Spring bean初始化原理详解
一、 闲言
使用spring已经多年,却从来没有仔细研究过spring bean的初始化过程以及原理。知其然而不知其所以然,当面遇到比较深度的问题的时候,就无法解决或者需要花费大量问题方可解决。
二、 目的
本文主要想解决以下几个问题,希望大家看完本文以后,能得出答案。
l Bean的解析化过程是怎样的?
l BeanFactory的原理是怎样的?
l 为什么有的时候存在相同id的bean,spring启动报错,有的时候可以正常启动;此时通过id或者类型获取bean的时候使用的是哪一个bean?
l 自定义注解的实现原理是怎样的?
l bean的属性是在什么阶段注入的?
三、 示例代码
本文涉及的内容由以下代码加载过程整理而来。
ClassPathResource resource = new ClassPathResource("application.xml");
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(factory);
reader.loadBeanDefinitions(resource);
SpringTestService springTestService = (SpringTestService) factory.getBean(SpringTestService.class);
springTestService.doTest();
说明: spring版本:4.1.6.release
四、 Xml解析
1. 解析XML的核心类
1) XmlBeanDefinitionReader
Xml资源的阅读器,将xml解析成Document
2) DefaultBeanDefinitionDocumentReader
Document阅读器,将document解析成Element、Node、Attribute,以便于后续解析。
3) BeanDefinitionParserDelegate
解析xml生成BeanDefinition的委派类。所有解析过程由此类完成
4) DefaultListableBeanFactory
xml解析完以后,都注册到BeanFactory。后续通过BeanFactory可以源源不断的创建实例。
2. 流程图
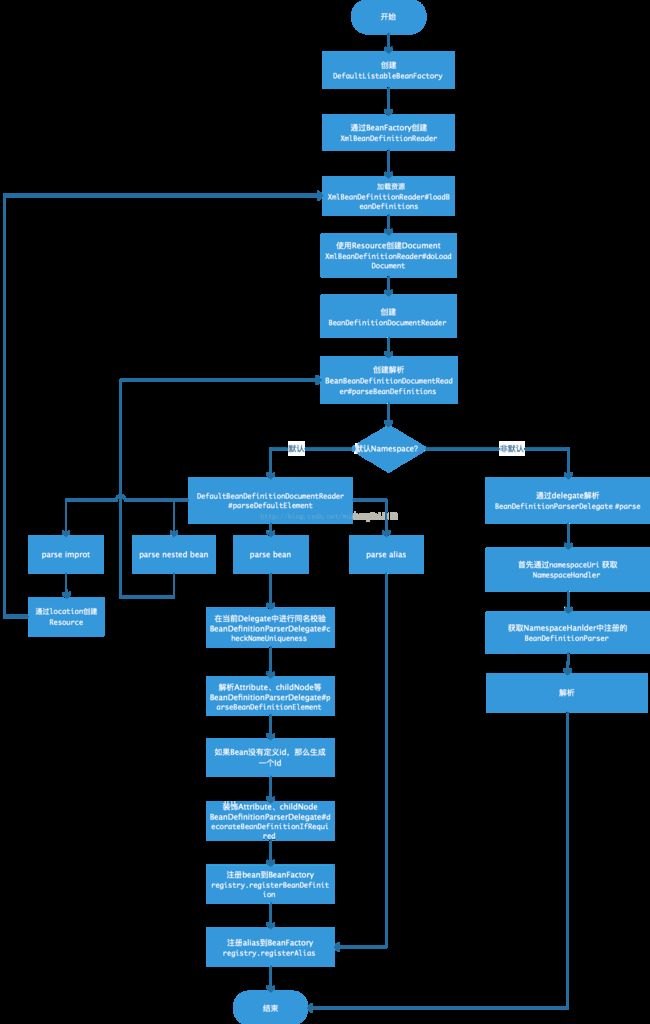
3. Xml文件解析详解
这部分内容时对流程图的详述,如果看懂流程图,可以忽略此部分。
1) XmlBeanDefinitionReader:Xml资源阅读器
l 包装Resource,生成EncodedResource
new EncodedResource(resource)l 判断当前是否正在加载此资源文件。
从ThreadLocal对象resourcesCurrentlyBeingLoaded中检查次Resource是否正在加载中,如果正在加载抛出异常,否则加载Resource文件。避免因为循环引用导致问题。
l 通过Resource创建InputSource
InputStream inputStream = encodedResource.getResource().getInputStream();
InputSource inputSource = new InputSource(inputStream);l 加载文档生成Document对象
Document doc = doLoadDocument(inputSource, resource); BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
documentReader.setEnvironment(getEnvironment());
documentReader.registerBeanDefinitions(doc,createReaderContext(resource));2) BeanDefinitionDocumentReader:文档阅读器
l doRegisterBeanDefinitions
a) 创建BeanDelinitionParserDelegate
b) 调用parseBeanDefinitions(root,this.delegate)方法进行解析
this.delegate= createDelegate(getReaderContext(), root, parent);
preProcessXml(root);
parseBeanDefinitions(root,this.delegate);
postProcessXml(root);l parseBeanDefinitions: 解析Element生成BeanDefinition;
如果是默认Namespace使用parseDefaultElement解析element;如果不是,通过delegate.parseCustomElement解析element。其中DefaultNamespace指的是http://www.springframework.org/schema/beans这个namespace。Delegate为上一步创建的BeanDefinitionParserDelegate
protected void parseBeanDefinitions(Element root,BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeListnl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++){
