大数据实验(二)HDFS API的使用(Python 3.7)
前言
书本第六章的主要内容就是讲了HDFS的一些操作指令,还有非常简略的Java调用HDFS API代码的示例。虽然据说用Java的运行效率会高很多,可是我也没有系统地学过Java,而且看样子实际做起来比较繁琐,所以我还是选择了Python来实现HDFS API的调用。用Python特别好的地方就是后面的数据处理和可视化会方便很多,人生苦短,我用Python,哈哈哈哈哈哈哈哈。
其实用python2也可以,所以就可以省去安装python3的步骤了,不过好像要安装一下pip
HDFS API的使用(Python)
- 前言
- Python入门
- 本次所需工具
- CentOS 7 安装Python 3.7
- 安装依赖
- 编译和安装Python
- 修改pip源和安装库
- 安装配置VSCode(可跳过)
- 安装插件
- 连接虚拟机
- 编写代码
Python入门
Python其实入门还是很简单的,没有接触过的同学,可以去菜鸟教程上面快速入门,还有慕课上面嵩天老师的课也挺好。
本次所需工具
- Python安装包(官网下载速度很慢,可以从我这里下载(提取码: mxhv);
- VSCode(非必须)
- 正常启动的Hadoop集群
CentOS 7 安装Python 3.7
以下操作在Slave001上面执行,当然别的虚拟机应该也没问题
安装依赖
- CentOS 7 本身缺少了一部分Python运行所需要的软件或者运行库,在root用户下执行以下命令安装
yum install gcc openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel sqlite-devel libffi-devel tk-devel wget curl-devel ibffi-devel
编译和安装Python
还是在root用户下执行这些操作
- 首先将下载好的Python安装包上传到Slave001
- 解压(注意路径)
tar -zxvf Python-3.7.0.tgz - 进入解压后的文件夹
cd Python-3.7.0, 编译./configure - 最后安装
make && make install,这一步要好久好久好久好久 - 为安装好的Python3和pip3创建软链接(可以理解为快捷方式)
ln -s /usr/local/bin/pip3 /usr/bin/pip3
ln -s /usr/local/bin/python3 /usr/bin/python3
- 检查是否安装成功
pip3 -V
python3
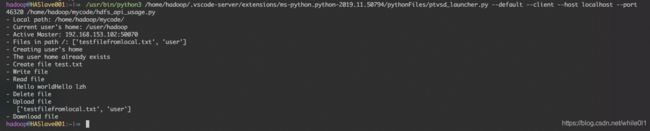
输出结果如图:

输入exit()退出
修改pip源和安装库
切换回hadoop用户
pip是一个专门用来管理Python库的工具,可以安装删除库之类的。由于pip默认的源是国外的,下载库时的速度会很慢,所以我们把它修改为国内的源,这里我用的是阿里的源:
- 切换到
/home/hadoop目录,创建.pip/文件夹
cd ~/ && mkdir .pip
- 创建pip.conf文件
vi .pip/pip.conf
添加以下内容
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
- 安装
pyhdfs库
pip3 install pyhdfs --user
输入python3 -c 'import pyhdfs',如果没有报错,则是安装成功了
安装配置VSCode(可跳过)
注意VSCode是在Windows上面安装的
这里安装VSCode是为了方便远程连接虚拟机,然后写代码,因为VSCode提供了很多插件,写起代码来会方便很多。如果你习惯用别的编辑器或者vim,那这一步可以跳过。安装过程很简单,到官网下载安装包,双击安装就行了。
安装插件

这是我安装的一些插件:
必装的是等一下需要用到的,其它的可以看个人喜好
- Remote Development (必装)
- Python (必装)
- Chinese (界面显示为中文)
- One Dark Pro (挺好看的一个颜色主题)
- Bracket Pair Colorizer (让你的括号五颜六色更清楚)
- Visual Studio IntelliCode (自动补全代码的,贼好用)
连接虚拟机
- 安装完Remote Development后,左侧会有一个这样的图标,在那里配置ssh连接到虚拟机

