingState
app.Status.TerminationTime = metav1.Now()
return nil
}
app.Status.SparkApplicationID = getSparkApplicationID(driverPod)
...
newState := driverStateToApplicationState(driverPod.Status)
// Only record a driver event if the application state (derived from the driver pod phase) has changed.
if newState != app.Status.AppState.State {
c.recordDriverEvent(app, driverPod.Status.Phase, driverPod.Name)
}
app.Status.AppState.State = newState
return nil
}
// getAndUpdateExecutorState lists the executor pods of the application
// and updates the executor state based on the current phase of the pods.
func (c *Controller) getAndUpdateExecutorState(app *v1beta2.SparkApplication) error {
pods, err := c.getExecutorPods(app)
...
executorStateMap := make(map[string]v1beta2.ExecutorState)
var executorApplicationID string
for _, pod := range pods {
if util.IsExecutorPod(pod) {
newState := podPhaseToExecutorState(pod.Status.Phase)
oldState, exists := app.Status.ExecutorState[pod.Name]
// Only record an executor event if the executor state is new or it has changed.
if !exists || newState != oldState {
c.recordExecutorEvent(app, newState, pod.Name)
}
executorStateMap[pod.Name] = newState
if executorApplicationID == "" {
executorApplicationID = getSparkApplicationID(pod)
}
}
}
// ApplicationID label can be different on driver/executors. Prefer executor ApplicationID if set.
// Refer https://issues.apache.org/jira/projects/SPARK/issues/SPARK-25922 for details.
...
if app.Status.ExecutorState == nil {
app.Status.ExecutorState = make(map[string]v1beta2.ExecutorState)
}
for name, execStatus := range executorStateMap {
app.Status.ExecutorState[name] = execStatus
}
// Handle missing/deleted executors.
for name, oldStatus := range app.Status.ExecutorState {
_, exists := executorStateMap[name]
if !isExecutorTerminated(oldStatus) && !exists {
// If ApplicationState is SUCCEEDING, in other words, the driver pod has been completed
// successfully. The executor pods terminate and are cleaned up, so we could not found
// the executor pod, under this circumstances, we assume the executor pod are completed.
if app.Status.AppState.State == v1beta2.SucceedingState {
app.Status.ExecutorState[name] = v1beta2.ExecutorCompletedState
} else {
glog.Infof("Executor pod %s not found, assuming it was deleted.", name)
app.Status.ExecutorState[name] = v1beta2.ExecutorFailedState
}
}
}
return nil
}从这段代码可以看到, Spark Application提交后,Controller会通过监听Driver Pod和Executor Pod状态来计算Spark Application的状态,推动状态机的流转.
度量监控
如果一个SparkApplication示例配置了开启度量监控特性,那么Spark Operator会在Spark-Submit提交参数中向Driver和Executor的JVM参数中添加类似"-javaagent:/prometheus/jmx_prometheus_javaagent-0.11.0.jar=8090:/etc/metrics/conf/prometheus.yaml"的JavaAgent参数来开启SparkApplication度量监控,实现通过JmxExporter向Prometheus发送度量数据.
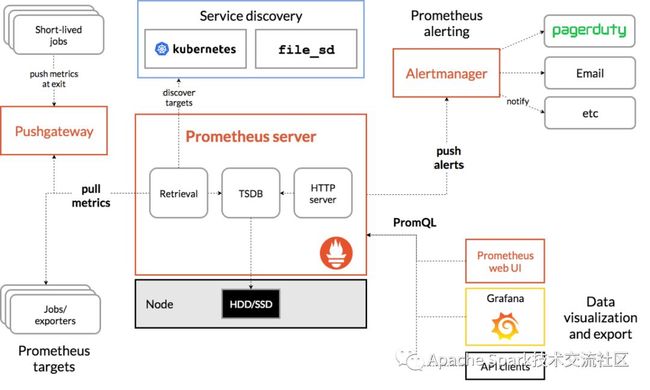
图6 Prometheus架构
WebUI
在Spark on K8s方案中, 用户需要通过kubectl port-forward命令建立临时通道来访问Driver的WebUI,这对于需要频繁访问多个作业的WebUI的场景来说非常麻烦. 在Spark Operator中,Spark Operator会在作业提交后,启动一个Spark WebUI Service,并配置Ingress来提供更为自然和高效的访问途径.
小结
本文总结了Spark计算框架的基础架构,介绍了Spark on K8s的多种方案,着重介绍了Spark Operator的设计和实现.K8s Operator尊从K8s设计理念,极大的提高了K8s的扩展能力.Spark Operator基于Operator范式实现了更为完备的管控特性,是对官方Spark on K8s方案的有力补充.随着K8s的进一步完善和Spark社区的努力,可以预见Spark on K8s方案会逐渐吸纳Spark Operator的相关特性,进一步提升云原生体验.
参考资料:(点击文末"阅读原文"直达链接)
[1] Kubernetes Operator for Apache Spark Design
[2] What is Prometheus?
[3] Spark on Kubernetes 的现状与挑战
[4] Spark in action on Kubernetes - Spark Operator的原理解析
[5] Operator pattern
[6] Custom Resources
阿里巴巴开源大数据技术团队成立Apache Spark中国技术社区,定期推送精彩案例,技术专家直播,问答区数个Spark技术同学每日在线答疑,只为营造纯粹的Spark氛围,欢迎钉钉扫码加入!

活动推荐:
11月16日上海线下沙龙 大数据+AI技术沙龙上海站
11月14日社区直播 11月14日Spark社区直播【 Spark on Kubernetes & YARN】