Nodenode = nl.item(i);
if (node instanceof Element) {
Elementele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}else {
delegate.parseCustomElement(ele);
}
}
}
} else {
delegate.parseCustomElement(root);
}
}l 根据element的不同,分别解析
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if(delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele,delegate);
}else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
//重新走一次资源加载过程
doRegisterBeanDefinitions(ele);
}
}说明:
IMPORT_ELEMENT对应于<importresource=""/>标签
ALIAS_ELEMENT对应于<aliasname=""alias=""/>标签
BEAN_ELEMENT对应于<beanclass=""/>标签
NESTED_BEANS_ELEMENT对应于<beans/>标签
l processBeanDefinition – 单个Bean解析的完整过程
a) 解析Element生成BeanDefinition,并封装在BeanDefinitionHolder中。
这是真正将Xml转换成Bean的地方。
b) 根据需要装饰BeanDefinitionHolder。
主要针对非默认命名空间的element、node进行一些额外的解析操作。
c) 注册BeanDefinitionHolder到DefaultListableBeanFactory。
protected void processBeanDefinition(Element ele,BeanDefinitionParserDelegate delegate) {
BeanDefinitionHolderbdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder !=null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition withname '" +bdHolder.getBeanName() + "'", ele, ex);
}
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
l importBeanDefinitionResource – 解析import xml
a) 判断location是否为绝对路径。
b) 如果是绝对路径,直接加载此绝对路径只想的xml,具体逻辑和示例代码中加载xml一样。
c) 如果是相对路径,通过location创建Resource,判断Resource是否存在,存在则读取,不存在则加上baseLocation,然后读取xml文件。
boolean absoluteLocation = ResourcePatternUtils.isUrl(location) ||ResourceUtils.toURI(location).isAbsolute();
if (absoluteLocation) {
int importCount= getReaderContext().getReader().loadBeanDefinitions(location,actualResources);
} else {
int importCount;
Resource relativeResource =getReaderContext().getResource().createRelative(location);
if (relativeResource.exists()){
importCount= getReaderContext().getReader().loadBeanDefinitions(relativeResource);
} else {
String baseLocation= getReaderContext().getResource().getURL().toString();
importCount =getReaderContext().getReader().loadBeanDefinitions( StringUtils.applyRelativePath(baseLocation, location),actualResources);
}
}Resource[] actResArray= actualResources.toArray(new Resource[actualResources.size()]);
getReaderContext().fireImportProcessed(location, actResArray,extractSource(ele));
3) BeanDefinitionParserDelegate:bean解析的委派类
l 解析xml生成BeanDefinition。