以这样的格式添加你的虚拟机配置:
建议用hadoop用户登录
保存之后在左侧就会出现你的虚拟机,选择连接就好,然后根据提示输入密码,就能连接成功了
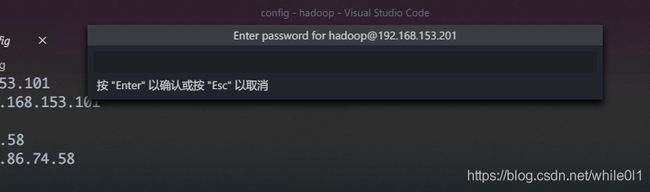
然后打开文件夹
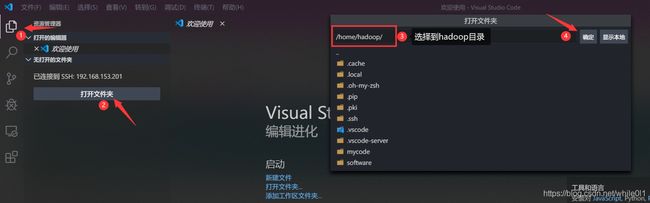
再次输入密码,就可以看到左侧打开了我们的目录,这时候就可以添加文件夹和文件了,我的如图:
- 连接虚拟机后,VSCode会提示你把插件安装到虚拟机,所以还需要再安装一下,才能在虚拟机上用
Python插件要选择一下你的Python版本:
编写代码
然后就可以开始写代码了,这部分的难点其实不是Python的语法,而是pyhdfs这个库的使用,可以参考官方的doc
这里给出我的部分代码,实现了在HDFS上文件/的创建,读写,和删除,从本地上传文件和下载文件到本地,可以参考一下:
#hdfs_api_usage.py
import pyhdfs
import os
# 获取本地当前目录
local_path = '/home/hadoop/mycode/'
print('- Local path:', local_path)
# 连接HDFS的Namenode,以在HDFS上进行文件的读写等操作
# host后面是两个Master的IP地址和端口,我们用的都是50070,user_name是hadoop
client = pyhdfs.HdfsClient(
hosts="192.168.153.102,50070, 192.168.153.101,50070", user_name="hadoop"
)
# 获取当前用户的根目录,用print打印出来
user_home = client.get_home_directory()
print("- Current user's home:", user_home)
# 获取可用的Master
print("- Active Master:", client.get_active_namenode())
# 列出根目录下的文件
print("- Files in path /:", client.listdir("/"))
# 为当前用户创建目录
print("- Creating user's home")
if client.exists(user_home): # 是否已存在
print("- The user home already exists")
else:
client.mkdirs(user_home) # 创建
print("- The user home has been created", client.listdir("/"))
# 创建文件
print("- Create file test.txt")
# 在/目录创建test.txt, 写入内容为Hello world,覆盖已有文件
client.create("/test.txt", "Hello world", overwrite=True)
# 写读文件
# 写文件
print('- Write file')
client.append("/test.txt", "Hello lzh")
# 读文件
print('- Read file')
test_file = client.open("/test.txt")
# 有read或者readline,下面那个是把输出的b''去掉
# print(test_file.read())
print(' ', str(test_file.readline())[2:-1])
test_file.close()
#删除文件
print('- Delete file')
client.delete('/test.txt')
#上传本地文件
#这里第一个参数指定本地机器的一个文件,第二个参数想要保存的HDFS的路径和文件名,第三个允许覆盖,不然重复文件报错
#我这里的是与代码文件同目录下的testfolder/testfile.txt
print('- Upload file')
client.copy_from_local(local_path + 'testfolder/testfile.txt', '/testfilefromlocal.txt', overwrite=True)
print(' ', client.listdir('/'))
#下载文件到本地
print('- Download file')
client.copy_to_local('/testfilefromlocal.txt', local_path + 'testfolder/testfilefromHDFS.txt')
# 测试删除文件夹
# print('Testing delete folder')
# print('Before deleting:', client.listdir('/'))
# client.mkdirs('/testfolder') #创建
# if client.exists('/testfolder'):
# client.delete('/testfolder') #删除
# print('After deleting:', client.listdir('/')) #重新列出目录
写完代码之后,确保hadoop集群已经正常启动了,就可以在终端上面运行(当然你得先切换到代码的目录)
python3 hdfs_api_usage.py
如果你已经安装好了上面提到的Python插件,也可以直接按F5运行,VScode会让你选择调试配置:

为了不用每次都选择配置,我们添加一个配置文件

点击之后VScode会创建一个文件,我们就用默认的行了

输出结果: