【TVM手册】三、量化小结
文章目录
- Offical References
- TVM quantization roadmap
- INT8 quantization proposal
- Quantization Story - 2019-09
- Quantization Development
- Quantization Framework supported by TVM
- TF Quantization Related
- Pytorch Quantization Related
- MXNet related
- Tensor Core Related
- Related Commit
- Speed Up
- Comparison
- Automatic Integer Quantization
- Accepting Pre-quantized Integer models
- Speed Profile Tools
- Devices Attributes
- Third-Party Tutorials
- Theory Summary
- Practice
- Copartner
- Alibaba
TVM里面关于量化的资料非常的多,虽然很有价值,但是极其零散,对于散户不是非常友好。这里汇总一下。
Offical References
TVM quantization roadmap
INT8 quantization proposal
- INT8 quantization proposal - 2018-07
- This document presents the high-level overview of quantization process, and presents a proposal for implementing that in TVM.
- introduce background on quantization
- INT8 Quantization - Code generation for backends - 2018-07
- This thread only focuses on implementation of quantized layers in TVM.
Quantization Story - 2019-09
Quantization Story - 2019-09
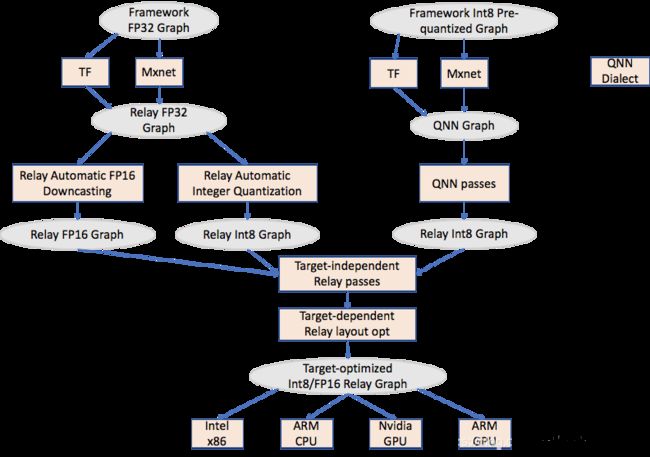
Quantization Development
- [RFC] Search-based Automated Quantization - 2020-01-22
- I proposed a new quantization framework, which brings hardware and learning method in the loop.
- Brought the idea from some existing quantization frameworks, I choose to adopt the annotation-calibration-realization 3-phases design:

- Annotation: The annotation pass rewrites the graph and inserts simulated quantize operation according to the rewrite function of each operator. The simulated quantize operation simulates the rounding error and saturating error of quantizing from float to integer,
- Calibration: The calibration pass will adjust thresholds of simulated quantize operations to reduce the accuracy dropping.
- Realization: The realization pass transforms the simulation graph, which computes with float32 actually, to a real low-precision integer graph.
Quantization Framework supported by TVM
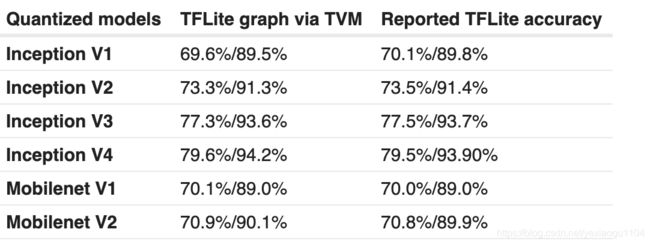
TF Quantization Related
TVM support all Pre-quantized TFLite hosted
- The performance is evaluated on C5.12xlarge Cascade lake machine, supported Intel VNNI
- not autotuned the models yet.

