2019年CS224N课程笔记-Lecture 17:Multitask Learning
资源链接:https://www.bilibili.com/video/BV1r4411f7td?p=16
正文内容
现在有一种想法比较流行:在一个模型中完成10个不同的任务(十项全能比赛)
把所有预处理后发现可能对于一个词在不同的模型中含义是不一样的
NLP&AI的下一步是什么?

基于特征工程的机器学习->特征学习的深度学习->针对单个任务的深层架构工程->?
单任务学习的局限性
- 鉴于{dataset,task,model,metric},近年来性能得到了很大改善
- 只要
 ,我们就可以得到当前的最优结果 (C是输出类别的个数)(大概80%-90%)
,我们就可以得到当前的最优结果 (C是输出类别的个数)(大概80%-90%) - 对于更一般的 Al,我们需要在单个模型中继续学习
- 模型通常从随机开始,仅部分预训练 :disappointed:

预培训和分享知识是伟大的!
(如果我们随机权重从头开始是非常困难的,所以加载别人的往往是个很好的选择)
为什么在NLP中权重和模型共享没有发生那么多?
- NLP需要多种推理:逻辑,语言,情感,视觉,++
- 需要短期和长期记忆
- NLP被分为中间任务和单独任务以取得进展
->在每个社区中追逐基准(类似于划分的很明显,可能实际上差不多类型的问题,但是别人依旧把AB分开而不是相互关联的,例如:命名实体识别和词性标注很多都是类似的,但是很多人把他们当成两个完全不一样的问题)
- 一个无人监督的任务可以解决所有问题吗?不可以,语言显然需要监督
为什么要为NLP建立统一的多任务模型?
- 多任务学习是一般NLP系统的阻碍
- 统一模型可以决定如何转移知识(领域适应,权重分享,转移和零射击学习)
- 统一的多任务模型可以
- 更容易适应新任务
- 简化部署到生产的时间
- 降低标准,让更多人解决新任务
- 潜在地转向持续学习
例如命名实体识别中的词性标注对于翻译等其他任务有很大的帮助
如何在同一个框架中表达多个NLP任务?
- 序列标记
- 命名实体识别,aspect specific sentiment
- 文字分类
- 对话状态跟踪,情绪分类
- Seq2seq
- 机器翻译,总结,问答

自然语言十项全能(decaNLP)
现在我们有十项任务了
把 10 项不同的任务都写成了 QA (如上图Question、Answer)的形式,进行训练与测试(把多任务学习当作问答)

Meta-Supervised learning元监督学习 :
使用问题q作为任务t的自然描述,以使模型使用语言信息来连接任务
y是q的答案,x是回答q所必需的上下文
设计decaNLP模型
(最简单方式是根据问题来判断,然后选择模型,例如机器翻译就选择机器翻译模型。但是这样可能里面有一大推if语句,然后我们更希望的是这个模型是一个多任务模型,而不是多个单任务的组合模型)
需求:
- 没有任务特定的模块或参数,因为我们假设任务ID是未提供的
- 必须能够在内部进行调整以执行不同的任务
- 应该为看不见的任务留下零射击推断的可能性
decaNLP的多任务问答网络

以一段上下文开始
问一个问题
一次生成答案的一个单词,通过
- 指向上下文
- 指向问题
- 或者从额外的词汇表中选择一个单词
每个输出单词的指针切换都在这三个选项中切换
多任务问答网络(MQAN)

固定的 GloVe 词嵌入 + 字符级的 n-gram 嵌入 [公式] Linear [公式] Shared BiLSTM with skip connection
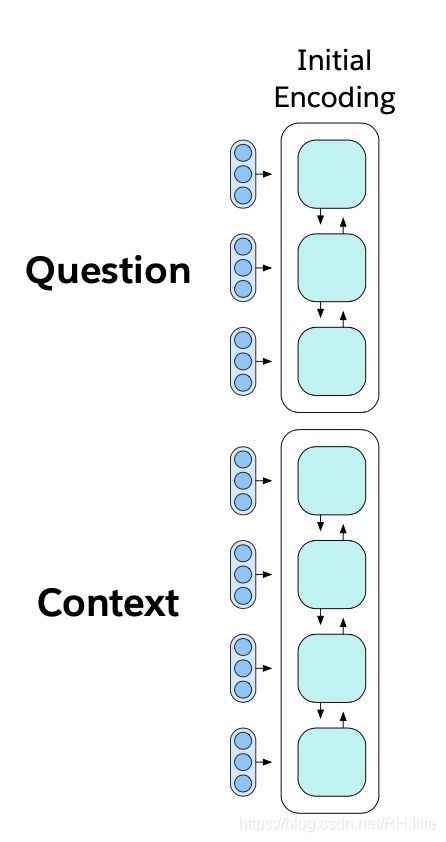
从一个序列到另一个序列的注意力总结,并通过跳过连接再次返回

