花书+吴恩达深度学习(五)正则化方法(防止过拟合)
目录
0. 前言
1. 参数范数惩罚
2. Dropout 随机失活
3. 提前终止
4. 数据集增强
5. 参数共享
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~
花书+吴恩达深度学习(五)正则化方法(防止过拟合)
花书+吴恩达深度学习(六)优化方法之 Mini-batch(SGD, MBGD, BGD)
花书+吴恩达深度学习(七)优化方法之基本算法(Momentum, Nesterov, AdaGrad, RMSProp, Adam)
花书+吴恩达深度学习(八)优化方法之 Batch normalization
花书+吴恩达深度学习(九)优化方法之二阶近似方法(牛顿法, CG, BFGS, L-BFGS)
0. 前言
通常,我们将数据集划分为训练集和测试集,降低训练集的训练误差,对测试集进行泛化。
但有的时候,训练集的训练误差很小,但是测试集的泛化误差很大,这被称为过拟合,高方差。
为了解决这类的问题,引入了正则化方法。
正则化被定义为对学习算法的修改,旨在减少泛化误差而不是训练误差。
1. 参数范数惩罚
参数范数惩罚对损失函数进行修改:
![]()
![]() 越大,表示对权重的惩罚越大。参数惩罚会使得过拟合的极端曲线趋于平缓,缓解过拟合问题。
越大,表示对权重的惩罚越大。参数惩罚会使得过拟合的极端曲线趋于平缓,缓解过拟合问题。
因为偏置仅控制一个单变量,影响不大,所以我们只对权重做惩罚而不对偏置做惩罚。
为了减少搜索空间,我们对所有层使用相同的权重衰减。
L2 参数惩罚,通过向目标函数添加如下正则化项,使权重更加接近原点:
![]()
L1 参数惩罚,通过向目标函数添加如下正则化项,会产生更稀疏的解:
![]()
在神经网络中,表现为 Frobenius 范数,是对每一层的权重矩阵惩罚:
![\Omega (\theta)=\frac{1}{2}\sum_{l=1}^{L}\left\|W^{[l]}\right\|_F^2](http://img.e-com-net.com/image/info8/c58f05c8b3c84d3eba7cd1f17c6cf8d6.gif)
有文献指出一种策略,约束每一层每个神经元的范数,而不是约束每一层整个权重矩阵的 Frobenius 范数,可以防止某一隐藏单元有非常大的权重。
2. Dropout 随机失活
过拟合表现为神经网络对数据的拟合度太好,为了降低拟合度,我们可以使得神经网络中部分单元失活(去除单元)。
Dropout 训练的集成包括从基础网络中除去非输出单元后形成的子网络。
在一次前向传播和反向传播中,遍历每一层的每个神经元,按照一定概率使其失活(输入单元 ![]() 隐藏单元
隐藏单元 ![]() ),因为神经网络基于一系列仿射变化和非线性变化,对单元乘 0 就能删除一个单元和连接这个单元的输入输出。此次迭代之后,恢复失活的单元,下次迭代过程中重新随机失活一些单元。
),因为神经网络基于一系列仿射变化和非线性变化,对单元乘 0 就能删除一个单元和连接这个单元的输入输出。此次迭代之后,恢复失活的单元,下次迭代过程中重新随机失活一些单元。
对每一层的计算可简单表示如下,最后一步是为了保证期望不变:

Dropout 的优点:
- 可以在不同层上使用不同
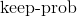 概率的 Dropout
概率的 Dropout - 不限制适用的模型,几乎在所有使用分布式表示且可以用随机梯度下降的模型上都表现很好
Dropout 的缺点:
- 损失函数不能显式的表示出来,无法画出带有 Dropout 的损失函数图像
- 虽然泛化误差会降低很多,但是代价是更大的模型和更多训练算法的迭代次数
3. 提前终止
通常情况下,泛化误差会随着迭代次数呈现 U 型图像:

我们只需要在泛化误差的最低点提前终止训练即可。
一种实现思路是:设定参数 ![]() ,如果连续
,如果连续 ![]() 次迭代后的泛化误差都没有改善,就终止迭代。
次迭代后的泛化误差都没有改善,就终止迭代。
有两种使用提前终止的策略:
- 小量数据集通过提前终止得出了迭代的步数
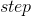 后,再次初始化参数,在所有训练集上重新训练 步
后,再次初始化参数,在所有训练集上重新训练 步 - 小量数据集通过提前终止得出了最小的损失函数
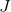 ,在所有训练集上继续训练,直到泛化误差小于
,在所有训练集上继续训练,直到泛化误差小于
提前终止的优点:
- 几乎不需要改变训练过程、目标函数和参数
- 可以单独使用,也可以和其他正则化策略结合使用
- 提前终止能自动确定正则化的正确量,而权重衰减需要进行多个超参数测试
提前终止的缺点:
- 无法同时权衡:降低训练误差和防止过拟合,因为为防止过拟合而终止迭代,也就无法继续降低训练误差
4. 数据集增强
我们也可以通过增加数据量,来减少过拟合的问题。
数据集增前通过创造假数据并添加到训练集中,来增加数据量。
例如在图像识别中,可以对图像进行平移,翻转,裁剪,放大,更改颜色 RGB 等操作创造新数据。
5. 参数共享
假设,有参数 ![]() 的模型 A 和参数
的模型 A 和参数 ![]() 的模型 B ,执行相同的任务,虽然输入分布不同。
的模型 B ,执行相同的任务,虽然输入分布不同。
如果这些任务足够相似,我们可以假设参数 ![]() 应和参数
应和参数 ![]() 接近,可使用以下形式的参数范数惩罚:
接近,可使用以下形式的参数范数惩罚:
![]()
正则化一个监督学习模型的参数,使其接近另一个无监督学习模型的参数,这种架构使得分类模型中的许多参数能与无监督模型中对应的参数匹配。
如果这篇文章对你有一点小小的帮助,请给个关注,点个赞喔~我会非常开心的~