a) 检查bean id是否重复,如果重复则抛出异常。
checkNameUniqueness(beanName,aliases,ele);
b) 解析Bean的干活。
AbstractBeanDefinitionbeanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);c) 如果bean没有定义id,那么生成一个id
if (!StringUtils.hasText(beanName)) {
try{
if(containingBean != null){
beanName =BeanDefinitionReaderUtils.generateBeanName(beanDefinition,this.readerContext.getRegistry(),true);
} else{
beanName = this.readerContext.generateBeanName(beanDefinition);
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName!= null &&
beanName.startsWith(beanClassName) && beanName.length()> beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
} catch(Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
l checkNameUniqueness
检查bean id是否重复,如果重复则抛出异常。
foundName = CollectionUtils.findFirstMatch(this.usedNames, aliases);
if (foundName != null){
error("Bean name '" + foundName + "' is already used in this element", beanElement);
} id重复的校验是在当前Delegate进行的,不是整个BeanFactory中。
由上述代码分析可知每一个BeanDefinitionDocumentReader都会生成一个BeanDelinitionParserDelegate。当一个xml中import进来多个xml文件时,因为spring会为每一个xml文件生成一个BeanDefinitionDocumentReader对象,所以当一个id同时存在两个xml文件中的时候,是不会出现id重复的异常的。
l 解析Bean的干活 - parseBeanDefinitionElement。
// 创建BeanDefinition
AbstractBeanDefinition bd =createBeanDefinition(className, parent);
// 解析属性 - 解析Bean定义的属性
parseBeanDefinitionAttributes(ele, beanName, containingBean,bd);
// 解析child node - 描述信息
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
// 解析child node -
parseMetaElements(ele, bd);
// 解析child node -
l decorateBeanDefinitionIfRequired:对属性和子节点进行装配
a) 装饰当前element的属性。
b) 装饰当前element的child node。
public BeanDefinitionHolder decorateBeanDefinitionIfRequired( Elementele, BeanDefinitionHolder definitionHolder, BeanDefinition containingBd) {
BeanDefinitionHolderfinalDefinition = definitionHolder;
NamedNodeMap attributes = ele.getAttributes();
for (int i = 0; i < attributes.getLength(); i++){
Node node= attributes.item(i);
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
NodeList children = ele.getChildNodes();
for (int i = 0; i < children.getLength(); i++){
Node node= children.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
}
return finalDefinition;
}
l decorateIfRequired : 如果是非默认namespace,进行装饰操作
这个功能主要服务于spring提供的其他命名空间,或者开发者自定义的命名空间。需要继承NamespaceHandler实现decorate方法。
public BeanDefinitionHolder decorateIfRequired( Node node,BeanDefinitionHolder originalDef,BeanDefinition containingBd) {
String namespaceUri= getNamespaceURI(node);
if(!isDefaultNamespace(namespaceUri)) {
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if(handler != null){
return handler.decorate(node, originalDef,new ParserContext(this.readerContext, this,containingBd));
}
}
return originalDef;
}
l 其他命名空间:解析xml生成BeanDefinition
通过META-INF/spring.handlers中配置的namespaceURI和NamespaceHandler映射关系,返回NamespaceHandler。通过NamespaceHandler中定义的解析规则解析生成BeanDefinition对象。这就是自定义标签的实现原理。
public BeanDefinition parseCustomElement(Element ele, BeanDefinition containingBd){
String namespaceUri = getNamespaceURI(ele);
NamespaceHandlerhandler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate SpringNamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
return handler.parse(ele, newParserContext(this.readerContext,this, containingBd));
}如spring-context.jarMETA-INF/spring.handlers文件中
http\://www.springframework.org/schema/context=org.springframework.context.config.ContextNamespaceHandler
五、 创建Bean实例
1. BeanFactory#getBean流程图
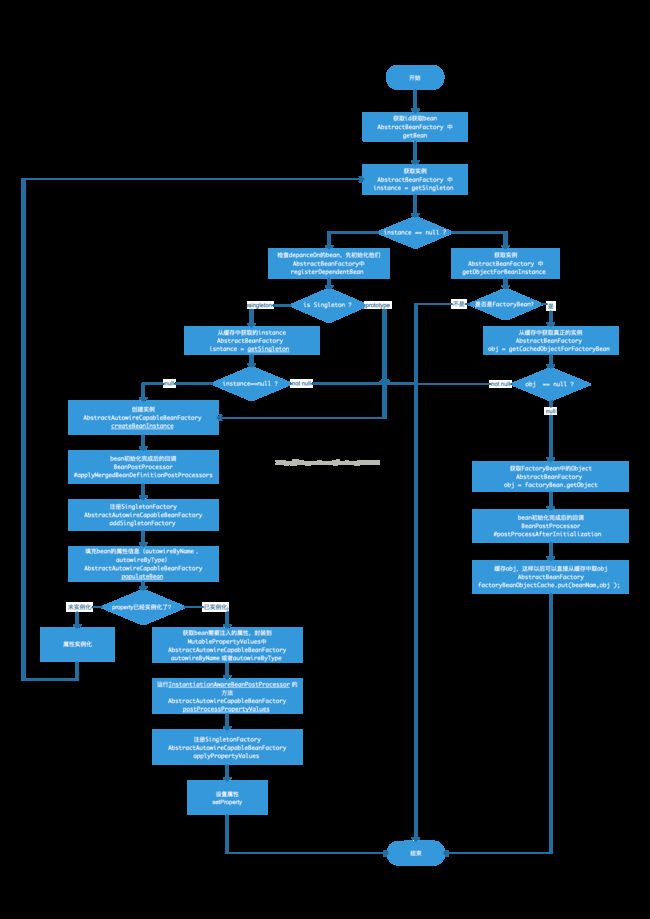
如上流程图所示,每一个步骤中第一行是功能描述,第二行功能所在的类,第三行是具体的方法。
当我们调用getBean方法获取Bean的时候,首先是通过getSingeleton方法从缓存中获取Instance。
如果获取到Instance,检查是否为FactoryBean,如果不是直接返回;如果是,获取FactoryBean的Object对象。其中有一步是检查缓存中是否存在Object,如果不存在,那么新建一个,缓存起来,见流程图。
如果获取不到Instance,检查是singletion还是prototype,如果是singletion,那么检查之前是否已经实例化过,如果已经实例化直接返回,如果没有实例化,则重新实例化。Prototype和singletion未实例化的场景基本一致。
2. Bean实例化流程图
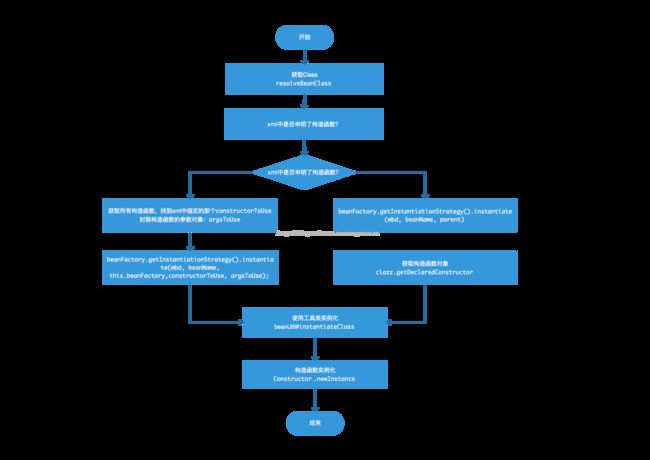
此流程是AbstractAutowireCapableBeanFactory#createBeanInstance方法的详细剖析。
六、 BeanFactory与FactoryBean
1. BeanFactory是Bean的工厂。
定义了获取Bean的接口。方法如下:
Object getBean(String name) throwsBeansException;
Object getBean(String name, Object... args)throws BeansException;
boolean containsBean(String name);
boolean isSingleton(String name) throwsNoSuchBeanDefinitionException;
boolean isPrototype(String name) throwsNoSuchBeanDefinitionException;
boolean isTypeMatch(String name,Class targetType) throws NoSuchBeanDefinitionException;
Class getType(String name) throwsNoSuchBeanDefinitionException;
String[] getAliases(String name);
2. FactoryBean是工厂Bean,
使用getBean获取FacotryBean时,实际上获取的是FactoryBean中getObject()返回的对象,而不是FactoryBean本身, 如果要获取FactoryBean对象,可以在id前面加一个&符号来获取。
某些场景中实例化Bean过程比较复杂,如果按照传统的方式,则需要在
<beanid="tokenRefreshSchedulerFactoryBean" class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<propertyname="triggers">