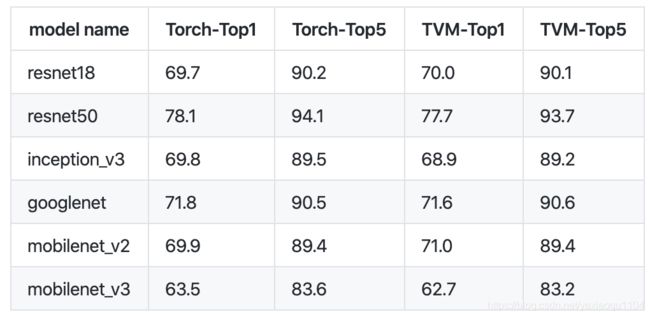
Pytorch Quantization Related
-
How to convert the model to a quantized one through relay?
- telling how to set qconfig for torch.quantization.get_default_qconfig(‘fbgemm’)
-
Quantized model accuracy benchmark: PyTorch vs TVM
- telling how to convert quantized pytorch model to tvm model
- compare between accuracy and speed for resent18、resent5、mobilenet-v2、moblienet-v3、inception_v3 and googlenet.
- include STATIC QUANTIZATION WITH EAGER MODE IN PYTORCH: pytorch’s quantization turorial.

-
gap_quantization
- Placeholder for GAP8 export and quantization module for PyTorch
- include squeezenet-v1.1’ s quantization file.
MXNet related
- Model Quantization for Production-Level Neural Network Inference
- The below CPU performance is from an AWS EC2 C5.24xlarge instance with custom 2nd generation Intel Xeon Scalable Processors (Cascade Lake).
- The model quantization delivers more stable speedup over all models, such as 3.66X for ResNet 50 v1, 3.82X for ResNet 101 v1 and 3.77X for SSD-VGG16, which is very close to the theoretical 4X speedup from INT8.

- the accuracy from Apache/MXNet quantization solution is very close to FP32 models without the request of retaining the mode. In Figure 8, MXNet ensured only a small reduction in accuracy, less than 0.5%.

- [topi] add ARM v8.2 udot (uint8) support #3978
- Add uint8 intrinsic for ARM. Currently it is udot.v2i32.v8i8 which may have too small lanes. will add more later
Tensor Core Related
- [RFC][Tensor Core] Optimization of CNNs on Tensor Core
- [Perf] Enhance cudnn and cublas backend and enable TensorCore
Related Commit
- [OPT] Low-bit Quantization #2116
- Benchmarking Quantization on Intel CPU
- [RFC][Quantization] Support quantized models from TensorflowLite#2351
- After initial investigation and effort, in the Mobilenet V1 model, INT8 can get speed up about 30% when compared with FP32 on ARM CPU.
- [TFLite] Support TFLite FP32 Relay frontend. #2365
- This is the first PR of #2351 to support importing exist quantized int8 TFLite model. The base version of Tensorflow / TFLite is 1.12.
- [Strategy] Support for Int8 schedules - CUDA/x86 #5031
- Recently introduce op strategy currently has some issues with task extraction with AutoTVM. This PR fixes them for x86/CUDA.
- [Torch, QNN] Add support for quantized models via QNN #4977
- [QNN][Legalize] Specialize for Platforms w/o fast Int8 support #4307
- QNN - Conv2D/Dense Legalize for platforms with no fast Int8 units
Speed Up
Comparison
Automatic Integer Quantization
- The inference time is longer after int8 quantization
- TVM-relay.quantize vs quantization of other Framework
- TVM FP32、TVM int8、TVM int8 quantization + AutoTVM,MXNet

- Quantization int8 slower than int16 on skylake CPU
- The int8 is always slower than int16 before and after the auto-tuning
- Target: llvm -mcpu=skylake-avx512
- Problem is solved by creating the int8 task explicitly
- create the task topi_x86_conv2d_NCHWc_int8
- set output dtype to int32, input dtype=uint8, weight dtype=int8

- TVM学习笔记–模型量化(int8)及其测试数据
- TVM FP32、TVM int8、TVM int8 quantization , MXNet, TF1.13
- 含测试代码

- 8bit@Cuda: AutoTVMvs TensorRT vs MXNet
- In this post, we show how to use TVM to automatically optimize of quantized deep learning models on CUDA.