分离BiLSTM以减少维数,两个变压器层,另一个BiLSTM

分离BiLSTM以减少维数,两个变压器层,另一个BiLSTM

自回归解码器使用固定的 GloVe 和字符 n-gram 嵌入,两个变压器层和一个LSTM层来参加编码器最后三层的输出
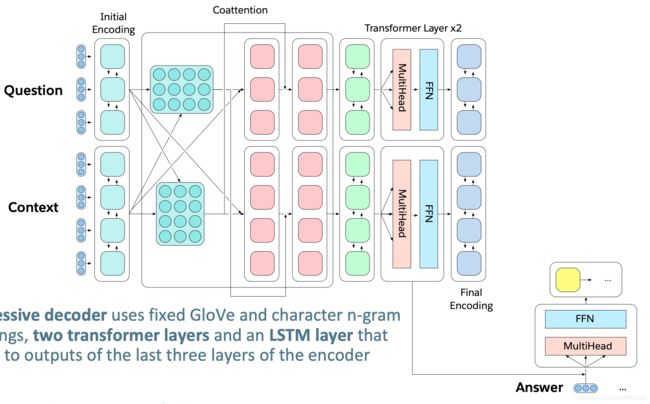
LSTM解码器状态用于计算上下文与问题中的被用作指针注意力分布问题

对上下文和问题的关注会影响两个开关: 1、gamma决定是复制还是从外部词汇表中选择。2、lambda决定是从上下文还是在问题中复制

(双向箭头表示双向的意思)
所用的数据集等:


(更关键的讨论如何制定成功的标准,不过每个社区的标准不一样,所以还是沿用了之前的~)
横向是相同数据集不同架构,纵向是不同数据集相同架构

(多任务时,可能某些任务会干扰其他任务,甚至彼此干扰,那么训练过程会发生严重的灾难性遗忘)
变压器层在单任务和多任务设置中产生效益
QA和SRL有很强的联系
指出问题是必要的
多任务处理有助于零风险
组合单任务模型与单任务多任务模型之间存在一定的差距
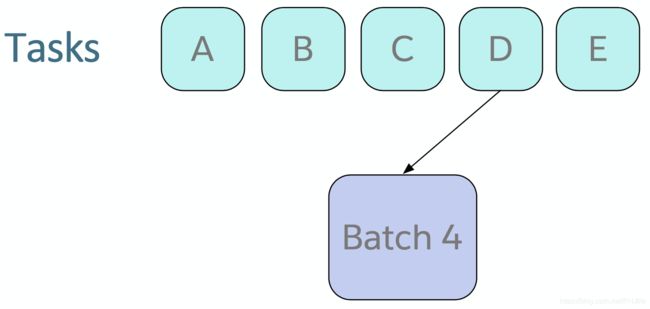
培训策略:全联合




培训策略:Anti-Curriculum Pre-training/反课程预训练?




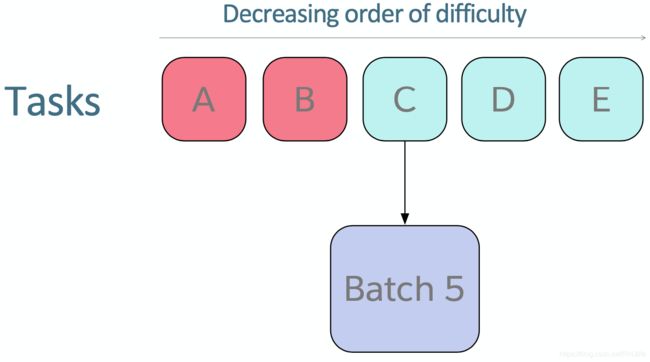
困难:在单任务设置中收敛多少次迭代
带红色的任务:预训练阶段包含的任务
QA 的 Anti-curriculum 反课程预训练改进了完全联合培训,但MT仍然很糟糕,如下图

缩小差距:最近的一些实验

MQAN指向哪里

答案从上下文或问题中正确的复制,没有混淆模型应该执行哪个任务或使用哪个输出空间
对decaNLP进行预培训可提高最终表现
 例如额外的IWSLT language pairs或者是新的类似NER的任务
例如额外的IWSLT language pairs或者是新的类似NER的任务
预训练MQAN的零触发域自适应:
在 Amazon and Yelp reviews 上获得了 80% 的 精确率
在 SNLI 上获得了 62% (参数微调的版本获得了 87% 的精确率,比使用随机初始化的高 2%)
零射击分类
问题指针使得我们可以处理问题的改变(例如,将标签转换为满意/支持和消极/悲伤/不支持)而无需任何额外的微调
使模型无需训练即可响应新任务,例如:

decaNLP:广义NLP的基准
为多个NLP任务训练单问题回答模型
解决方案:
- 更一般的语言理解
- 多任务学习
- 领域适应
- 迁移学习
- 权重分享,预训练,微调(对于NLP的ImageNet-CNN?)
- 零射击学习
相关工作(小部分)