<list>
<refbean="trigger1"/>
<refbean="trigger2"/>
list>
property>
bean>
另一个场景就是dubbo的配置,如下代码所示。我们不需要关心网络、序列化、负载均衡等内容,只需要关注我们的业务接口就好了。
<beanid="orderPushServiceRef"class="com.alibaba.dubbo.config.spring.ReferenceBean">
<propertyname="interface"value="Service"/>
<propertyname="application"ref="dubboApplicationConfig"/>
<propertyname="registry"ref="dubboRegistryConfig"/>
<propertyname="version"value="${dubbo.consumer.version.gateway}"/>
<propertyname="timeout"value="${dubbo.consumer.timeout}"/>
<propertyname="retries"value="0"/>
<propertyname="check"value="${dubbo.consumer.check}"/>
bean>
七、 扩展:
1. spring自定义标签
以下示例均使用spring-context.jar的代码来说明。
1) 继承BeanDefinitionParser,创建自己的BeanDefinitionParser
如:PropertyPlaceholderBeanDefinitionParser
2) 创建NamespaceHandler,并注册BeanDefinitionParser
如:ContextNamespaceHandler
public void init() {
registerBeanDefinitionParser("property-placeholder",new PropertyPlaceholderBeanDefinitionParser());
}
3) 在classpath/META-INF下创建spring.handlers文件,并指定命名空间URI和NameSpaceHandler的映射关系
如:http\://www.springframework.org/schema/context=org.springframework.context.config.ContextNamespaceHandler
4) 定义Xsd文件
如:spring-context-4.1.xsd
5) 在classpath/META-INF下创建spring.schemas文件,并申明xsd的路径
2. spring自定义标签原理
上文的Bean初始化过程可知,在BeanDefinitionDocumentReader#parseBeanDefinitions方法中,非默认Namespace时,通过BeanDefinitionParserDelegate#parseCustomElement方法解析Bean。从流程图中可以清楚的看到,首先通过namespaceUri获取NameSapceHandler,然后获取NamespacHanlder中注册的Parser对象BeanDefinitionParser。
3. aop的一个问题
l 拦截器类:SpringMethodAnnotInterceptor
public class SpringMethodAnnotInterceptor implements MethodInterceptor{
publicObject invoke(MethodInvocation invocation) throws Throwable {
System.err.println("***** before method excute");
Object result = invocation.proceed();
System.err.println("***** after method excute");
returnresult;
}
}
l 目标类:SpringTestService
public classSpringTestService {
@SpringMethodAnnot
public boolean doTest2() {
System.err.println("dotest ");
returntrue;
}
public boolean doTest1(){
returndoTest2() ;
}
}l 测试
SpringTestService springTestService2 = (SpringTestService) xmlContext.getBean("springTestService");
springTestService2.doTest1();上述代码的运行结果时什么?是否能够进入拦截器中?答案是否定的,不能进入拦截器,输出的结果是do test
l 分析
从spring获取的Bean是被代理的对象,不是springTestService。如下图所示。
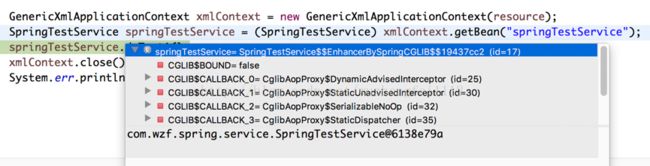
在doTest1方法中调用的时候,是springTestService对象。