- In this post, we show how to use TVM to automatically optimize of quantized deep learning models on CUDA.
Accepting Pre-quantized Integer models
- Is there any speed comparison of quantization on cpu
- discuss a lot about speed comparison among torch-fp32, torch-int8, tvm-fp32, tvm-int16, tvm-int8
- discuss a lot about speed comparison among torch-fp32, torch-int8, tvm-fp32, tvm-int16, tvm-int8
Speed Profile Tools
- How to profile speed in each layer with RPC?
- the debug runtime will give you some profiling information from the embedded device, e.g.:
Node Name Ops Time(us) Time(%) Start Time End Time Shape Inputs Outputs --------- --- -------- ------- ---------- -------- ----- ------ ------- 1_NCHW1c fuse___layout_transform___4 56.52 0.02 15:24:44.177475 15:24:44.177534 (1, 1, 224, 224) 1 1 _contrib_conv2d_nchwc0 fuse__contrib_conv2d_NCHWc 12436.11 3.4 15:24:44.177549 15:24:44.189993 (1, 1, 224, 224, 1) 2 1 relu0_NCHW8c fuse___layout_transform___broadcast_add_relu___layout_transform__ 4375.43 1.2 15:24:44.190027 15:24:44.194410 (8, 1, 5, 5, 1, 8) 2 1 _contrib_conv2d_nchwc1 fuse__contrib_conv2d_NCHWc_1 213108.6 58.28 15:24:44.194440 15:24:44.407558 (1, 8, 224, 224, 8) 2 1 relu1_NCHW8c fuse___layout_transform___broadcast_add_relu___layout_transform__ 2265.57 0.62 15:24:44.407600 15:24:44.409874 (64, 1, 1) 2 1 _contrib_conv2d_nchwc2 fuse__contrib_conv2d_NCHWc_2 104623.15 28.61 15:24:44.409905 15:24:44.514535 (1, 8, 224, 224, 8) 2 1 relu2_NCHW2c fuse___layout_transform___broadcast_add_relu___layout_transform___1 2004.77 0.55 15:24:44.514567 15:24:44.516582 (8, 8, 3, 3, 8, 8) 2 1 _contrib_conv2d_nchwc3 fuse__contrib_conv2d_NCHWc_3 25218.4 6.9 15:24:44.516628 15:24:44.541856 (1, 8, 224, 224, 8) 2 1 reshape1 fuse___layout_transform___broadcast_add_reshape_transpose_reshape 1554.25 0.43 15:24:44.541893 15:24:44.543452 (64, 1, 1) 2 1
- the debug runtime will give you some profiling information from the embedded device, e.g.:
Devices Attributes
- Intel® 处理器产品架构/微架构对照表
Third-Party Tutorials
Theory Summary
- model compression ,distilltation and quantitation
Practice
- int8量化和tvm实现
- Latency-Predictor
- This project is designed to make latency predictor of mobile-devices.
- We can measure latency using programs in latency-predictor, which implemented based on TVM.
- Can also be used for auto-tvm totorials for android_cpu and android_gpu, test.py might also be helpful
- wxquare/programming/blog
- TVM_CPU_schedule
- TVM_code_generation
- TVM_graph_optimization
- TVM_hello
- TVM_quantization
- see 0_tvm_quantization.py, 1_tvm_quantization_resnet.py , 2_tvm_quantization_incepv1.py , for more infos.
Copartner
Please go tvmai/meetup-slides for more recently info what ohter copartners have done for tvm.
Alibaba
- 记录一下2019
- 介绍阿里在TVM上的发展历程
- 在今年(2019年)4月份的时候,我又回来和同事一起搞ARM CPU量化优化了,因为这是有业务要用的。我们一起吭哧吭哧搞了一段时间,可以很高兴的说我们比QNNPack更快,在Mobilenet V1上是1.61x TFLite,1.27X QNNPACK,Mobilenet V2是2X TFLite, 1.34X QNNPack。
- TVM@AliOS

- QNNPACK: Open source library for optimized mobile deep learning


